本文主要是介绍思码逸企业版 4.0 特性之三:研发效能数据的智能化分析与解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
建立研发效能体系,数据的收集与清理并建立指标体系只是第一步,如果不针对这些指标采集到的数据进行分析,那就无法做到研发效能度量闭环,那么指标体系也就毫无意义。所以研发效能分析在整个研发效能改进闭环中占据非常重要的一环。
对于部分研发管理者来讲,有了数据不一定意味着就能很好地找到对应的问题,并快速确定后续改进策略,其背后主要的原因可能有以下几点:
-
数据看板只简单罗列,无法下钻分析
-
数据看板不容易理解
-
不太了解研发效能领域知识,不知道如何分析数据
在之前发布的两篇文章中,我们分别讲解思码逸企业版 4.0 是如何支持 DevOps 全工具链数据接入,以及如何解决研发数据的治理。到此,我们已经利用思码逸 4.0 的完成了数据接入与清理,以及指标体系匹配的工作,接下来我们要如何去分析数据?利用数据结果来规划后续的研发效能改进策略呢?
本篇我们将介绍的就是思码逸 4.0 的特性之一:数据看板及专家分析系统。它可以帮助研发管理者,透过现象看本质,基于数据下钻发现项目效率瓶颈、代码质量现状,以及团队开发的贡献均衡度等核心信息。为研发管理者制定后续研发效能提升策略提供数据依据。
数据看板与数据洞察
首先针对可能还“不太了解研发效能领域知识,不知道如何分析数据”的用户,思码逸平台的数据看板 GQM 方法论建立了数据看板,GQM 代表 Goal-Question-Metric(目标-问题-指标),是一套构建软件研发效能度量的系统方法。简单来说,GQM 方法强调面向清晰具体的目标,自上而下拆解,通过问题建立研发的度量模型 + 基于量化数据分析来回答问题,自下而上解读并达成目标。GQM 方法提出后,经过了不断的丰富和发展,早期即应用在 NASA、惠普、普华永道、斯伦贝谢、西门子、爱立信、飞利浦、博世、戴姆勒-克莱斯勒、安联、宝洁等各行业先进企业。更多解读可以查看《GQM 概述:构建研发效能度量体系的根本方法》。思码逸 4.0 版本中的数据看板就是以该方法论为基础,围绕具体的研发管理场景的研发效能数据看板。所以任何用户在了解 GQM 方法后,都能具备分析研发效能数据的能力。
其次,针对“数据看板只简单罗列,无法下钻分析”的问题。相比其它大多数『数据看板』,思码逸平台的数据看板的区别在于数据不再是简单罗列、让人看得一头雾水,而是用来回答具体场景、具体度量目标下的某个具体问题。例如,项目质量、项目交付效率、项目人效,我们此前也针对这三个场景中的数据如何解读,进行过详细的剖析,可点击上述文字超链阅读对应文章。
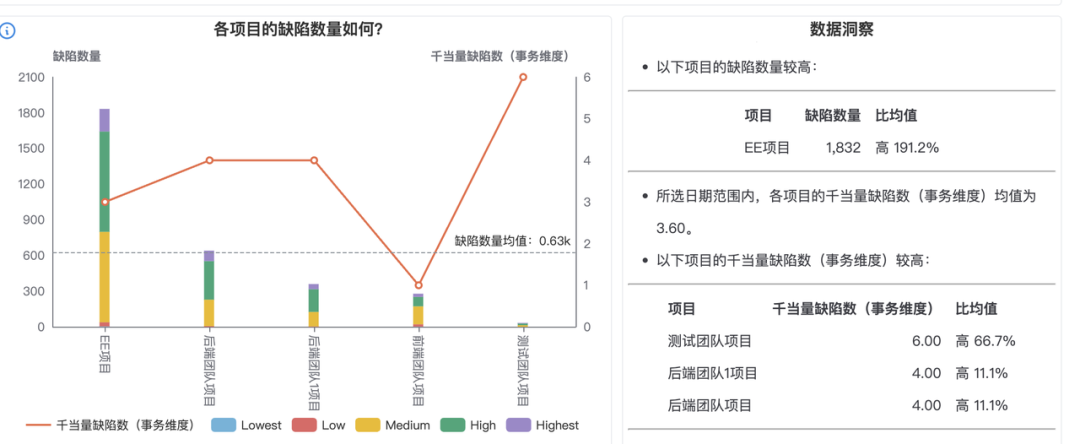
在这里,我们以项目质量为例,思码逸从项目管理工具中提取缺陷/事故数据,直观对比多个项目的缺陷/事故数量和严重等级占比,并以“千当量缺陷数”作为补充,帮助管理者确定重点需要关注的项目。以下图为例,图中的数据是 Demo 环境中的模拟数据,其中横坐标列出了当前产生了代码当量的所有项目,纵坐标分别代表了:
-
缺陷数量:在所选日期范围内,各项目产生的缺陷数量。
-
千当量缺陷数:每千当量产生的的缺陷数。计算公式为:缺陷数量 / 项目所有事务产生的总当量 * 1000
而在图表的右侧,思码逸平台会根据当前的数据提供数据洞察与解读,帮助管理者提炼出需要关注的指标异常,例如可以看到 EE 项目当前的代码当量较高且缺陷数量最多,可能是当前研发团队主力推进的项目,而在千当量缺陷数据中“测试团队项目”的代码当量少但存在高风险的缺陷,说明该项目可能遇到了卡点,值得管理者进一步与团队沟通项目问题,以保证该项目的交付。
思码逸平台还支持对每个项目数据进行下钻分析。在刚刚的数据图中,只要点击项目的柱状图,就可以进一步查看该项目每个步长的缺陷数量趋势、该项目各代码库的缺陷数据分布,以及该项目的缺陷收敛情况。
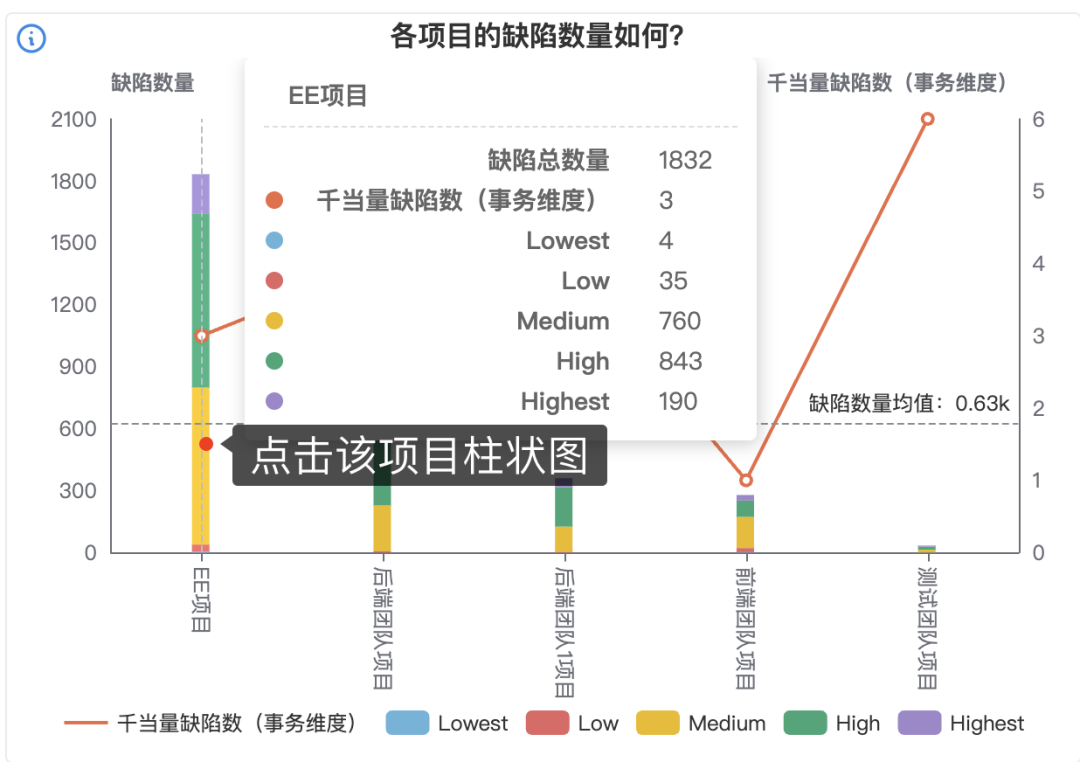
点击上图中的“EE 项目”后,即可下钻分析该项目质量相关数据,如下面三张图所示。
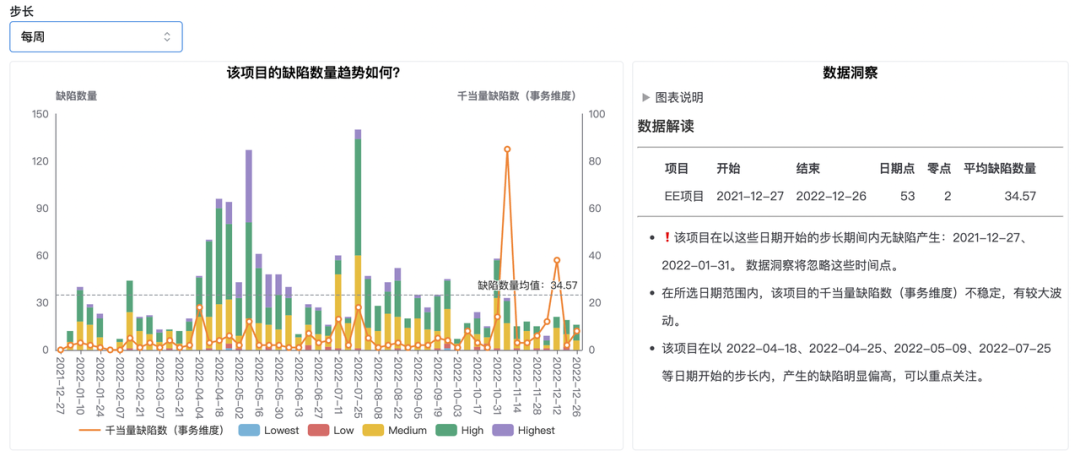
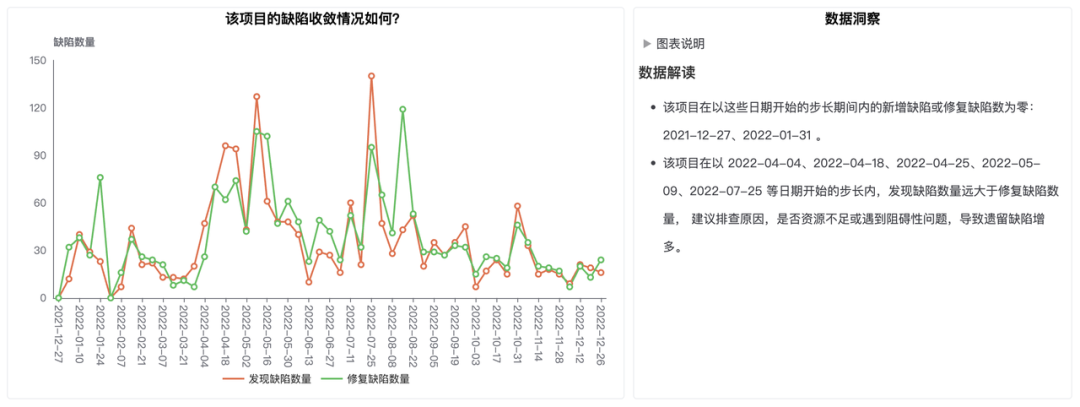
管理者还可以针对某一个缺陷数量较高的日期,继续下钻查看当天出现的缺陷列表与详情,包括缺陷 ID、缺陷等级、经办人等,精准定位影响当前项目质量的核心问题。

以上我们只是以项目缺陷相关的数据举例,在思码逸数据看板中还可以围绕项目交付效率、开发人员贡献均衡度等维度展开相关的数据报表,并支持下钻分析。
你也想试试?
思码逸企业版 4.0 现已上线。如果你正苦于研发数据的归集与处理、指标体系的建设,欢迎扫码申请免费体验思码逸企业版。

这篇关于思码逸企业版 4.0 特性之三:研发效能数据的智能化分析与解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





