本文主要是介绍【数据分析之Numpy】Numpy中复制函数numpy.repeat()与numpy.tile()的使用方法及区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
numpy.repeat()与numpy.tile()都是Numpy库中的复制函数,用于将数组中的元素重复指定的次数。
numpy.repeat()函数接受三个参数:要重复的数组、重复的次数和重复的轴。
numpy.tile()函数接受两个参数:要重复的数组和重复的次数。
二、基本语法
1、numpy.repeat(a, repeats, axis=None)
a为带操作的数组
repeats为复制的次数
axis为重复操作会沿着哪个轴进行, axis=0表示沿着行方向, axis=1表示沿着列方向。
2、numpy.tile(A, reps)
A为带操作的数组
reps是一个元组,指定了每个维度上的重复次数。
三、使用方法
1、numpy.repeat()
(1). 将数组中的每个元素重复3次
import numpy as npa = np.array([1,2,3])b = np.repeat(a, 3)print(b)
(2). 将数组中的每个元素沿行方向每一行重复3次
a = np.array([[1,2,3], [4,5,6]])b = np.repeat(a, 3, axis=0)print(b)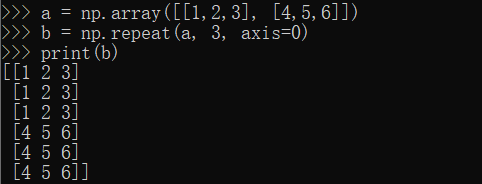
注意:如果这里a是一维数组,那axis只能为0
(3). 将数组中的每个元素沿列方向每一列重复3次
a = np.array([[1,2,3], [4,5,6]])b = np.repeat(a, 3, axis=1)print(b)
2、numpy.tile(A)
(1). 将数组中的每个元素重复3次
import numpy as npa = np.array([1,2,3])b = np.tile(a, 3)print(b)
(2). 将数组中的每个元素沿沿着第一个轴重复2次,沿着第二个轴重复3次,
1)a为一维数组
a = np.array([1,2,3])b = np.tile(a, (2, 3))print(b) # 数组维度改变
2)a为多维数组
a = np.array([[1,2,3], [4,5,6]])b = np.tile(a, (2, 3))print(b)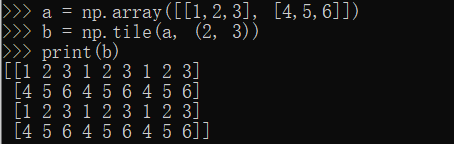
四、区别
np.repeat()和np.tile()在功能上有些相似,但它们之间存在一些重要的区别。
1、行为上
对于一维数组,np.repeat()会重复数组中的元素,而np.tile()则会复制整个数组。这意味着np.repeat()仅在数组的每个元素上应用重复操作,而np.tile()则在整个数组上应用复制操作。
对于非一维数组,np.repeat()仅在最后一个轴上重复,而np.tile()会在所有轴上复制数组。
2、性能上
对于大数组,np.tile()通常比np.repeat()更快,因为它可以更有效地利用缓存。
np.repeat()不会预先分配输出数组的内存,而是在运行时动态地创建输出数组。
np.tile()会预先分配输出数组的内存。
3、参数
np.repeat()三个参数:要重复的数组、重复的次数和它沿着数组的哪个轴重复元素。
np.tile()两个参数(可以看为三个参数):要复制的数组和复制的次数(它沿着所有轴复制数组)。
4、原地操作
np.repeat()不会原地操作(即不会更改原始数组),而np.tile()则可以进行原地操作。
这篇关于【数据分析之Numpy】Numpy中复制函数numpy.repeat()与numpy.tile()的使用方法及区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




