本文主要是介绍数据仓库与数据挖掘c5-c7基础知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
chapter5 分类
内容
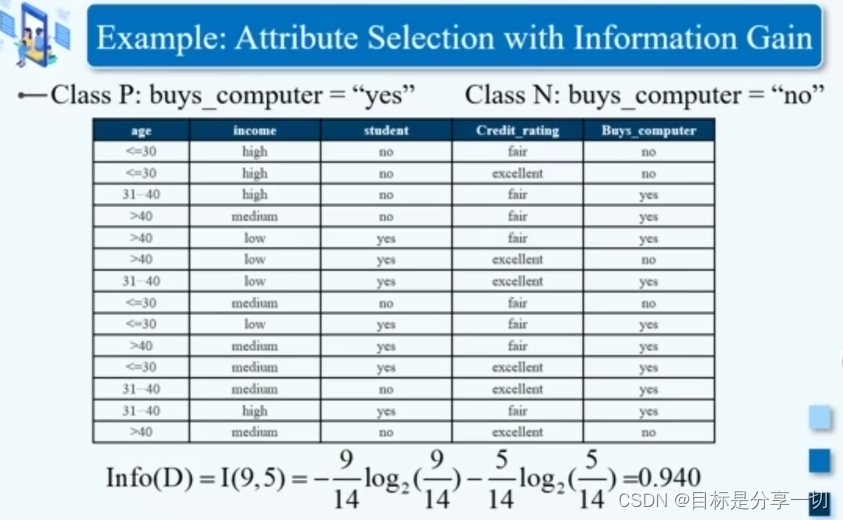
| 分类的基本概念 | | 分类 | | 数据对象 | 元组(x,y) | | X | 属性集合 | | Y | 类标签 | | 任务 | 基于有标签的数据,学习一个分类模型,通过这个分类模型,可以把一组属性x映射到一个特定的类别y上 | | 类别y | 提前设定好的--如:学生,老师 |
| | 有监督学习 | | Phase1 | 用有标记的数据对分类器进行训练,得到训练好的分类器 | | Phase2 | 用训练好的分类器对没有标记的数据进行分类预测 |

训练过程中,分类器在类标签的引导下进行学习,所以是有监督学习 | | 预测问题:分类vs数值预测 | | 分类【也是预测问题】 | 使用给定的有标记的数据去训练构造一个模型,基于分类模型对没有标记的数据进行预测【有类别的,是类别类型的属性,离散的】 | | 数值预测 | 基于给定的数据训练数值预测模型,再利用模型对给定的数据进行预测【预测的数据类型是连续的,如房价】 | | Vs | |
| | 分类过程 | | 模型构建 | | 训练集 | 有标记的数据;用于训练分类器 | | 分类器模型 | 决策树、基于规则的分类器、数学公式、其他形式 |
| | 模型验证与检测 | | 测试集 | 无标记的数据;独立于训练集 | | 准确率 | 预测对象中预测正确的数目占全体数据对象的比例 | | 模型的验证 | 利用测试集,对比多个分类器,选择合适的分类器 |
|
| | 分类技术 | | 基础分类器 | 决策树模型、基于规则的方法、基于深度学习和神经网络的方法、naive贝叶斯方法和贝叶斯信念网络、支持向量机 | | 集成分类器 | | 基础分类器的基础上,通过集成策略,将多个分类器集成构建新的分类器 | | 提升、袋装、随机森林 |
|
|
|
| 决策树分类器 | | 决策树基本概念 | | 基础概念 | | 非终结节点 | 属性测试条件——把落入节点的测试集划分为两个或多个子集 | | 根节点 | 没有入边,只有两条或多条出边 | | 中间节点 | 有一条入边,有两条或多条出边 |
|
| | 终结节点 | 代表类的数值——把落入节点的所有数据对象的类别等于叶子节点的值 | |
| |
| | 应用模型 | |
| | hunt算法 | | 贪心策略 | 使用局部最优策略,选择比较合适的属性测试条件,从而完成决策树的构建 | | 基本架构 | | 递归、自顶向下、分而自治 | | | 用Dt代表落入到一个节点t上的数据对象集 | | 如果Dt中所有数据对象的类都是一致的 | 当前的t是叶子节点,将其标上所有数据对象的类标签 | | 若Dt中数据对象有多个类别 | 当前的t是中间节点,需要设定一个合理属性测试条件,将Dt划分为几个更小的子集。对每个子集迭代循环以上步骤,直到满足中介条件 |
| | 停止划分的条件 | | 落入到这个节点上的所有数据对象的类标签是一致的 | | 无属性供我们选择去构造属性测试条件 | | 数据集中所有数据对象都已被使用完 |
| | Eg | 
|
| | 确定属性测试条件 | | 标称属性 | | 多路划分 | 根据标称属性的取值,将集合划分为若干个小的子集 | | 二路划分 | |
| | 连续属性 | | | 如何实现最佳划分 | | 贪心策略 | 评估属性测试条件分裂之后各个节点的纯度,纯度越高越理想 | | 节点的纯度 | 倾斜性--如果一个节点中所有的数据对象都是一个类别那么节点的纯度最高

| | 设定评估节点纯度的方法来判断属性测试条件是否合理 | |
|
|
| | 评估属性测试条件的方法 | | 信息增益 | | 熵 | | 对一个随机变量不确定性的度量标准 | | 熵值越大,这个变量的不确定性越高; |
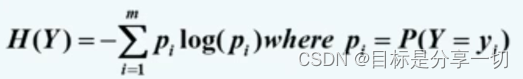
log的底是m 
| | 条件熵 | 在知道一个随机变量x的情况下,熵Y的值是多少

H(Y)可以理解为我们要弄清楚Y所需要的信息量 H(Y|X)可以理解为在我们知道随机变量X的信息的条件下,再要弄清楚Y所需要的信息量 | | Eg | 
I(,)中数的总和m是表示该随机变量包含的数据对象的数目还是就是2??【就是2】 | | 信息增益 | | H(Y)-H(Y|X) | 随机变量X对于弄清楚Y这个随机变量取值的贡献 | | 使用情况 | 我们对属性测试条件的选择是选择具有最大的信息增益的属性 | | | 用于ID3/C4.5 | | ID3——不确定性逐渐减少--信息增益

| | 缺点 | 选择根节点和内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息。
只能对描述属性为离散型属性的数据集构造决策树【c4.5能对连续型属性值构造决策树】 | | 先算总的信息量 | 
| | 在天气、气温、湿度、风四个指标中选一个根节点--选择信息增益最大的天气作为根节点 | 分别计算各自的信息熵 确定值点是0
加权求和

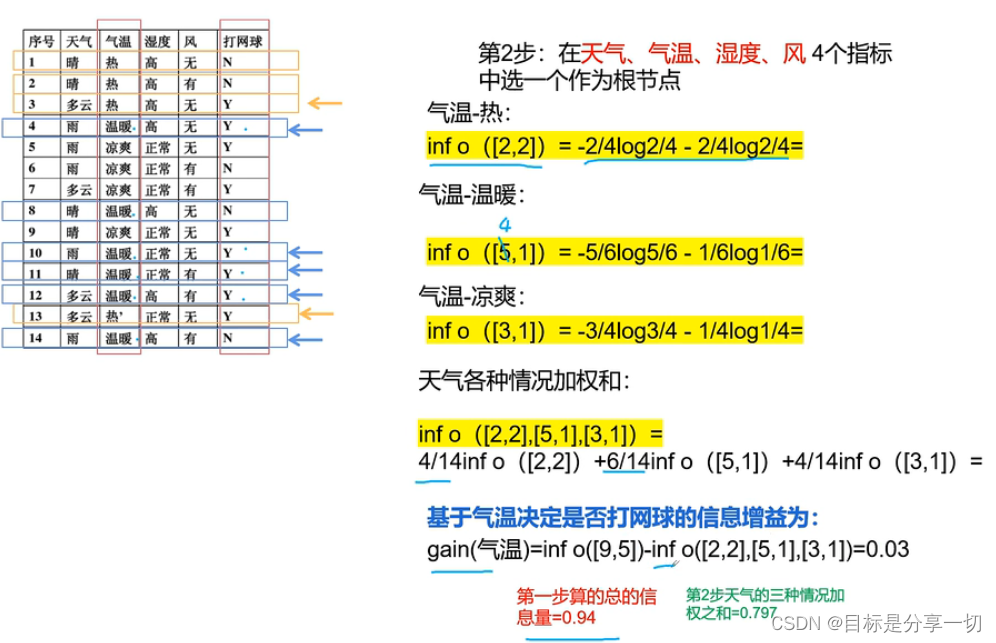
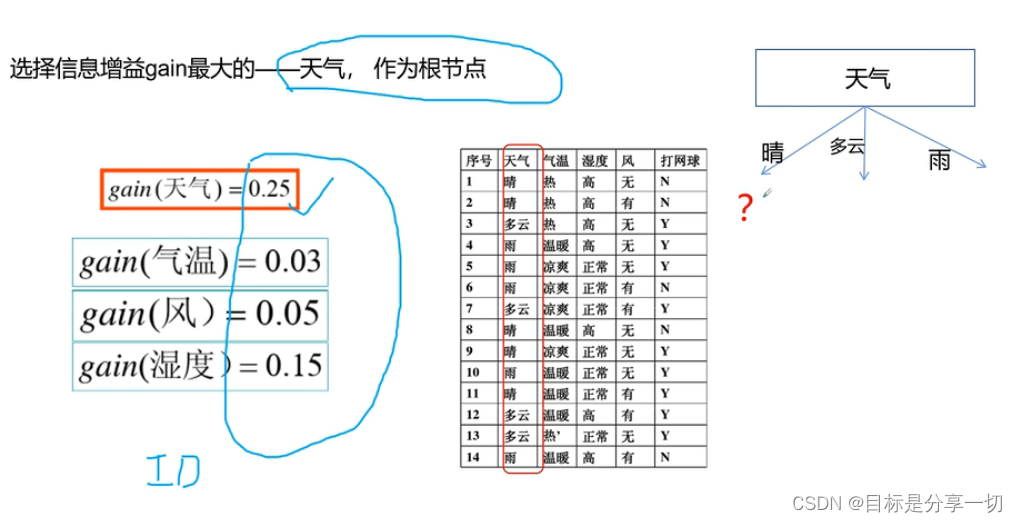
| | 下一步 | 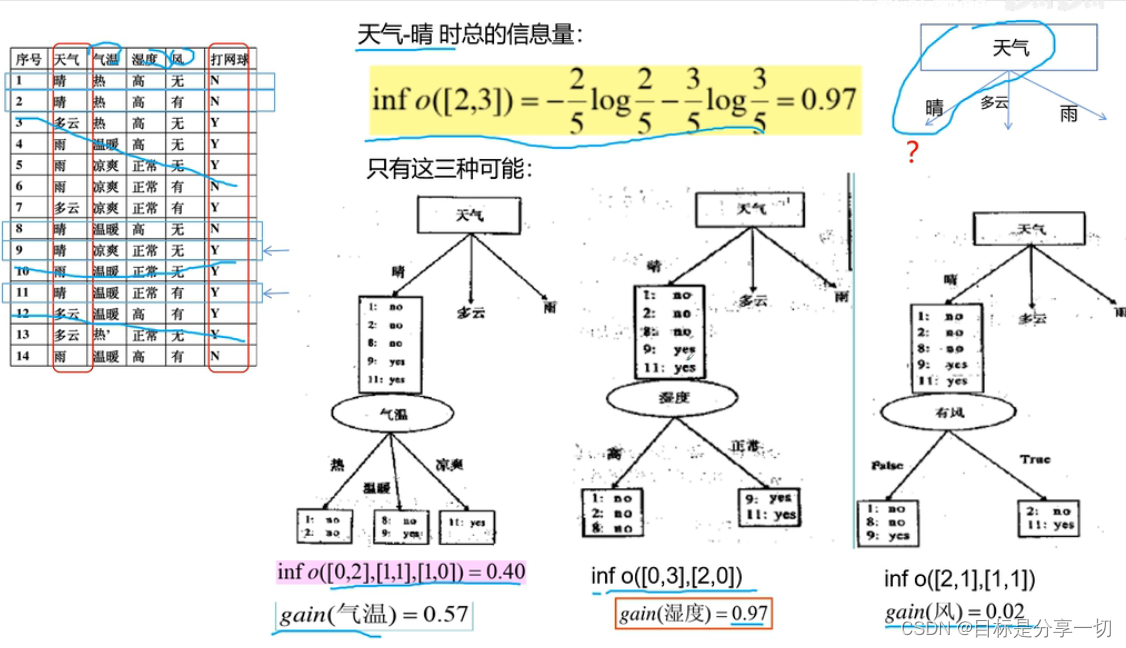

| | 最终决策树 | 
|
| | 解释 | | 假设数据集为D,pi代表每个类别出现的概率也就是Ci出现的概率 | | | 计算类标签的熵 | 
2?? | | 计算每个属性的条件熵 | 
知道属性A的条件下,弄清D的类标签需要的信息量,j是A的可能取值 | | 属性A的信息增益 | 
在知道属性A后对认识类标签所需要的贡献 | | Eg | I(,)是根据类标签来的

|
| | 如何处理连续属性 | | 离散化 | 连续属性->标称属性 | | 最佳分裂点 | 
候选分裂点 根据每个分裂点对属性一分为二,计算在这样的属性测试条件的信息增益,最佳的分裂值具有最大的信息增益 |
| | 缺点--ID3 | 倾向于选择属性取值比较多的属性
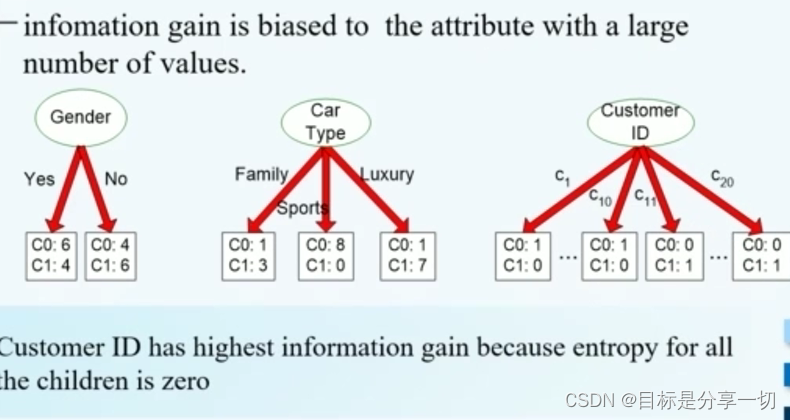
id纯度最大 |
|
| | 信息增益率 | | 对信息增益进行规范化 | 
如果一个属性,取值越多,可能得到的信息增益越大,同理,熵也会比较大 | | | 
splitinfo是熵,不是条件熵 | | C4.5--信息增益比

| | 相较于信息增益,增加了分裂信息和信息增益比 | splitinfo和label无关了,感觉是为什么会分开【很像针对label算的info】


| | | |
|
| | 基尼指标 | | Cart【二叉树】
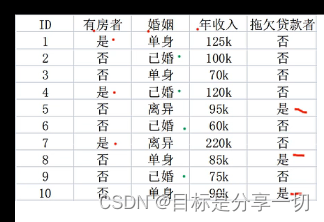
| | 确定根节点 | | 有房者 | 
| | 婚姻 | 本来有三类:已婚、单身、离异,先把后两者作为一类 
| | 年收入 | 
|
| | 婚姻中的离异、单身类有六条数据,继续计算下一个节点 | 
| | 二叉树 | 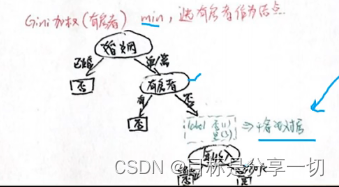
|
| | 基尼指标越大越不纯,不确定性越高 | 
| | 在A属性作用下划分为两个子集 | 
| | 例子 | 
得到基尼贡献率 | | 多路划分一般比二路划分好 | 
| | 连续属性 | | 选择比较好的分裂值 | 
| | 排序后找class发生变化的地方作为候选分裂点,从而减少候选分裂点 | 
|
|
| | 比较 | | 信息增益 | 选择取值多的属性 | | 信息增益率 | 产生不平衡的分裂--子集规模差异性大 | | 基尼指标 | 选择取值多的属性;产生平衡的分裂 |
|
| | 过拟合与树的剪枝 | |
|
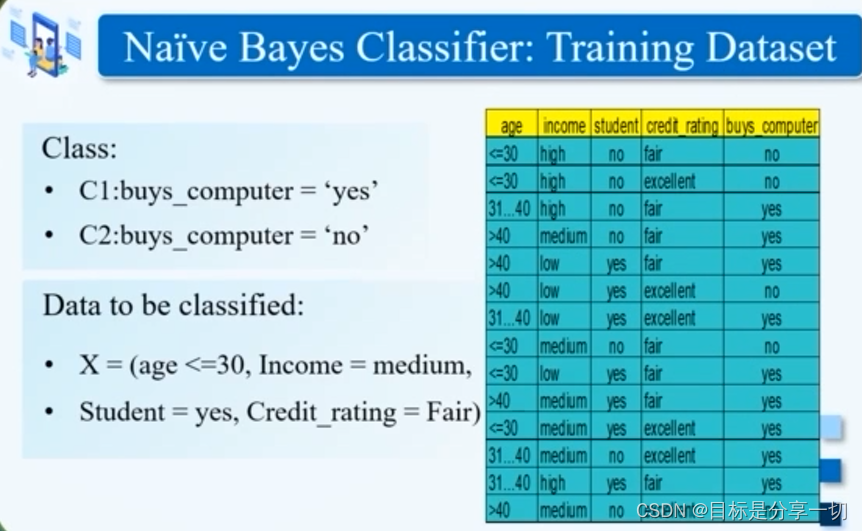
| 贝叶斯分类器 | | 基于统计的分类器 | 坚实的数学基础-贝叶斯定理 | | 朴素 | 各个样本特征彼此独立 | | Eg | | | 任务 | | 把每一个属性,每一个类都看作是随机变量 | | | 求解一个值使得已知x1,x2…Y=y概率最大 
| | | 分类问题->概率求解问题【使用贝叶斯定理】 
| | | 例子 


类别类型的属性可以计数得到: 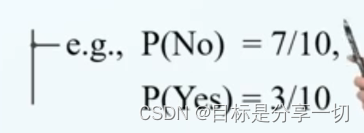
| | | 连续类型的数据:
模拟这个数据符合某种分布 
eg: 
| | | Eg'


| |
| | 问题 | 要求每一个属性概率非零 
拉普拉斯纠正:每一个类别都加一个数据对象

避免条件概率为0导致无法判断 | | 优缺点 | 缺点:依赖于属性独立的假设 | | 贝叶斯信念网络 | |
|
| 集成 | | 集成 | 首先创建多个基础分类器,然后将多个基础分类器以某种策略组合在一起,对未标记数据进行分类,提高单个的性能 | | 示意图 | 
| | 必要条件 | | 构成的所有基础分类器必须彼此独立 | | | 所有基础分类器的性能必须比随机猜测要好,要求错误率低于0.5 | 
基础分类器的错误率大于0.5时,集成分类器远大于0.5 |
| | 为何能提升性能 | | 对不稳定的基础分类器的集成效果较好 | | 不稳定的分类器 | 具有比较高的方差 | | 偏差 | 预测的平均值和目标之间的差异 | | 方差 | 各个分类器预测的平均值和每一个基础分类器之间的差距【不稳定易受干扰】 | | 集成可以减少方差 | |
|
| | 常用的集成技术 | | bagging袋装 | | | 从训练集中采用抽样的方式得到不同的抽样子集,根据每一个抽样子集得到基础的分类器,并行 | | 步骤 | | 训练 | 从训练集中采用有放回【彼此独立】的抽样得到一个训练集,用这个抽样集去训练我们的分类器,得到一个基础的分类器,重复以上过程,得到若干个分类器,最后利用这样的分类器进行组合,对我们的未标记数据进行分类 | | 分类 | | 首先用基础分类器对未标记数据进行分类 | | | 然后将多个分类器的预测结果组合 | 往往采用最大投票法--在多个基础分类器中出现比较多的结果作为预测结果 |
|
| | Eg | 
|
| | boosting提升 | | | 通过调整training set中数据对象的权重,在此基础上抽样得到不同的训练集,再用每一个训练集去得到基础的分类器,后一个依赖前一个,是串行。 | | 原理 | | 串行 | 下一次的权重由上一次的分类结果得到 | | | 假设得到一个分类器Mi,利用Mi对我们预测数据集中所有元素进行分类,据其真实结果与预测结果更新权重 | | 更新权重原则 | 如果一个对象被分类错误,那么这个数据对象的权重就会变大;若一个对象被正确分类,那么这个数据对象的权重就会变小。 | | | 得到新的权重后,据其抽样得到新的数据集,用新的数据集训练模型Mi+1 | | | 组合所有模型进行分类,组合时考虑每一个分类器的权重【和分类性能(error rate)相关】

| | Adaboost | 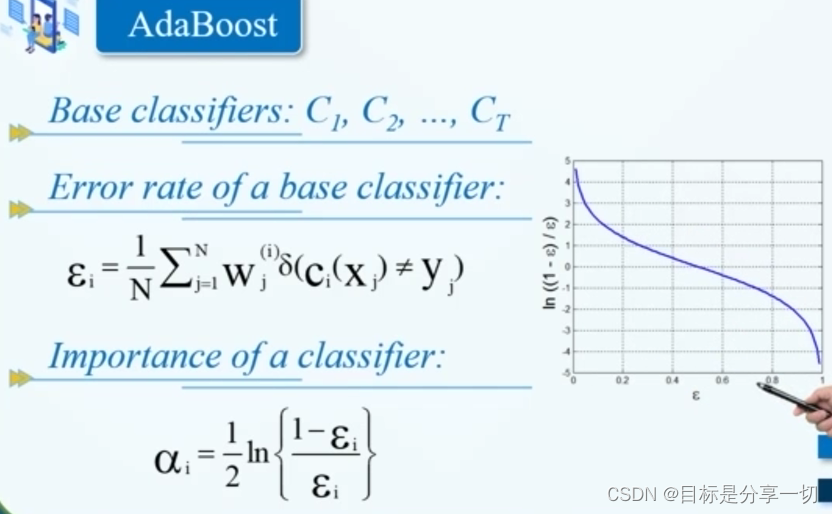
| | 数据权重调整 | 
若模型错误率高于0.5,所有数据对象的权重恢复为初始权重1/n | | Eg | 

|
|
| | 随机森林 | | 基于bagging | | Data bagging | 通过有放回的抽样产生不同的训练集的子集用于构建决策树 | | Feature bagging | 通过有放回的抽样 |
| | 构成的多个决策树组成随机森林 | |
|
|
|
| 不平衡分类器 | | 类别分布平衡 | 各个类别的数量差不多 | | 策略 | | | 如果把普通的分类器运用到不平衡的训练集上,分类效果无法被保证 | | 策略 | | oversampling | 对正事例进行采样,用于补充正事例的数量 | | Undersampling | 对负事例进行采样,去掉,从而达到正负平衡 | | 阈值移动 | 调节阈值,使得为正的示例会比较多,如0.5->0.3 | | 集成 | 前几种方法集成 |
|
|
|
| 模型评估和选择 | | 分类器的评估度量 | | 构建分类器的混淆矩阵+度量标准 | 
| Eg | 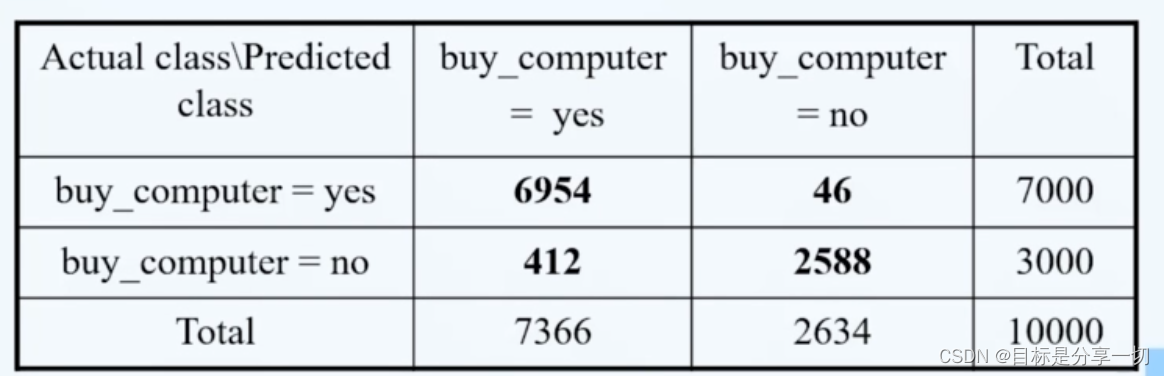
行为真实,列为预测 | | 正确率与errorrate | 

| | 灵敏性与特效性 | 
正事例、负示例被正确分类 | | 精度与召回率 | 
| | F measure | 更看重精度还是召回率

F1 measure:同等重要 | | Eg | 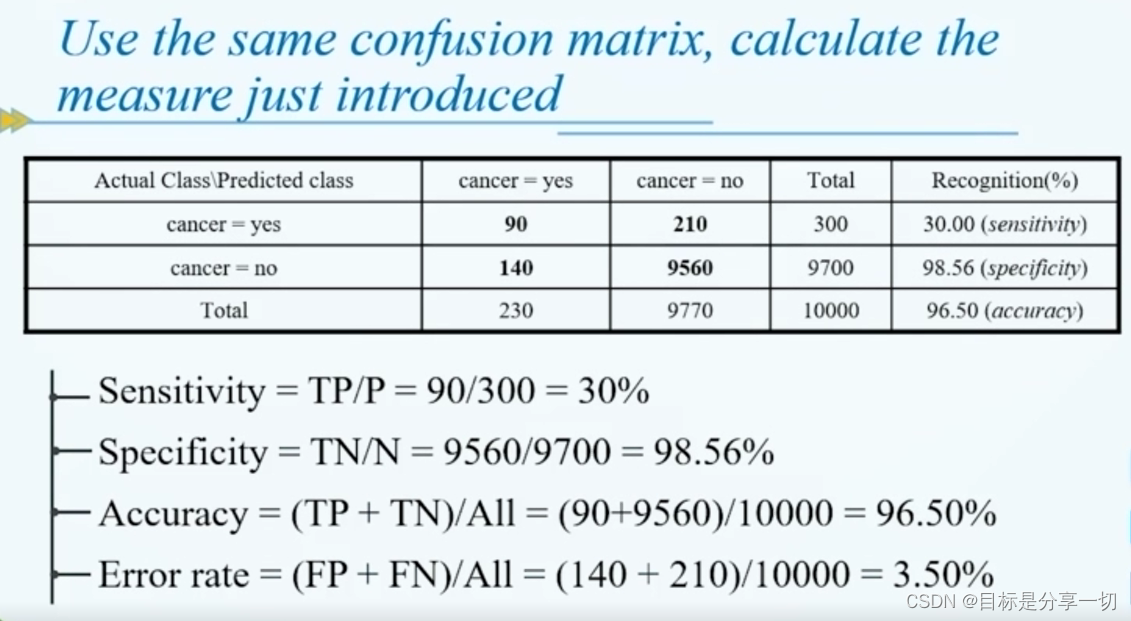

|
|
| | 评估框架 | | 留余法 | | 数据2/3作为训练集,1/3作为测试集,重复得到多个训练集和测试集,利用每个训练好的分类器的精度作为每一轮的精度,然后把每一轮精度都加起来取平均得到分类器最终精度【做三次】 | | 
|
| | 交叉验证法 | | k设为10
一般采用十折交叉验证 | | 有放回采样,将采样后的数据分为k个部分,然后把每一次从这k个部分中取一部分作为测试集,其余作为训练集,得到一个分类器,计算精度,依次把所有精度加起来取平均 | | | 余一法:每次只取一块作为测试集,其余作为训练集
留余法是特殊的交叉验证法

每一个fold得到一个分类器,3折有3个分类器 | |
|
| | roc曲线 | | | 
真的正示例率与假的正事例率之间的平衡关系

| | | 同等的fpr,希望tpr越高越好,曲线下面积代表分类器性能
| | Auc | roc曲线下的面积
auc越大越好 | | 如何绘制 | | 通过调节分类阈值来得到分类器的多个tpr和fpr | | 对测试集的每一个事例计算它的分数 | 分数:每一个事例被判断为正事例概率 | | rank这些分数 | | | 依次选择每一个分数作为阈值来判断事例的类别 | | | 从而得到多个roc上的点 | | | 连接并平滑 | |
| | 计算分数的方法 | | 朴素的贝叶斯分类器 | 每一个分类器为正事例的概率和为负示例的概率 | | | |
| | Eg | 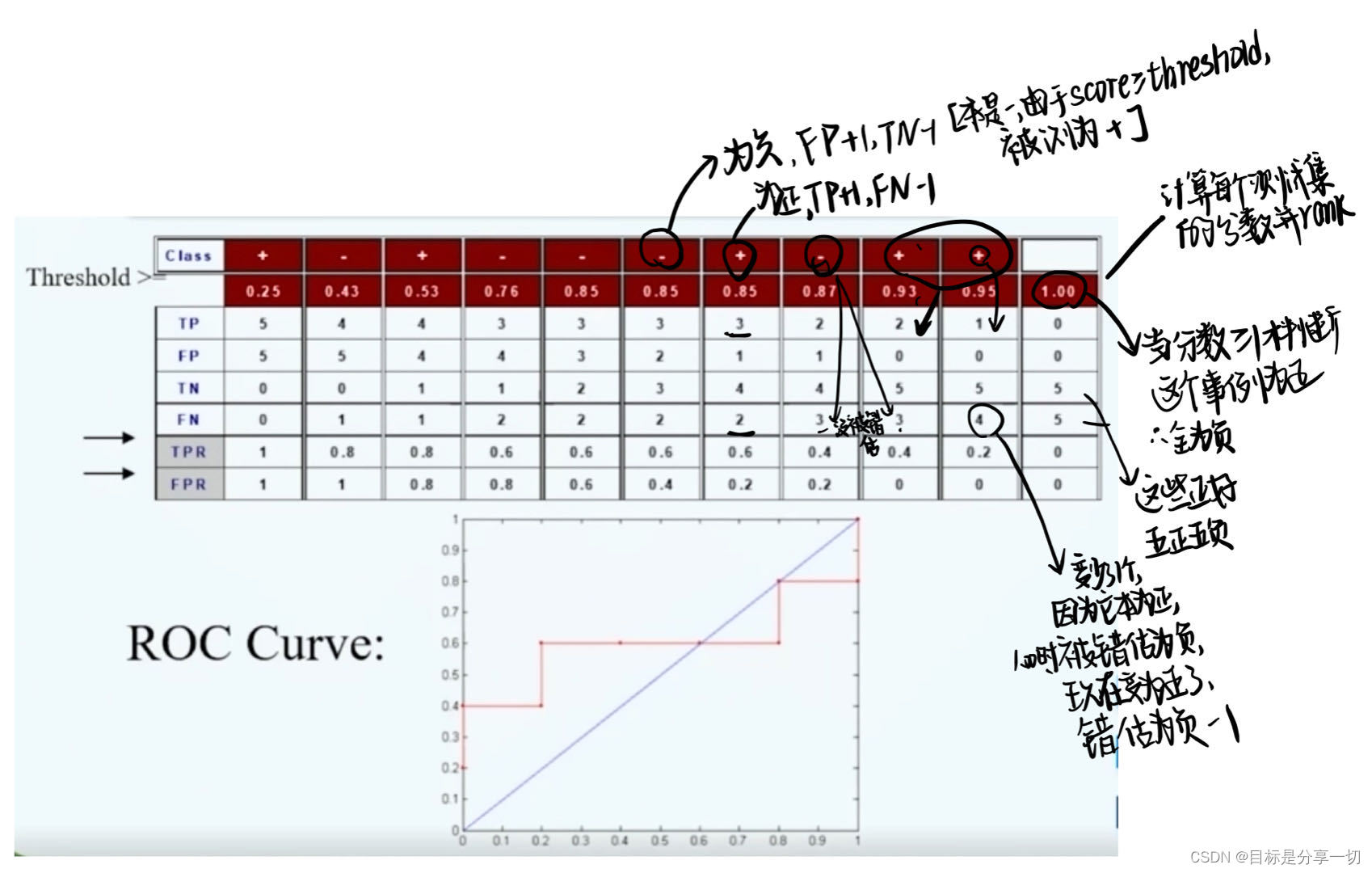
|
|
|
| | 其余性质 | 速率、鲁棒性、可扩展性【更新、大数据集】、可解释性 |
|
mooc题目
| 单选(2分)下面哪一项关于CART的说法是错误的 A.CART使用的分裂准则是Gini系数 B.分类回归树CART是一种典型的二叉决策树 C.CART输出变量只能是离散型 D.CART用“成本复杂性”标准(cost-complexity pruning) 来剪枝。 | CART的输入和输出变量可以是离散型和连续型,
cart如果输出变量是 「离散」 的,对应的就是 「分类」 问题。 如果输出变量是 「连续」 的,对应的就是 「回归」 问题 C4.5的输出变量只能是离散型 C4.5算法:可为多叉树,输出变量只能是分类型,能够处理连续型和离散型属性数据
id3离散型 |
| 单选(2分) 假定你现在训练了一个线性SVM并推断出这个模型出现了欠拟合现象。在下一次训练时,应该采取下列什么措施? A.减少特征 B.增加数据点 C.增加特征 D.减少数据点 | 增加特征 |
| 单选(2分) 以下哪项关于决策树的说法是错误的 A.子树可能在决策树中重复多次 B.余属性不会对决策树的准确率造成不利的影响 C.决策树算法对于噪声的干扰非常敏感 D.寻找最佳决策树是NP完全问题 | c |
| 单选(2分) 通过聚集多个分类器的预测来提高分类准确率的技术称为 () A.投票(voting) B。合并(combination) C.组合(ensemble) D,聚集(aggregate) | Ensemble… |
| 单选(2分) 以下哪些算法是基于规则的分类器 A.ANN B.KNN C.Naive Bayes D.C4 | D。基于规则的分类器有决策树、随机森林、Aprior。 1.决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。 2.在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 3.在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库。 D选项:C4.5算法是一个分类决策树算法。 |
| 判断(2分) KNN算法不仅可以用于分类,还可以用于回归 A.X B.√ | |
| 判断(2分) KNN算法是一种典型的消极学习器 对… | | 消极学习器 | 目标是通过学习不适合或错误的模型来识别和剔除负面样本,以提高模型的性能。消极学习器通常与正常学习器一起使用,用于筛选和过滤训练集中的负面样本。 | | | |
|
| 判断(2分)在决策树中,随着树中结点数变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题。 | 过拟合:训练误差在降低,检验误差在增大
过拟合解决方法:增加数据量、正规化


|
chapter6
内容
| 基本概念 | | 簇 | | 一组数据对象的集合 | 簇内部相似 | | | 不同簇之间的数据对象相异 | | 高质量的簇具备两个特征: | 高度的簇内相似性;簇间具有比较低的相似性 |
| | 聚类分析 | | aka聚类、数据分割 | 给定一组数据集合,根据数据的特性,将这组数据集划分为若干个组,这些组内的数据对象是相似的,再聚类分析中,我们主要是依赖数据对象和数据对象之间的相似性进行划分,所以相似性度量很重要。 | | 无监督学习 | 类是预先没有定义的;而分类的类别是预先定义好的,含义是明确的。聚类的任务是将数据划分为不同的簇,属于数据挖掘中的描述性任务,而分类需要依赖有标签的训练数据构建分类模型,然后利用分类模型将对没有标记的数据对象进行预测,属于数据挖掘中的预测性任务。 |
| | 簇的类型 | | 明显分离的簇 | 一个簇中,任意数据对象到其他数据对象的距离要比到其他所有簇中数据对象的距离要小 | | 基于原型的簇 | | 簇的原型 | xx代表簇,如均值、一个数据点… | | 基于原型的簇 | 同一个簇中,数据对象到原型的距离小于这个数据对象到其他簇的原型的距离 |
| | 基于近邻的簇 | 位于同一个簇的数据对象,它到这个簇中一个或多个对象的距离小于它到不同簇的数据对象的距离 | | 基于密度的簇 | | 簇 | 数据分布比较稠密的区间,这些稠密的区间是由密度比较稀疏的区域分隔得到的, | | 适用 | 不规则的簇、相互缠绕的簇、存在噪音异常点的簇 |
| | 基于目标函数定义的簇 | | 步骤 | 设定目标函数 | | | 通过对目标函数最大化或最小化得到簇 | | 目标函数的优化 | |
|
| | 聚类分析的应用 | | 主要作为其他数据挖掘任务的中间步骤使用 | | 通过聚类得到不同的簇,将聚类的结果作为分类的输入,然后建立分类模型 | | 异常检测 |
| | | |
| | 聚类分析的种类 | | 基于划分准则的不同 | | 基于划分的聚类算法 | 将聚类算法划分为若干个互不相交的簇,每个对象只能属于其中的一个簇 | | 基于层次的聚类算法 | 结果:系统树图

对每一层进行阶段可以得到不同层次上的簇 |
| | 簇的分离性 | | 互斥性的聚类分析 | 一个数据对象只能属于其中的一个簇,簇和簇之间明显分离 | | 非互斥性的聚类分析 | 一个数据对象可能属于其中的一个或多个簇 |
| | 相似性度量方法 | | | 聚类的空间 | |
| | 要求和挑战 | 任意数据类型、任意形状、处理噪音;
可扩展性【高维】、可解释性【对簇的解释】 |
|
| 基于划分的聚类方法 | | 基本概念 | | | 首先设定一个特定的目标函数,通过优化目标函数,不断提升划分的质量,得到最终的簇 | | 目标函数 | SSE--误差平方和--累计计算每一个簇中每一个数据对象到这个原型的距离--越小越好
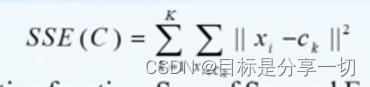
K:簇的数目
ck:每一个簇的原型 xi:属于簇i的数据对象 | | 优化sse | | 全局优化 | 列出k个划分所有的可能性,依次计算每一个划分的sse值,从中选择一个sse最小的划分 | | 局部最优策略 | 启发式算法,逐步逼近最优值 | | Kmeans | | 原型由平均值代表 | | | 过程 | | 首先设置一个参数k,随机选择k个簇中心 | | | 重复--都在优化sse | 将每个数据对象分配到离它最近的簇中心所在的簇中,从而形成k个簇;[使用相似性的度量方法]
根据每个簇中的数据对象更新簇中心 | | [使用相似性的度量方法] | 马氏距离、欧氏距离 | | 终止条件 | 簇中心不再变化 |

| | 缺陷 | 对初始中心点的选择非常敏感--结果与初始观察的分布差异性很大,质量差
| | 讨论 | | 效率 | 快,迭代次数较少

| | 得到的聚类结果往往是局部优化的结果 | 因为是针对簇中心来优化 | | k值需要确定 | | 绘制肘线图 | 选择下降率突变点作为k

|
| | 对异常点很敏感 | 均值受异常值影响强烈 | | 适用于球形簇 | | | 对k个初始中心点做初始化 | | 随机选一个数据对象作为初始中心点 | | | 在下一次选择初始中心点的时候,根据数据对象的加权数据分数,选择离之前所有初始中心点最远的点作为下一个初始中心点,迭代以上步骤一直到选出k个初始中心点 | |
|
| | 空簇问题 | | 空簇的产生 | 
| | 策略 | | 选择一个对sse贡献最大的数据对象作为新的簇中心 | | 选择具有最大sse的簇,在簇中随机选择一个数据对象作为新的簇中心 |
|
| | 总结 | 不能处理不同尺度不同密度非球形的簇;
对于包含异常的数据集合聚类效果很差
解决:开始将k的数目设置比较大,得到若干个比较小的簇,然后对这些比较小的簇进行合并,从而得到比较好的聚类结果 |
| | k-medoids【中心点?】 | | 处理kmeans对异常点敏感 | | | 使用最具有代表性的数据对象【往往离簇中心最近】取代原型 | 
| | vskmeans区别--更新簇中心时 | | kmeans | 计算所有数据对象的均值 | | k中心点 | 替换簇中心--从簇中非代表的数据中选择一个去替代原始数据对象,替代后计算代价cost,<0代表能缩小sse,可替换,重复直到簇标签不再变化 |
|
| | k-medians | 不用均值用中位数
| 采用马氏距离作为相似度测量方法 | 
|
|
|
|
|
| 基于层次的聚类方法 | | 基本概念 | | 产生嵌套类型的簇
以层次树的结构被组织
通过系统树图的形式可视化 | | 结果是一棵系统树图
【记录簇与簇之间的层次关系】 
记录了所有层次上的聚类结果,若想得到某一个层次上的聚类结果,直接截断即可 | | |
| | 凝聚的层次聚类算法 | | 自底向上 | 首先每一个数据对象被认为是一个簇,然后计算不同簇的相似性,合并最相似的两个簇,依次合并,直到所有对象在一个簇中 | | | 
| | 核心 | 迭代合并两个最为临近的簇--每次合并两个簇 | | 过程 | 
【近邻性矩阵】
| | 【近邻性矩阵】 | | 如何更新簇和簇之间的相似度 | 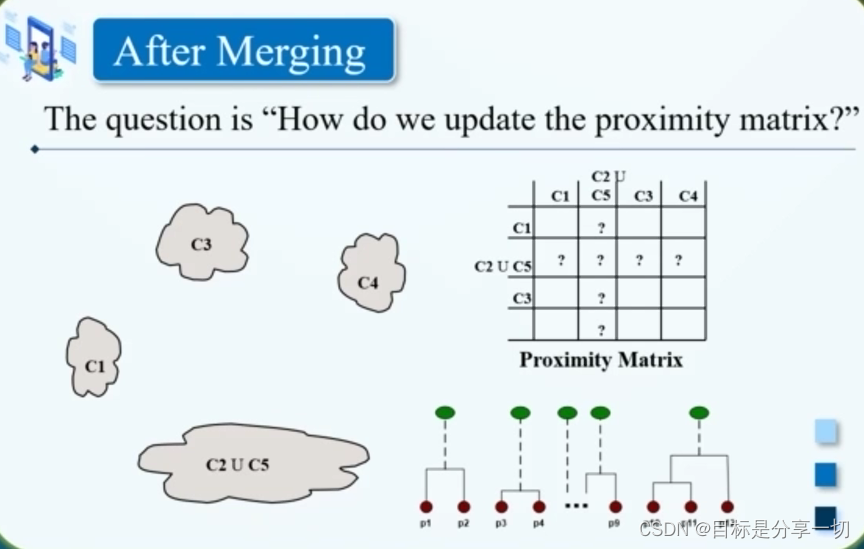
| | 单链方法min | | 两个簇的距离由两个簇中离得最近的两个数据对象的相似度代表 | | 缺点: 基于局部【只考虑离得比较近的区域,两个簇的整体结构被忽略】 对于噪音和异常点敏感 |
| | 全链方法max | | 两个簇的距离由两个簇中离得最远的两个数据对象的相似度代表 | | 缺点: 对于噪音和异常点敏感 产生比较紧凑的簇 |
| | 组平均 | | 两个簇的距离由两个簇中所有点对的相似度【距离】的平均值代表 | | 避免异常点的影响;复杂度较高 |
| | 中心链方法 | | | 基于目标函数的方法 | | 沃德方法 | 两个簇的相似性可以理解为合并这两个簇对sse的降低程度
类似组平均法,倾向于产生球形的簇 |
|
|
| | 分裂的层次聚类 | | 自顶向下 | 首先所有的数据对象组成一个簇,采用合适的分裂准则将簇一分为二,在得到的簇中选择对sse贡献最大的簇,再采用合适的分裂准则将簇分裂,分裂到最后每一个数据对象是一个簇。 | | | 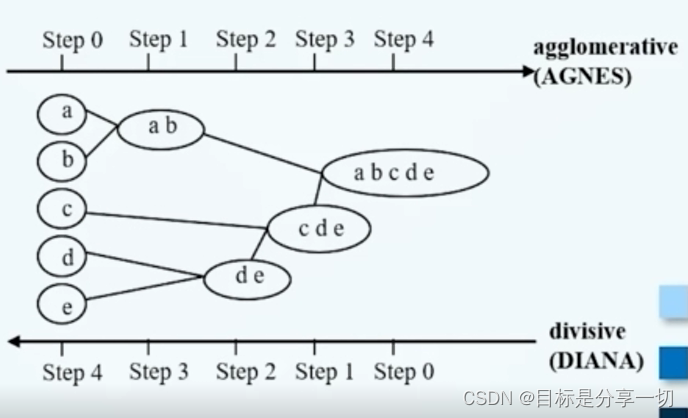
|
| | 层次聚类算法的特点 | | 一旦一个划分或凝聚完成,不可逆转 | 误差会被累积 | | 基于局部最优策略 | 缺乏全局优化 | | 不同模型 | 对异常点敏感;不能处理不同形状或非球形簇;倾向于分裂大簇 |
|
|
| 基于密度和基于网格的聚类方法 | | DBSCAN | | 基于密度定义的簇 | 簇是一个稠密的区域,由密度较低的区域分割得到;
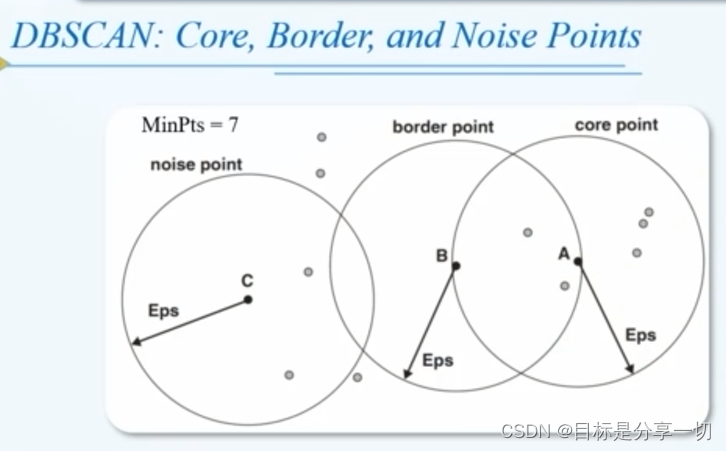
一个簇是密度相连点的最大集合 | | 密度 | 一个特定区间中特定对象的数目 | | 参数 | | eps | 邻域半径,通过设定eps半径,指定范围大小 | | Minpts | 最小密度,点的数目,由此确定稠密区域 |

点q的eps邻域指的是离这个点q的距离小于Eps所有点的集合 | | 所有数据对象被划分为3类 | | 核心点 | 位于稠密区域
以该点为中心,eps为半径,该区域的数据对象数目大于minpts | | 边界点 | 某个核心点的邻居【落入该点邻域内】,但以该点为中心,eps为半径,该区域的数据对象数目<minpts;
往往代表簇的边缘地 | | 异常点 | 不属于任何簇的点 |
| | 数据对象之间的关系被划分为3类 | | 直接密度可达 | p属于q的eps邻域;
q是核心点

p为q的直接密度可达点 | | 密度可达 | 若p为q的密度可达点,必然存在这样的一个策略p1,…,pn,p1=q,pn=p,在这个序列中,任意一个点pi+1都是pi的直接密度可达点
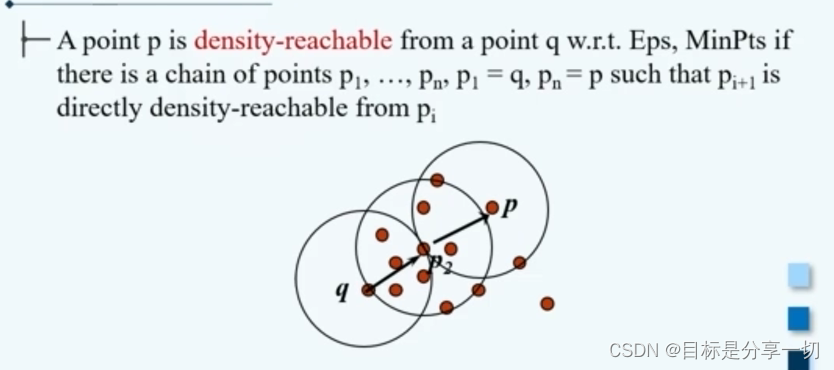
| | 密度相连 | 若p和q是密度相连的,必存在点o,p与q都是o的密度可达点【对称性】

簇是一个密度相连点的最大集合 |
| | 算法过程 | | 任选一个核心点,从核心点出发,找到一个最大的密度相连的区域 | | | 选中一个随机点p,找到p点所有密度可达点,若p是核心点,那么从p出发的簇就找到,若p是边界点则可选下一个点,从下一个点出发,找到下一个点的最大的密度相连的区域 | | | 重复以上过程,直到所有的对象都被反应完 | |
| | 复杂度 | | 数据对象被排序 | O(nlogn) | | 否则【最坏】 | O(n^2) |
DBSCAN 的基本时间复杂度是 O (m * 找出 Eps 邻域中的点所需要的时间 ),m 是点的个数。 最坏情况下,时间复杂度是O (m 2 ),用 kd 树 可以降到 O (m log m),即使对于高维数据,DBSCAN 的空间仍然是 O (m), | | 特点 | | 对于参数的设定敏感 | | 对噪音处理良好
对非凸形簇甚至是缠绕的处理良好 【DBSCAN可以处理不同大小或形状的簇,并且不太受噪声和离群点的影响。 】 | | 不适用:
数据集分布的密度变化比较大(or高维)【由于只设定了一个minpts,它倾向于认为簇的分布比较平均】 |
| | 合理设置参数 | 观察数据集中所有数据对象第k个最近邻的对象距离;
若数据集的分布比较均匀,大部分数据对象第k个最近邻的距离应该相近变化不大。【大的可能是噪音点】

可以选择突变附近的距离作为eps | | 小结 | k的数目不需要确定 能发现任意形状的簇
能处理数据集中的噪音
需要确定eps和minpts |
| | 基于网格的聚类 | | 依赖一种多分辨率的网格数据结构 | | | 网格数据结构 | 将整个数据空间划分为若干个小方格
最上层的小方格会对应到下层的若干个小方格
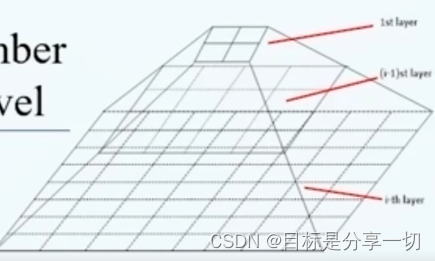
每一层上的特征可以进行累积计算,用落入到小方格的数据对象的均值数目方差minmax来作为方格特点
上一级方格的特征值可以由下一级方格的特征值进行简单运算得到【像图像处理…】 | | 算法过程 | | 定义合适的网格数据结构 | | 把数据对象合理分配到网格 | | 设立合适的阈值tao,将数据分布比较稀疏的网格过滤,保留较为稠密的网格 | | 检索这些稠密网格的连通区域,这些连通区域就是簇 |
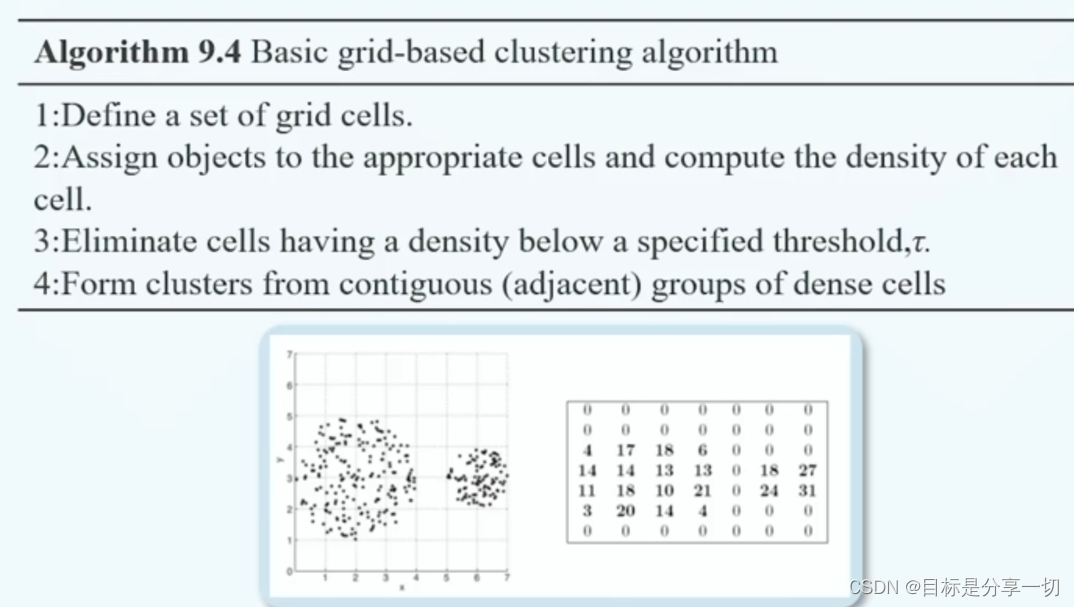
|
|
|
| 对聚类的评估 | | 聚类质量的评估--簇的质量 | | 外部方法 | 有监督的评估方法--常使用类标签--通过比较数据对象的簇标签和类标签来判断聚类质量 | Q(C,T) | | 假设使用到的外部评价知识为T,得到的聚类结果为C,用Q(C,T)代表对聚类结果的评估 | | 好质量要求:
同质性:簇中所有数据对象要求尽可能属于同一个类
完整性:一个类的数据对象要求尽可能分到同一个簇中
碎布袋:零散的数据对象放入一个簇中
保留小簇:小类->小簇 质量差于 大类->小簇 |
| | 度量指标 | | 纯度 | | 同一个簇中某一类别所占的比例 | | 
|
| | 精度 | 标记为p的t的比例【TP NP P】【横】 | | 召回率 | 
| | Fmeasure | 
对精度和召回率的平衡 | | Nmi
规范化互信息 | | 基于互信息 | 
| | 规范化 | 
| | 接近1,质量好 | |
|
|
| | 内部方法 | 根据数据的分布特性去设计一些评估指标来评估聚类质量--簇内凝聚性+簇的分离性(簇间尽可能不相似)
| 内部方法评估指标 | | SSE | 评估凝聚性 | | SSB | 评估分离性 | | 和为常量 | 最小化sse最大化ssb【同时评估】 |

ssb越大分离性越好

| 轮廓指数 | | a | 一个数据对象到同簇的数据对象的距离的平均值 | | b | 一个数据对象到非同簇的数据对象的距离的平均值,从所有中选一个最小的 | | | 
| | 【-1,1】 | 若小于0,差;
0,1,正常;
接近1,好 |
| | 相关系数 | | 计算两个矩阵之间的相关系数 | | 近邻性矩阵 | 数据对象和数据对象之间近邻性的矩阵proximity matrix
每一个矩阵中的元素代表任意两个数据的相似度 | | 理想相似性矩阵 | 如果两个对象属于同一个簇,那么对应矩阵元素为1,否则为0 | | 计算两者相关性 | | 相关系数高 | 效果好 | | 左好左高 | 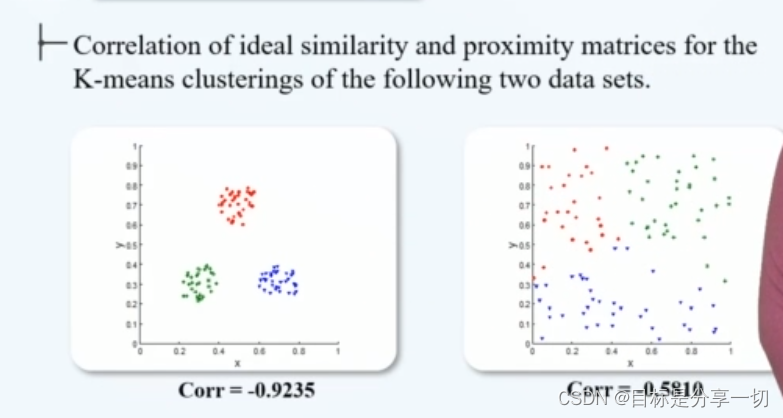
|
|
| | 通过数据对象之间的相似度矩阵可视化聚类结果 | 将属于同一个簇的数据对象尽可能排列在一起
| 好 | 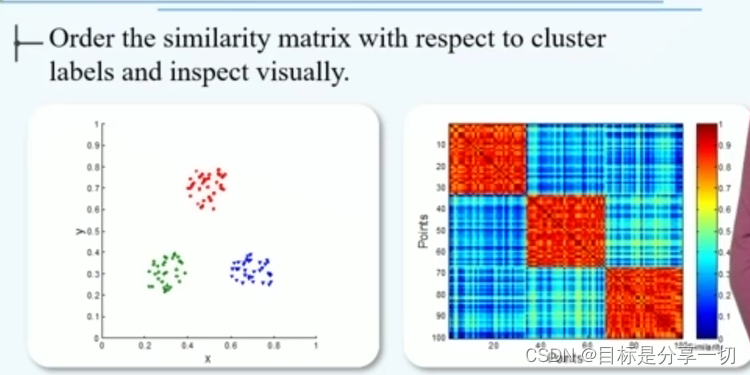
| | 差 | 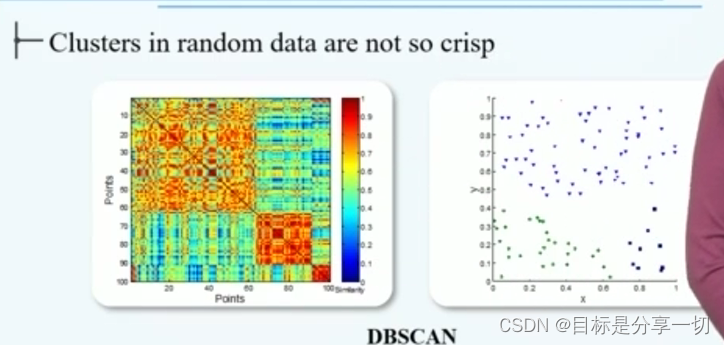
|
|
|
|
|
| | 聚类趋势的评估--数据集分布是否具有内在的组团结构 | | 均匀分布 | 无此聚集趋势,不需要进行聚类分析 | | 霍普金斯统计量 | 
从数据集D中抽取p个数据集对象组成数据集w,再从从数据集D中抽取p个数据集对象组成数据集u,
wi:集合w中任意一个数据对象到它最近邻的数据对象的距离的和
ui:集合u中任意一个数据对象到D-u中离它最近的数据对象的距离的和
如果是均匀的,wi的值和ui的值是接近的,霍普金斯的值接近于0.5,不均匀时为0或1 |
|
|
mooc题目
| 单选 (2分) 简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集中,这种聚类类型称作() A.划分聚类 B.模糊聚类 层次聚类 D.非互斥聚类 | 划分聚类 |
| 在基本K均值算法里,当邻近度函数采用 ()的时候,合适的质心是簇中各点的中位数 A.曼哈顿距离 B.平方欧几里德距离 余弦距离 D.Breqman散度 | | 邻近度函数:曼哈顿距离。 | 质心:中位数。
目标函数:最小化对象到其簇质心的距离和 | | 邻近度函数:平方欧几里德距离。 | 质心:均值。 目标函数:最小化对象到其簇质心的距离的平方和 | | 邻近度函数:余弦。 | 质心:均值。 最大化对象与其质心的余弦相似度和 | | 邻近度函数:Bregman 散度。 | 质心:均值。 目标函数:最小化对象到其簇质心的Bregman散度和 |
|
| 单选(2分)()将两个簇的邻近度定义为不同簇的所有点对的平均逐对邻近度,它是一种凝聚层次聚类技术。 A.MIN (单链) B.MAX(全链) C.组平均 D.Ward方法 | | 单链方法min | | 两个簇的距离由两个簇中离得最近的两个数据对象的相似度代表 | | 缺点: 基于局部【只考虑离得比较近的区域,两个簇的整体结构被忽略】 对于噪音和异常点敏感 |
| | 全链方法max | | 两个簇的距离由两个簇中离得最远的两个数据对象的相似度代表 | | 缺点: 对于噪音和异常点敏感 产生比较紧凑的簇 |
| | 组平均 | | 两个簇的距离由两个簇中所有点对的相似度【距离】的平均值代表 | | 避免异常点的影响;复杂度较高 |
| | 中心链方法 | | | 基于目标函数的方法 | | 沃德方法 | 两个簇的相似性可以理解为合并这两个簇对sse的降低程度
类似组平均法,倾向于产生球形的簇 |
|
|
| 4 单选(2分)DBSCAN在最坏情况下的时间复杂度是 () A. O(n^2) B.O(n) c.o(logn) D.O(n*logn) | | 复杂度 | | 数据对象被排序 | O(nlogn) | | 否则【最坏】 | O(n^2) |
|
|
| 判断(2分)K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的 簇 A.V B.X | | K均值很难处理非球形的簇和不同大小的簇。 | | DBSCAN可以处理不同大小或形状的簇,并且不太受噪声和离群点的影响。 |
|
| 判断(2分) 从点作为个体族开始,每一步合并两个最接近的簇,这是一种分裂的层次聚类方法 A.X | 凝聚的: 从点作为个体簇开始,每一步合并两个最近的簇, 需要定义簇的邻近性概念(开始每个点都是一个簇,然后不断合并减少簇的数量)。 |
| 判断(2分) DBSCAN中密度相连关系满足对称性【对】 | 密度相连:假设有样本集D,s到p是密度可达的,s到q也是密度可达的,那么称p到q是密度相连的。 |
| 判断 (2分) 聚类中把小簇划分成更小簇比把大簇划分为小簇的危害更大【对】 | |
| 判断(2分) 聚类中,当对象o的轮廓系数值接近0时,意味着包含o的簇是紧凑的,并且o远离其他簇【错】 | 聚类总的轮廓系数SC为:SC= \frac {1} {N}\sum_ {i=1}^ {N} {SC (d_ {i})} | 轮廓系数为-1 | 聚类结果不好 | | +1 | 紧凑 | | 0 | 簇重叠 |
|
chapter7
内容
| 异常和异常分析的基本概念 | | 异常 | 一个数据对象和其余数据对象差异性比较大 | | 噪音 | 测量数据中的随机错误或偏差;
在进行异常监测之前应该首先将噪音去掉 | | 异常分类 | | 全局离群点 | 一个数据对象和其余数据对象差异性比较大 | | 上下文离群点【情境异常/情境离群点】 | | 某一个情境下,该点和其余数据对象差异性比较大 | | | 对象属性划分为两部分 | |
| | 群体异常 | 一组数据对象和其余数据对象差异性比较大 |
|
|
| 异常分析的方法 | | 异常检测时是否需要使用有标记的数据 | | 基于监督的 | | 异常检测->分类 | 有标记的数据用作分类集和测试集,构建一个分类模型,对未标记的数据进行预测,判断类别 | | 挑战 | 类别不平衡性【异常占比低】; 要求尽可能识别所有的异常,对于召回率的要求更高【错杀一千不放一个】
|
| | 基于半监督的 | | 可能标记为全为正常数据,也有可能标记为一小部分异常 | | | 如果数据标记的是正常数据 | 利用有标记的正常数据和与这些正常数据比较接近的数据,把它们作为训练集,用来代表正常数据,建模,然后判断数据对象是否与正常模型相符,如果不符合就认为是异常的。 | | 仅标记少量异常 | 需要无监督的方法进行异常识别 |
| | 基于无监督的 | | 假设可以将数据划分为若干个簇,位于大簇中的数据是行为比较正常的数据,如果一个数据对象离所有的簇都比较远,那么我们认为这样的一个数据就是异常 | | | 缺点 | | 不能识别群体异常; | 使用聚类方法不能有效识别群体异常 | | 正常数据行为的多样性 | 有较高的错误的正事例率但仍然会漏掉很多异常 | | 基于聚类算法 | 很难将噪音和异常进行区分;
代价比较高【先聚类后异常识别】 |
|
|
| | 基于对正常数据及异常数据的假设 | | 基于统计的异常分析方法 | | 假设数据符合某个统计分布 | | | 计算每个对象属于这个分布的概率,若低则为异常 | | | 方法:有参和无参 | 假设模型,数据->参数->分布->概率密度->每个对象由这个分布产生的概率 |
| | 基于邻近性的异常检测方法 | 如果一个数据的邻近性和数据中大部分对象的邻近性的差异性比较大,我们认为这个数据异常;
基于距离,基于密度;
| | 基于聚类和分类的异常检测方法 | | 基于聚类 | 如果一个对象属于的簇比较大,正常;如果一个对象属于的簇比较小或稀疏,异常 |
|
|
|
| 基于统计的异常分析方法 | | 对一元数据的异常检测 | | 一元数据 | 数据只有一个属性 | | 正态分布 | 数据->参数->模型->估算 | | Eg:3sigma【有参】 | | 使用最大似然方法估算均值和方差,使用zscore标准化 | | 利用3σ原则 |
| | 最大标准残差检验【有参】 | | 使用最大似然方法估算均值和方差,使用zscore标准化 | | 利用z进行

T分布 |
|
| | 多元数据的异常检测 | | 多元数据 | 属性个数>=2 | | mahalaobis距离 | | 计算均值,计算o到均值的马氏距离, | | 构建一维数组,代表每一个对象到数据均值的马氏距离 | | 使用最大标准残差检验方法检验异常 |
| | 卡方检验【有参】 | 计算均值,计算每个对象的chi方值

|
| | 无参 | | 绘制直方图 | 
| | 困难 | 很难确定直方图宽度
宽度较小:正常数据落入空的直方图,产生fp【false positive】
宽度较大:异常数据落入频率高的的直方图,产生fn【false negative】 |
|
|
| 基于邻近性的异常检测方法 | | 基于距离 | | | 根据某个数据对象特定邻域范围内数据对象的个数判断这个数据对象是否异常,若多则正常 | | 参数 | | r | 距离阈值--邻域范围 | | Π | 比率阈值--衡量某个数据对象它特定邻域内的数据对象的个数占全体数据对象的个数的比例 |
| | 判定 | 
Π;
这个数据对象到它的第k个最近邻邻居的距离,若大于r则认为异常,k=Π*数据集中数据对象数目 | | 缺点 | 难以确定局部异常-和邻居比是异常,和全局不是
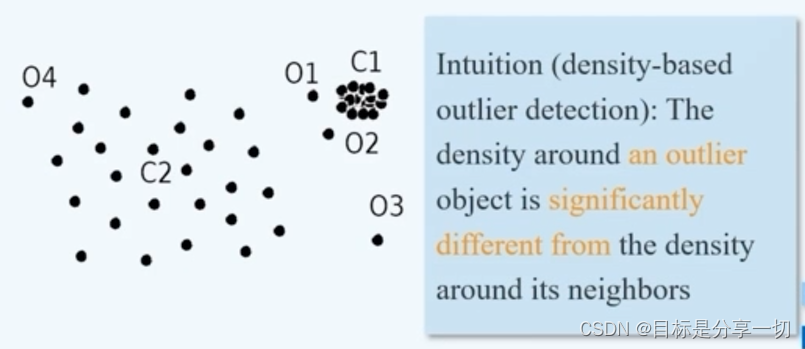
若判o1o2异常,c2中所有对象可能被判定为异常 |
| | 基于密度 | | 方法 | 局部异常评分:将数据对象和它邻居的密度进行对比,若邻居密度高,则这个对象异常;反之正常 | | 变量 | | 数据对象o的k距离:distk(o) | o到第k个最近邻邻居的距离

| | 数据对象o的k近邻邻域:Nk(o) | 离这个数据对象的距离<=distk(o)的所有数据对象的集合
【数目可能>k因为距离可能相等】 
| | 数据对象o到o‘的可达距离reachdistk(o) | 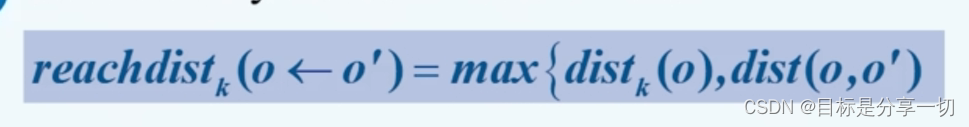
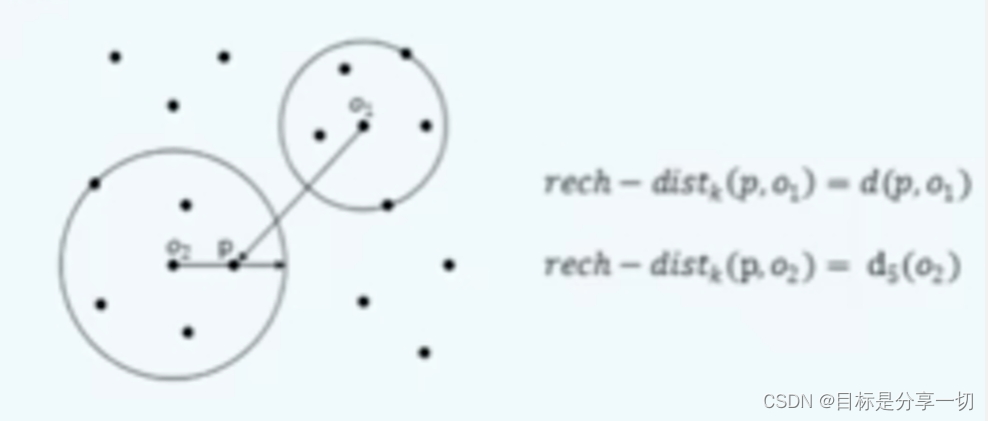
右上为o1 | | 局部可达密度lrdk(o) | 
某一个数据对象所有邻居到这个对象的可达距离的平均值的倒数【越大越好】
样本 p 的第 k 邻域内点到 p 的平均可达距离的倒数 | | 局部异常因子LOF | 
对每个数据对象的异常评分 含义:这个数据对象所有邻居的局部可达密度和这个对象局部可达密度比值的均值【局部可达密度越大越好,这个对象做分母,所以越小越好】
越高:周围邻居密度比对象的高很多,异常评分越高,为异常的可能性高
- 如果这个比值接近 1,说明 p 其邻域点密度差不多,p 可能和邻域点输入同一簇;
- 如果这个比值越小于 1,说明 p 的密度就高于其邻域点密度,p 为密集点;
- 如果这个比值越大于 1,说明 p 的密度小于其邻域点密度,p 越可能是异常点。
【要和周围邻居密度比较】
|
|
|
|
| 基于聚类和分类的异常检测方法 | | 基于聚类 | | 异常点 | 若一个数据对象不属于任何簇or这个数据对象离比较大的簇的距离较远or属于比较稀疏的簇 | | 方法 | | dbscan | 直接识别异常点 | | kmeans | 
若这个数大,代表这个数据对象可能离其簇中心距离较大->异常 |
| | 针对群体异常 | 无法有效检测 |
| | 分类 | | 异常检测->分类 | 正常->正事例
异常->负事例 | | 缺点 | 类别不均衡 | | One-class model | | 所有的正事例去构建一个用于描述正事例的模型 | | 将数据对象与模型对比,若不符合则为异常 |
|
|
|
mooc题目
| 噪声不属于异常 | 异常分为群体异常、情境离群点、全局离群点 |
| 无参的异常检测方法和有参的异常检测方法 | | 无参 | 直方图 | | 有参 | 卡方检验、3σ、最大标准残差检验 |
|
| 局部异常因子 | | =1 | 可能与邻域点为一个簇 | | <1 | p为密集点 | | >1 | 异常点 |
|
| 异常检测前需要剔除噪声 | |
| 在异常检测中召回率比精度更重要 | Recall[TP/P]异常中被抓出来的比例 |
| 聚类中的异常点 | 若一个数据对象不属于任何簇or这个数据对象离比较大的簇的距离较远or属于比较稀疏的簇 |
| 局部异常因子得到异常点的原理 | 局部异常评分:将样本的局部密度与其邻居的局部密度进行比较,样本密度明显低于其邻居的样本被认为是异常点。 |
| 局部异常因子计算中,样本 p 的第 k 邻域内点到 p 的平均可达距离的倒数成为样本p 的 | 局部可达密度 |
mooc期末考试试题
| 以下哪些算法是分类算法,A,DBSCAN B,C4.5 C,K-Mean D,EM (B) | C4.5就是决策树分类器,用于分类… |
| 以下哪些算法是基于规则的分类器 () A. C4.5 B. KNN C. Naive Bayes--基于统计 D. ANN | 基于规则的分类器有决策树、随机森林、Aprior |
| 召回率vs精确率
2.单选(2分) 以下两种描述分别对应哪两种对分类算法的评价标准?(a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。(b)描述有多少比例的小偷给警察抓了的标准。 A. Precision, Recall B. Recall.Precision C. Precision.ROC D.Recall,ROC | 


| 
| 第一行P为数据集中实际为positive的;
TP表示数据集中为P也真的被标记为P的;
FN表示数据集中为P被标记为N的,实际为P
对应Recall | | 
| 第一列为P为数据集中被标记为positive的;
TP表示数据集中为P也真的被标记为P的;
FP表示数据集中为N被标记为P的,所以是假的P,实际为N
对应Precission | | 抓的人=标记为P的,是小偷=TP->TP/P' | Precission | | 小偷=真的为P的,被抓=TP->TP/P | Recall |
|
| 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务? A.频繁模式挖掘 B.分类和预测 数据预处理 数据流挖掘 | 数据预处理 |
| 属性Hair_color = fauburn, black, blond, brown,grey, red, white),该属性属于 ()类型 A标称 B.二分 C.序数 数值 | 
|
| 下面不属于数据集特征的是:() A.连续性 B.维度 稀疏性 D.分辨率 | 数据集的一般特性: 维度 (具有的属性数目) 稀疏性(在非对称特征数据集,一个对象大部分属性上的值为0) 分辨率(分辨率太高,模式可能看不清楚,分辨率太低可能模式不出现)
分布 |
| 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?() A.分类 聚类B. 关联分析 隐马尔可夫链 | 分类:已经有标签可以自动分类 聚类:不知道标签,按照范围内圈区域聚类贴标签 关联分析:对象之间蕴含的关系和规律,比如超市里小朋友感兴趣的商品大多数放下面的货架 隐马尔科夫链:统计分析,描述一个含有隐含未知参数的马尔可夫过程, |
| 只有非零值才重要的二元属性被称作:( ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 | 二元属性:0和1.显而易见,0表示不出现,1表示出现 分为:对称性和非对称性 对称性二元属性:两个个状态同等重要 非对称性:两个状态不是同等重要的(更重要的/几率较小的赋值1),两个都取1(正匹配)比两个都取0(负匹配)的情况更有意义 |
| 以下哪种方法不是常用的数据约减方法 () A.抽样 B. 回归 C.聚类 D.关联规则挖掘 | |
| 下面哪一项关于CART的说法是错误的 ) A.分类回归树CART是一种典型的二又决策树。 B.CART输出变量只能是离散型 C.CART用“成本复杂性”标准 (cost-complexity pruning) 来剪枝 D.CART使用的分裂准则是Gini系数 | ID3 Gain max 离散型
C4.5 GainRatio max 输入:离散or连续;输出:离散
CART Gini加权 min 输入输出:离散or连续 |
| 检测一元正态分布中的离群点,属于异常检测中的基于 ()的离群点检测 A统计方法 B.邻近度 密度 聚类技术 | A |
| 以下哪些算法是分类算法 A. DBSCAN B.C4.5 C.K-Mean D.EM | | 分类技术 | | 基础分类器 | 决策树模型、基于规则的方法、基于深度学习和神经网络的方法、naive贝叶斯方法和贝叶斯信念网络、支持向量机 | | 集成分类器 | | 基础分类器的基础上,通过集成策略,将多个分类器集成构建新的分类器 | | 提升、袋装、随机森林 |
|
|
|
| 基于规则的分类器 | 有决策树、随机森林、Aprior。 |
| ()是一个观测值,它与其他观测值的差别如此之大,以至于怀疑它是由不同的机制产生的。 A.边界点 B.质心 离群点 核心点 | 离群点 |
| 
| | 不同簇的所有点对的平均逐对邻近度 | 组平均 | | 两个簇合并时导致的平方误差的增量 | ward |

|
| 关于K均值和DBSCAN的比较,以下说法不正确的是 ()。 A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象。 B.K均值使用簇的基于原型的概念,而DBSCAN使用基于密度的概念 C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇 .D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇 | A 均值聚类k-means是基于划分的聚类, DBSCAN是基于密度的聚类。区别为: - k-means需要指定聚类簇数k,并且且初始聚类中心对聚类影响很大。k-means把任何点都归到了某一个类,对异常点比较敏感。DBSCAN能剔除噪声,需要指定邻域距离阈值eps和样本个数阈值MinPts,可以自动确定簇个数。
- K均值和DBSCAN都是将每个对象指派到单个簇的划分聚类算法,但是K均值一般聚类所有对象,而DBSCAN丢弃被它识别为噪声的对象。
- K均值很难处理非球形的簇和不同大小的簇。DBSCAN可以处理不同大小或形状的簇,并且不太受噪声和离群点的影响。当簇具有很不相同的密度时,两种算法的性能都很差。
- K均值只能用于具有明确定义的质心(比如均值或中位数)的数据。DBSCAN要求密度定义(基于传统的欧几里得密度概念)对于数据是有意义的。
- K均值算法的时间复杂度是O(m),而DBSCAN的时间复杂度是O(m^2)。
- DBSCAN多次运行产生相同的结果,而K均值通常使用随机初始化质心,不会产生相同的结果。
- K均值DBSCAN和都寻找使用所有属性的簇,即它们都不寻找可能只涉及某个属性子集的簇。
- K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇。
- K均值可以用于稀疏的高维数据,如文档数据。DBSCAN通常在这类数据上的性能很差,因为对于高维数据,传统的欧几里得密度定义不能很好处理它们。
|
| 大于或等于 min-support 的非空子集,称为____。 | 频繁项集 |
| 关联规则挖掘问题可以划分成两个子问题:发现频繁项目集和生成______。 | 关联规则 |
| DBSCAN算法时间复杂性O(__) | DBSCAN 的基本时间复杂度是 O (m * 找出 Eps 邻域中的点所需要的时间 ),m 是点的个数。 最坏情况下,时间复杂度是O (m 2 ),用 kd 树 可以降到 O (m log m),即使对于高维数据,DBSCAN 的空间仍然是 O (m), |
| 局部异常因子计算中,样本 p 的第 k 邻域内点到 p 的平均可达距离的倒数成为样本p 的____ | 局部可达密度 |
| 数据挖掘是从大量数据中挖掘重要、隐含的、以前未知、______的模式或知识。 | 潜在有用的 |
| 从数据仓库的角度可以将数据挖掘过程划分为_______、数据集成、数据选择与变换、数据挖掘及知识评估等阶段。 | 数据清理 |
| 数据挖掘任务主要包括描述性和_____任务。 | 预测性 |
| 数据集的属性可以划分为_____和连续型两种。 | 离散型 |
| 通过离散化操作可以将连续属性转化为____属性 | 序数? |
| 样本p的局部异常因子值接近____,说明 p 与其邻域点密度差不多,p 可能和邻域点属于同一簇。 | 1 |
| 通过数据集成可以维护数据源整体上的数据______ | 一致性 |
| 聚类中不属于任何簇的数据对象可以被认为是_____ | 离群点? |
| 异常点类型包括全局异常、上下文异常和______ | 群体异常

|
| KNN算法是一种典型的______学习器 | 消极 |
| 使用DBSCAN进行异常点检测时,异常点被定义为________的数据对象。 | 不属于任何簇的点

|
| C4.5算法采用基于_____作为选择分裂属性的度量标准。 | ID3--信息增益 C4.5--信息增益率
CART--基尼指数
贝叶斯算法--基于统计的
|
| CART采用Gini指数来度量分裂时的不纯度。_____越大,样本集合的不确定性程度越高 | 基尼指标越大越不纯,不确定性越高 |
这篇关于数据仓库与数据挖掘c5-c7基础知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!










