本文主要是介绍fastai机器学习课程-甲骨文 ORADC-AIG学习公开课(Lesson1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hi,这是我们第一次公开课。之所以有这个分享课程是因为大家太忙(懒),没有时间看fastai在线视频和笔记。而且视频和笔记都是英文的,大家也不想费脑子(懒)。所以本课程的目的就是把Jeremy老师的视频用中文再给大家讲一遍,另外把Hiromi小姐的笔记翻译加工一下分享给大家。
首先,下载并安装一些在本地可能用到的工具Anaconda(python3.7),git。
接下来可以clone fastai的repo到本地,比较大,慢慢烤……
https://github.com/fastai/fastai
直接git clone就可以,因为根据StackOverflow有人问的:

课程教授方式采用Jeremy老师的自上而下教学法——先有宏观概念(应用),然后再深入需要的细节。刚开始时把精力放在”能做什么“上,而不是抽象概念上。
学习方法:
1.参加Kaggle竞赛
2.创建Kaggle kernels
(假标题)随机森林:Blue Book for Bulldozer
Note| Kaggle
1. 薅Kaggle kernel羊毛
1.1 初始设定
创建Kernel;

添加数据;

启用GPU;
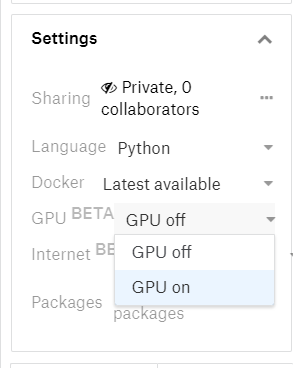
启用internet连接;
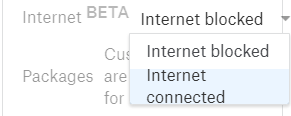
现在可以使用6个小时了(单次训练累计时间);
接下来可以上传导入ipynb文件,不过最好是自己敲一遍代码啦。

1.2 安装fastai库
!pip install fastai==0.7.0
!pip install torchtext==0.2.3
(对于fastai2018年的ML课程,要使用fastai 0.7版本。)接下来看看安装到哪里去了:
!pip show fastai
1.3 自动重新加载&导入(autoreload,%魔法命令)
%load_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.imports import *
from fastai.structured import *
from pandas_summary import DataFrameSummary
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
数据科学 ̸ = \not= ̸=软件工程——在建模阶段更加注重交互、迭代的探索过程的便捷性。
如果想知道display函数的用法,可以通过多种方式:
- 在一个cell中输入
display,然后shift+enter,就可以输出其具体package路径:
<function IPython.core.display.display> - 在cell中输入
?display,然后shift+enter,就可以输出其doc文档。 - 在cell中输入
??display,然后shift+enter,就可以输出其源代码。
2. 特征工程
2.1. 查看数据
在进行数据科学工作的时候,查看并理解数据是至关重要的。要确保理解数据的格式,如何排序的,都有哪些类型,等等。
df_raw = pd.read_csv(f'{PATH}Train.csv', low_memory=False, parse_dates=["saledate"])
parse_dates——转成日期格式low_memory=False——一次性读取csv中的所有数据,然后对字段的数据类型进行唯一的一次猜测。这样就不会导致同一字段的Mixed types问题了。但是一旦csv文件过大,就会内存溢出……pandas是处理结构化数据最重要的库。通常import为pd。
def display_all(df):with pd.option_context("display.max_rows", 1000): with pd.option_context("display.max_columns", 1000): display(df)
display_all(df_raw.tail().T)
截取了最后5行数据并且转置行列进行显示。

display_all(df_raw.describe(include='all').T) #统计数据

df_raw.SalePrice = np.log(df_raw.SalePrice) #这个只能做一次哦,因为会直接替换原来的值。
-
np——Numpy是个好东西,可以让我们像处理python变量一样去处理数组,矩阵,向量,高维张量。通常import为np。df_raw.SalePrice.head()

2.2 处理数据
- scikit-learn ——Python上最流行而且重要的机器学习库。虽然不是不是在每个方面都是最优秀的(比如XGBoost比Gradient Boosting Tree好),但是也很好了。
- RandomForestRegressor——用于预测连续变量的方法。
- RandomForestClassifier——用于预测分类变量的方法。
- 连续——值是用数字表示的,比如价格。
- 分类——值用特殊数字表示,比如邮编,或者是字符,比如“large”,“medium”,“small”。
m = RandomForestRegressor(n_jobs=-1)
# The following code is supposed to fail due to string values in the input data
m.fit(df_raw.drop('SalePrice', axis=1), df_raw.SalePrice)
基本上scikit-learn里的东西都时这个形式:
- 为机器学习模型创建一个对象实例。
- 调用
fit,把用于预测的独立变量和需要预测的依赖变量传进去。 axis=1表示去掉(某)列。- shift+tab 一次或者多次,可以出现类似?method的效果。
然后就报错了……因为创建模型必须用number类型的数据,有一个数据值是string型,这个必须转成number类型才可以。

关于日期数据的提取——year, month, quarter, day of month, day of week, week of year,是否是holiday? weekend? 是否下雨? 提取什么内容完全基于需要处理的业务。如果是预测啤酒的在某地的销售,就应该关注那里当天是否有足球比赛。从日期里发现发生了什么是特征工程一项很重要的工作。机器学习算法不会告诉你哪天有比赛,也不会告诉你比赛会影响啤酒销量。这些都需要行业经验,需要特征工程。
add_datepart函数用于从完整的日期时间数据里提取特定的日期项目,以构建分类数据。只要处理日期时间的数据,就应该考虑这个特征提取步骤。如果不把日期时间数据扩展成为这些额外的项目,就不能获取在这些时间粒度下的任何趋势/周期性的行为。
add_datepart(df_raw, 'saledate')
df_raw.saleYear.head()
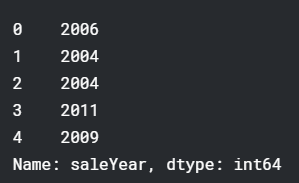
df_raw.saleYear和df_raw[‘saleYear’]有啥区别?赋值的时候,用方括号的形式,如果没有这个属性,就会先创建、再给其赋值。
Pandas有category数据类型的概念,但是默认不会自动转换。Fast.ai库提供了一个train_cats函数,可以自动把String类型转换成分类变量。基本流程是,首先创建一个integer column,然后存储一个从integer到String的映射。之所以train_cats命名为“train”,是因为其专为训练数据集使用。对于验证数据集和测试数据集,由于要保持其分类映射的一致性,要使用apply_cats。
train_cats(df_raw)
df_raw.UsageBand.cat.categories #查看分类值

更改一下分类值的顺序,让它们更有意义,对决策树算法来说也更容易理解。
df_raw.UsageBand.cat.set_categories(['High', 'Medium', 'Low'],ordered=True, inplace=True)
有一种分类变量叫做“序数词(ordinal)”。序数词变量会自带顺序属性(比如 “Low” < “Medium” < “High”)。随机森林对此不敏感,但是大家了解一下也是好的。
接下来要处理缺失数据。
display_all(df_raw.isnull().sum().sort_index()/len(df_raw))

读取和处理CSV文件需要不少时间,所以现在我们可以把他们保存成feather格式,这样在硬盘和内存中使用相同格式,将大大节省加载时间。这也是目前为止保存和读取文件的最快方式。feather格式也逐渐在很多技术中成为标准。
os.makedirs('tmp', exist_ok=True)
df_raw.to_feather('tmp/bulldozers-raw') #保存一下
df_raw = pd.read_feather('tmp/bulldozers-raw') #读取回来
接下来继续处理,我们要替换分类变量的值为它们的数据值,处理缺失值,还要把依赖变量(要预测的变量)切到单独的变量里去。
df, y, nas = proc_df(df_raw, 'SalePrice')
对于数值类型的,首先检查是不是null,如果是,就创建一个列名代后缀_na的新列,缺失值用1表示,其他用0(1:True,0:False)。然后将会用中位数替代缺失值。分类类型的变量不需要此处理,因为Pandas已经自动把它们设为-1了,fastai库会给分类类型code+1,所以就是从0开始了。
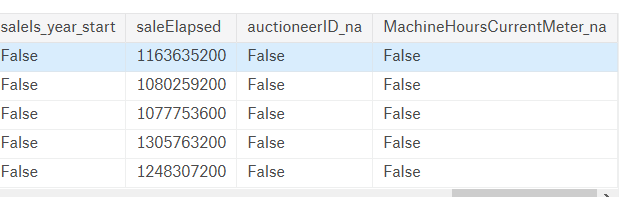
2.3 预处理
现在终于可以给提交数据到随机森林了!
m = RandomForestRegressor(n_jobs=-1) #为每个cpu创建一个单独的job
m.fit(df, y)
m.score(df,y)
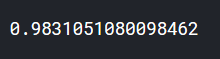
m.score返回的R2(决定系数),越接近1越好。
可能机器学习中最重要的观点就是要分开训练集和验证集。
如果不分割数据集,有可能:

最右侧的图的曲线机会完美的覆盖了所有的红叉,,但是不是最好的选择。为啥?如果再导入一些新数据,曲线就会慢慢像中间的图一样。
def split_vals(a,n): return a[:n].copy(), a[n:].copy()n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
#raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)X_train.shape, y_train.shape, X_valid.shape

2.4 基本模型
def rmse(x,y): return math.sqrt(((x-y)**2).mean())def print_score(m):res = [rmse(m.predict(X_train), y_train), rmse(m.predict(X_valid), y_valid),m.score(X_train, y_train), m.score(X_valid, y_valid)]if hasattr(m, 'oob_score_'): res.append(m.oob_score_)print(res)m = RandomForestRegressor(n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)

3.仍然没说随机森林
3.1 数据建模的两种方法
- 决策树集成(例如随机森林和梯度提升决策树),主要用于结构化数据。
- 学习随机梯度下降的多层神经网络(例如浅度、深度学习),主要用于非结构化数据。
3.2 评估指标 (机器学习中的一些COST函数的说明)
一个项目中的评估指标很重要。对于我们这个项目,kaggle中要求使用RMSLE去评估实际价格和预测价格之间的差距。所以我们要对价格取对数,然后应用RMSE得到最终需要的结果。
我们在处理数据时已经将原始价格替换为它的对数了。
3.3 两个Jeremy认为没用且很蠢的理论
维数灾难(curse of dimensionality)没有免费的午餐定理(no free lunch theorem)
这篇关于fastai机器学习课程-甲骨文 ORADC-AIG学习公开课(Lesson1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








