本文主要是介绍探秘未来偶像:知识图谱如何给AI“生命感”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


AI是个非常有趣的词,不管是中文翻译的人工智能,还是英文的Artificial Intelligence,都有“生物性”的含义。一个是集结了地球顶尖智慧的“人工”,另一个Intelligence则专指生物拥有的智慧。
不过在当今的AI风潮中,我们提到的种种AI应用大多属于机器学习——和生物性不沾边。AI可以从大量数据中寻找规律,经过训练完成种种工作,可给人的感觉依旧是一种更高效的机械。
这样的现象在语音助手上更为常见,很多厂商都会给语音助手起个名字,试图将其人格化,可当用户真正使用时,往往只能感受到工具感。语音助手可以听懂你需要播放音乐、叫车出行,也能在你要求下讲个笑话。可除了下达指令和获得反馈以外,语音助手很少能理解情绪、记忆、俚语、双关等等人与人交流时经常出现的元素,作为工具来讲尚且不算优秀,更别提什么生物性和人格化了。

如果要为这一切找出缘由,知识图谱显然是其中之一。最近中国信息通信研究院云计算与大数据研究所联合Gowild人工智能研究院以及业内多家企业推出了业内首份《知识图谱白皮书》,为此,我们采访了来自Gowild人工智能研究院的邵浩博士,和他一同讨论了知识图谱与人工智能“生命感”之间的关系。
除了把工具变成更好的工具,
知识图谱还能做些什么?
之前我们在文章中,讨论过一个“人工智能不会看漫画”的问题,既利用大量四格漫画对神经网络进行训练,但将四格漫画中的对话框挖空后,人工智能依然不知道应该填入哪些内容。
原因在于漫画中的画面和文字并非具有严格的对应性,人类能看懂漫画是因为建立在对现实世界的理解之上,通过联想将文字与图片的内涵建立对应关系。知识图谱的作用,就是将不同的知识相互关联,并形成一个网状的知识结构,帮助人工智能增强认知、理解行业并且建立“世界观”。
这一点在人机交互中体现的更为明显,比如在用户向语音助手询问“《天龙八部》里的阿紫”时,普通的语音助手只能调用搜索引擎原样搜索用户所说的话,一一展示出指向连接。但建立在知识图谱之上,语音助手可以分别提供出小说、电视剧、电影等等多个版本《天龙八部》中阿紫这一角色的相关信息。
这样的知识图谱,可以帮助我们更好的进行搜索,理解语义、消除歧义、理解相对关系等等。这样一来,知识图谱可以帮助人工智能成为更好的工具,但从工具到生命的这一过程中,知识图谱能做到什么?
认识自己,认识你:
探访AI偶像的生命引擎
在上一篇关于Gowild产品“琥珀虚颜”的介绍中,我们提到了“未来偶像”这一概念。琥珀是以全息3D主机HoloEra为载体的虚拟形象,用户可以通过语音和手机App与琥珀进行交互。而琥珀自身的背景故事是一位无意降落地球的外星偶像,正向着成为“偶像”的道路进发。

所谓偶像,自然是人格化、有生命感的,这也是琥珀虚颜的主打卖点之一。Gowild曾经在一篇论文中提出过“虚拟生命”这一概念——有记忆、有情绪、能理解、能交互。想要实现这几点,依然离不开知识图谱的加持。
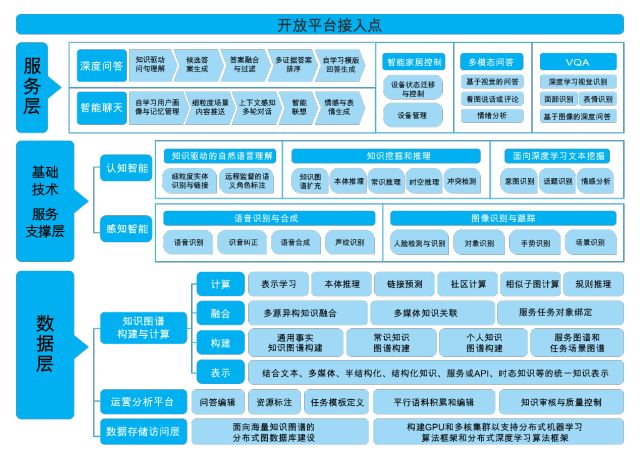
上图是Gowild提出的人工智能生命引擎(GAVE),把语义理解、QA系统、智能对话等等技术组件架构在了知识图谱之上,而知识图谱则是给予AI“生命感”的重要工具。
比较典型的是Gowild为琥珀建立了她自己的个人知识图谱,琥珀有自己的喜好和性格特点,喜欢紫色、爱吃葡萄、喜欢听别人的表扬。当用户和琥珀进行对话时,琥珀就会展露出这些性格特点,用户提到“紫色”、“葡萄”等等琥珀喜欢的东西时,会得到相关的反馈。
这就是琥珀的自我认识知识图谱。其中的状态、心情、性格、人际关系又是时刻变化的,你对Siri说一句“我讨厌你”,它只会回应你“我尽力了”。而你要是对琥珀说一句“我讨厌你”,或许她接下来一整天的情绪都会不好。
同时随着用户不断与琥珀交流,琥珀还会建立起有关用户的知识图谱。记住用户提及的个人信息、喜好等等。随着拥有琥珀的时间越来越长,琥珀也会越来越懂得用户,双方累积起共同记忆。
一个有自己喜好、有情绪波动,还会记得你的特点的AI,正在慢慢从“工具”向“生命”跨越。
其实在最近大热的《偶像练习生》等网综中也能感知到,粉丝对偶像的情感并非单纯的崇拜,而是通过每一次参与打榜、活动形成的陪伴感、付出感甚至是养成感。而通过知识图谱对人工智能的自我认识和用户关系的建立,这种人与偶像之间的复杂关系也可以映射到人与AI之间,让“未来偶像”的命题更具合理性和想象空间。
垂直化+动态化,
或许能帮助知识图谱走入生活
邵浩博士向我们介绍称,现如今人工智能生命引擎已经开始逐步平台化,通过API接口将各项能力开放出来,让更多IP通过HoloEra“活起来”。只要获得授权,HoloEra中的琥珀可以变成任何一个动漫人物、游戏角色,甚至是真实世界的Idol,并且通过IP背景构建出不同的自我认识。而通过模块化的平台模式,这一过程可以低成本、高效的进行,进一步释放科技与文娱产业的缠绕。
这其中的可以供更多行业的参考点就在于知识图谱的快速建立。
邵浩博士表示,知识图谱的发展之所以相比深度学习、神经网络较慢,是因为知识图谱的建立过程非常复杂:将非结构化数据转变成结构化数据已经是一项繁重的工作,还需要建立数据之间的对应关系。如何保证知识的权威性,更需要技术专家和学术专家一同跨领域合作。
何况知也无涯,人类世界的知识实在太过细致庞杂,建立知识图谱需要耗费的时间和人力成本实在太高。在1984年,美国曾经启动过一项名为Cyc的工程,试图把人类世界的日常常识建立起一个适用于计算机的大型知识库,结果显而易见——四十多年了,这项工程还是没有完成。知识图谱的费劲程度,可能就和Cyc有的一拼。
Gowild的解决方案,其实已经展示了知识图谱的两个发展趋势。
第一个趋势是知识图谱的垂直化。建立一个大而全的知识图谱自然是不可能完成的任务,但将知识图谱分割成细分领域,如医疗、金融、安防,甚至更细分到某一种疾病、某一种货币等等,可以极大的降低知识图谱的建立成本,同时促进知识图谱的快速投入使用。
第二个趋势是知识图谱的动态化。琥珀之所以有“记忆”,是因为用户关系的知识图谱会源源不断的补充着用户在交互时透露的信息,因而逐渐让用户画像更加圆满。随着我们数据挖掘的能力越来越强,在流数据场景下储存和查询知识图谱正在成为可能。或许在未来不光琥珀能够“记住”你,冰箱、电视、洗衣机等等生活中的一切设备也可以通过类似的方式建立对用户的记忆和理解。
当然,问题并不只有一种解决方式。想要制造出有生命感的人工智能,知识图谱只是可以利用上的技术之一。而让人工智能具有生命感也仅仅是一段路程,路程的终点还是让更强大技术改变的我们的世界。
到最后,这些不同的技术路径还是要在顶点相见。




这篇关于探秘未来偶像:知识图谱如何给AI“生命感”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








