本文主要是介绍【Kafka】从安装到配置再到监控,教你搭建一套sasl/scram类型的Kafka集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 准备工作
- 修改配置文件
- 创建初始用户
- 创建jaas文件
- 修改启动脚本
- 启动Kafka
- 添加Systemd
- Kafka监控
- 部署jmx_exporter
- 配置Prometheus
- 配置Grafana
- 后记
本文的主要内容是讲解一个4个broker,SASL/SCRAM类型的Kafka集群搭建过程。
准备工作
安装jdk
安装Zookeeper和kafka之前,需要先安装java环境,并配置环境变量,推荐Java 8。
安装zookeeper
Kafka依赖zookeeper,安装Kafka之前需要安装zk。
搭建过程参考:zookeeper搭建
安装包准备
下载安装包:
下载Kafka:http://kafka.apache.org/downloads
也可下载Confluent:https://www.confluent.io/download/#confluent-platform
confluent包含了Kafka以及其他组件,如果只需要用到Kafka的基本功能,下载Kafka即可,由于工作需要,我下载的是confluent,但是对Kafka使用的操作,都是一样的。
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 etc]# ll
total 4
drwxr-xr-x 2 1000 pgadmin 47 Jul 19 2018 camus
drwxr-xr-x 2 1000 pgadmin 6 Jul 19 2018 confluent-common
drwxr-xr-x 2 1000 pgadmin 4096 Feb 2 18:27 kafka
drwxr-xr-x 2 1000 pgadmin 49 Jul 19 2018 kafka-connect-elasticsearch
drwxr-xr-x 2 1000 pgadmin 40 Jul 19 2018 kafka-connect-hdfs
drwxr-xr-x 2 1000 pgadmin 90 Jul 19 2018 kafka-connect-jdbc
drwxr-xr-x 2 1000 pgadmin 88 Jul 19 2018 kafka-connect-s3
drwxr-xr-x 2 1000 pgadmin 6 Jul 19 2018 kafka-connect-storage-common
drwxr-xr-x 2 1000 pgadmin 59 Jul 19 2018 kafka-rest
drwxr-xr-x 2 1000 pgadmin 178 Jul 19 2018 ksql
drwxr-xr-x 2 1000 pgadmin 6 Jul 19 2018 rest-utils
drwxr-xr-x 2 1000 pgadmin 149 Jul 19 2018 schema-registry
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 etc]# pwd
/neworiental/cdc/confluent-4.1.2/etc
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 etc]#
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 etc]# 解压安装包:
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 cdc]# tar -zxvf confluent-4.1.2.tar.gz
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 cdc]# cd confluent-4.1.2
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 confluent-4.1.2]# ls
bin etc lib logs README share src
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 confluent-4.1.2]#
修改配置文件
confluent对应的kafka配置文件目录:$confluent_home$/etc/kafka/server.properties
独立的kafka包对应的配置文件在:$kafka_home$/config/server.properties
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 kafka]# ll
total 84
-rw-r--r-- 1 1000 pgadmin 906 Jul 19 2018 connect-console-sink.properties
-rw-r--r-- 1 1000 pgadmin 909 Jul 19 2018 connect-console-source.properties
-rw-r--r-- 1 1000 pgadmin 5994 Jul 19 2018 connect-distributed.properties
-rw-r--r-- 1 1000 pgadmin 5807 Jul 19 2018 connect-distributed.properties.orig
-rw-r--r-- 1 1000 pgadmin 883 Jul 19 2018 connect-file-sink.properties
-rw-r--r-- 1 1000 pgadmin 881 Jul 19 2018 connect-file-source.properties
-rw-r--r-- 1 1000 pgadmin 1111 Jul 19 2018 connect-log4j.properties
-rw-r--r-- 1 1000 pgadmin 2917 Jul 19 2018 connect-standalone.properties
-rw-r--r-- 1 1000 pgadmin 2730 Jul 19 2018 connect-standalone.properties.orig
-rw-r--r-- 1 1000 pgadmin 1221 Jul 19 2018 consumer.properties
-rw-r--r-- 1 root root 140 Feb 2 18:07 kafka_server_jaas.conf
-rw-r--r-- 1 1000 pgadmin 4727 Jul 19 2018 log4j.properties
-rw-r--r-- 1 1000 pgadmin 1919 Jul 19 2018 producer.properties
-rw-r--r-- 1 root root 8377 Feb 2 17:51 server.properties
-rw-r--r-- 1 1000 pgadmin 1032 Jul 19 2018 tools-log4j.properties
-rw-r--r-- 1 1000 pgadmin 1023 Jul 19 2018 zookeeper.properties
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 kafka]# pwd
/neworiental/cdc/confluent-4.1.2/etc/kafka
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 kafka]#
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 kafka]#
四个broker,除了broker.id和listeners 不一样,其他都一样。
核心配置如下:
#每一个broker在集群中的唯一表示,要求是正整数
broker.id=0
#Kafka服务端两种协议的监听地址,只需把IP替换为本台机器的即可
listeners=PLAINTEXT://172.24.29.128:9092,SASL_PLAINTEXT://172.24.29.128:9093
#数据存储目录
log.dirs=/neworiental/cdc/data/kafka
#zk地址
zookeeper.connect=172.24.29.128:2181,172.24.29.129:2181,172.24.29.130:2181
#zk连接超时时间
zookeeper.connection.timeout.ms=6000#scram相关
sasl.enabled.mechanisms=SCRAM-SHA-256
sasl.mechanism.inter.broker.protocol=SCRAM-SHA-256
security.inter.broker.protocol=SASL_PLAINTEXT
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
allow.everyone.if.no.acl.found=true
super.users=User:admin
以上是核心配置,当然还有很多配置是重要的,对于Kafka优化也有很大的作用,感兴趣的可以查一查Kafka优化,后面也会有专门的文章讲解。
注意:如果是搭建一个PLAINTEXT类型的Kafka集群,每个broker修改完配置文件,依次启动即可,如果是搭建一个SASL/SCRAM类型的Kafka,还需要以下操作
创建初始用户
找到解压后对应的脚本目录,我的是在:/neworiental/cdc/confluent-4.1.2/bin
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 bin]# ls
camus-config kafka-console-consumer kafka-producer-perf-test kafka-server-start ksql-print-metrics windows
camus-run kafka-console-producer kafka-reassign-partitions kafka-server-stop ksql-run-class zookeeper-security-migration
confluent kafka-consumer-groups kafka-replay-log-producer kafka-simple-consumer-shell ksql-server-start zookeeper-server-start
connect-distributed kafka-consumer-offset-checker kafka-replica-verification kafka-streams-application-reset ksql-server-stop zookeeper-server-stop
connect-standalone kafka-consumer-perf-test kafka-rest-run-class kafka-topics ksql-stop zookeeper-shell
kafka-acls kafka-delegation-tokens kafka-rest-start kafka-verifiable-consumer schema-registry-run-class
kafka-avro-console-consumer kafka-delete-records kafka-rest-stop kafka-verifiable-producer schema-registry-start
kafka-avro-console-producer kafka-log-dirs kafka-rest-stop-service ksql schema-registry-stop
kafka-broker-api-versions kafka-mirror-maker kafka-run-class ksql-datagen schema-registry-stop-service
kafka-configs kafka-preferred-replica-election kafka-run-class.orig ksql-node support-metrics-bundle
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 bin]# pwd
/neworiental/cdc/confluent-4.1.2/bin
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 bin]#
执行创建scram用户的脚本命令
confluent对应的脚本是bin目录下的kafka-configs,单独的Kafka是bin目录下的kafka-configs.sh
/neworiental/cdc/confluent-4.1.2/bin/kafka-configs --zookeeper ip:port --alter --add-config 'SCRAM-SHA-256=[password=your secret],SCRAM-SHA-512=[password=your secret]' --entity-type users --entity-name admin
脚本命令里面的两个password是一样的,记住用户名和密码,一会需要用到。
创建jaas文件
在每个broker的服务器上创建jaas文件,我创建文件的目录是:/neworiental/cdc/confluent-4.1.2/etc/kafka/kafka_server_jaas.conf,后面需要指定该文件路径。
kafka_server_jaas.conf文件内容:
用户名密码为刚刚创建的
KafkaServer {org.apache.kafka.common.security.scram.ScramLoginModule requiredusername="admin"password="your secret";
};
修改启动脚本
confluent对应的启动脚本是bin目录下的kafka-server-start,单独的Kafka是bin目录下的kafka-server-start.sh
方法1:
需要在启动参数中指定jaas的路径:-Djava.security.auth.login.config=你的jaas文件路径
exec $base_dir/kafka-run-class $EXTRA_ARGS -Djava.security.auth.login.config=/neworiental/cdc/confluent-4.1.2/etc/kafka/kafka_server_jaas.conf io.confluent.support.metrics.SupportedKafka "$@"
如果是单独的Kafka版本,则改为如下:
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS -Djava.security.auth.login.config=/neworiental/cdc/confluent-4.1.2/etc/kafka/kafka_server_jaas.conf kafka.Kafka "$@"
没啥区别,启动的类不一样
注意:-Djava.security.auth.login.config=xxx一定要加在$EXTRA_ARGS之后。
方法2:
也可以直接在脚本最前面加上:
export KAFKA_OPTS=-Djava.security.auth.login.config=/bigdata/confluent-4.1.2/etc/kafka/kafka_server_jaas.conf
export JMX_PORT="9999"
export JMX_PORT=“9999” 这句是之后做监控用的,如不需要,可以不加
启动Kafka
当四个broker都完成以上操作之后,执行启动脚本
nohup /neworiental/cdc/confluent-4.1.2/bin/kafka-server-start /neworiental/cdc/confluent-4.1.2/etc/kafka/server.properties >/neworiental/cdc/data/kafka-log/kafka.log 2>&1 &
添加Systemd
如果要在机器启动就自动启动Kafka服务,或者Kafka挂了可以自动启动,可以继续之后的操作
编写Kafka启动、停止脚本
kafka-start.sh
#!/bin/bashPID=`ps -ef | grep '/neworiental/cdc/confluent-4.1.2' | grep -v grep | awk '{print $2}'`
if [[ "" != "$PID" ]]; thenecho "killing kafka : $PID"kill $PID
fisleep 1/neworiental/cdc/confluent-4.1.2/bin/kafka-server-start /neworiental/cdc/confluent-4.1.2/etc/kafka/server.properties >/neworiental/cdc/data/kafka-log/kafka.log 2>&1 &
echo "kafka is starting..."
kafka-stop.sh
#!/bin/bashPID=`ps -ef | grep '/neworiental/cdc/confluent-4.1.2' | grep -v grep | awk '{print $2}'`
if [[ "" != "$PID" ]]; thenecho "killing kafka : $PID"kill $PID
fi
每台机器上传完脚本后,需要赋予执行权限
chmod +x kafka-start.sh kafka-stop.sh
添加Systemd
进入目录:/usr/lib/systemd/system
创建文件:kafka.service
写入以下内容:
[Unit]
Description=Apache Kafka Server
Documentation=http://kafka.apache.org/documentation.html
After=network.target[Service]
User=root
Group=root
Type=forking
WorkingDirectory=/neworiental/cdc/confluent-4.1.2/
ExecStart=/neworiental/cdc/confluent-4.1.2/kafka-start.sh
ExecStop=/neworiental/cdc/confluent-4.1.2/kafka-stop.sh
RestartSec=60
Restart=always[Install]
WantedBy=multi-user.target
注意:执行脚本的路径不要写错,还有脚本中必须要加:#!/bin/bash,否则会报错:code=exited, status=203/EXEC
kafka.service文件创建成功之后,执行命令启用:
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-003 system]# systemctl enable kafka.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kafka.service to /usr/lib/systemd/system/kafka.service.
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-003 system]#
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-003 system]# systemctl start kafka.service
Kafka监控
部署jmx_exporter
以下内容为Kafka监控相关,如不需要则跳过
四台机器都要部署
下载:https://github.com/prometheus/jmx_exporter
规则配置文件:
kafka-0-8-2.yml
#对应之前配置的JMX端口
hostPort: 127.0.0.1:9999
lowercaseOutputName: true
rules:
- pattern : kafka.cluster<type=(.+), name=(.+), topic=(.+), partition=(.+)><>Valuename: kafka_cluster_$1_$2labels:topic: "$3"partition: "$4"
- pattern : kafka.log<type=Log, name=(.+), topic=(.+), partition=(.+)><>Valuename: kafka_log_$1labels:topic: "$2"partition: "$3"
- pattern : kafka.controller<type=(.+), name=(.+)><>(Count|Value)name: kafka_controller_$1_$2
- pattern : kafka.network<type=(.+), name=(.+)><>Valuename: kafka_network_$1_$2
- pattern : kafka.network<type=(.+), name=(.+)PerSec, request=(.+)><>Countname: kafka_network_$1_$2_totallabels:request: "$3"
- pattern : kafka.network<type=(.+), name=(\w+), networkProcessor=(.+)><>Countname: kafka_network_$1_$2labels:request: "$3"type: COUNTER
- pattern : kafka.network<type=(.+), name=(\w+), request=(\w+)><>Countname: kafka_network_$1_$2labels:request: "$3"
- pattern : kafka.network<type=(.+), name=(\w+)><>Countname: kafka_network_$1_$2
- pattern : kafka.server<type=(.+), name=(.+)PerSec\w*, topic=(.+)><>Countname: kafka_server_$1_$2_totallabels:topic: "$3"
- pattern : kafka.server<type=(.+), name=(.+)PerSec\w*><>Countname: kafka_server_$1_$2_totaltype: COUNTER- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>(Count|Value)name: kafka_server_$1_$2labels:clientId: "$3"topic: "$4"partition: "$5"
- pattern : kafka.server<type=(.+), name=(.+), topic=(.+), partition=(.*)><>(Count|Value)name: kafka_server_$1_$2labels:topic: "$3"partition: "$4"
- pattern : kafka.server<type=(.+), name=(.+), topic=(.+)><>(Count|Value)name: kafka_server_$1_$2labels:topic: "$3"type: COUNTER- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), brokerHost=(.+), brokerPort=(.+)><>(Count|Value)name: kafka_server_$1_$2labels:clientId: "$3"broker: "$4:$5"
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+)><>(Count|Value)name: kafka_server_$1_$2labels:clientId: "$3"
- pattern : kafka.server<type=(.+), name=(.+)><>(Count|Value)name: kafka_server_$1_$2- pattern : kafka.(\w+)<type=(.+), name=(.+)PerSec\w*><>Countname: kafka_$1_$2_$3_total
- pattern : kafka.(\w+)<type=(.+), name=(.+)PerSec\w*, topic=(.+)><>Countname: kafka_$1_$2_$3_totallabels:topic: "$4"type: COUNTER
- pattern : kafka.(\w+)<type=(.+), name=(.+)PerSec\w*, topic=(.+), partition=(.+)><>Countname: kafka_$1_$2_$3_totallabels:topic: "$4"partition: "$5"type: COUNTER
- pattern : kafka.(\w+)<type=(.+), name=(.+)><>(Count|Value)name: kafka_$1_$2_$3_$4type: COUNTER
- pattern : kafka.(\w+)<type=(.+), name=(.+), (\w+)=(.+)><>(Count|Value)name: kafka_$1_$2_$3_$6labels:"$4": "$5"启动脚本
#!/bin/sh
. /etc/profilePID=`ps -ef | grep 'jmx_prometheus_httpserver-0.14.1-SNAPSHOT-jar-with-dependencies.jar' | grep -v grep | awk '{print $2}'`
if [[ "" != "$PID" ]]; thenecho "killing kafka : $PID"kill $PID
fisleep 1nohup java -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.port=5555 -jar ./jmx_prometheus_httpserver-0.14.1-SNAPSHOT-jar-with-dependencies.jar 5556 ./kafka-0-8-2.yml >./jmx.log 2>&1 &目录结构:
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 jmx_prometheus_exporter]# ll
total 404
-rw-r--r-- 1 root root 404199 Jan 22 19:03 jmx_prometheus_httpserver-0.14.1-SNAPSHOT-jar-with-dependencies.jar
-rw-r--r-- 1 root root 2845 Jan 22 19:02 kafka-0-8-2.yml
-rwxr-xr-x 1 root root 270 Feb 4 17:54 start.sh
[root@JZJG-T-ZJJPTJZYZ-CDC-KAFKA-TEST-002 jmx_prometheus_exporter]#
给启动脚本赋执行权限:
chmod +x start.sh
启动jmx_exporter:
./start.sh
检验是否启动成功:端口号对应启动脚本中jar包后面的数字
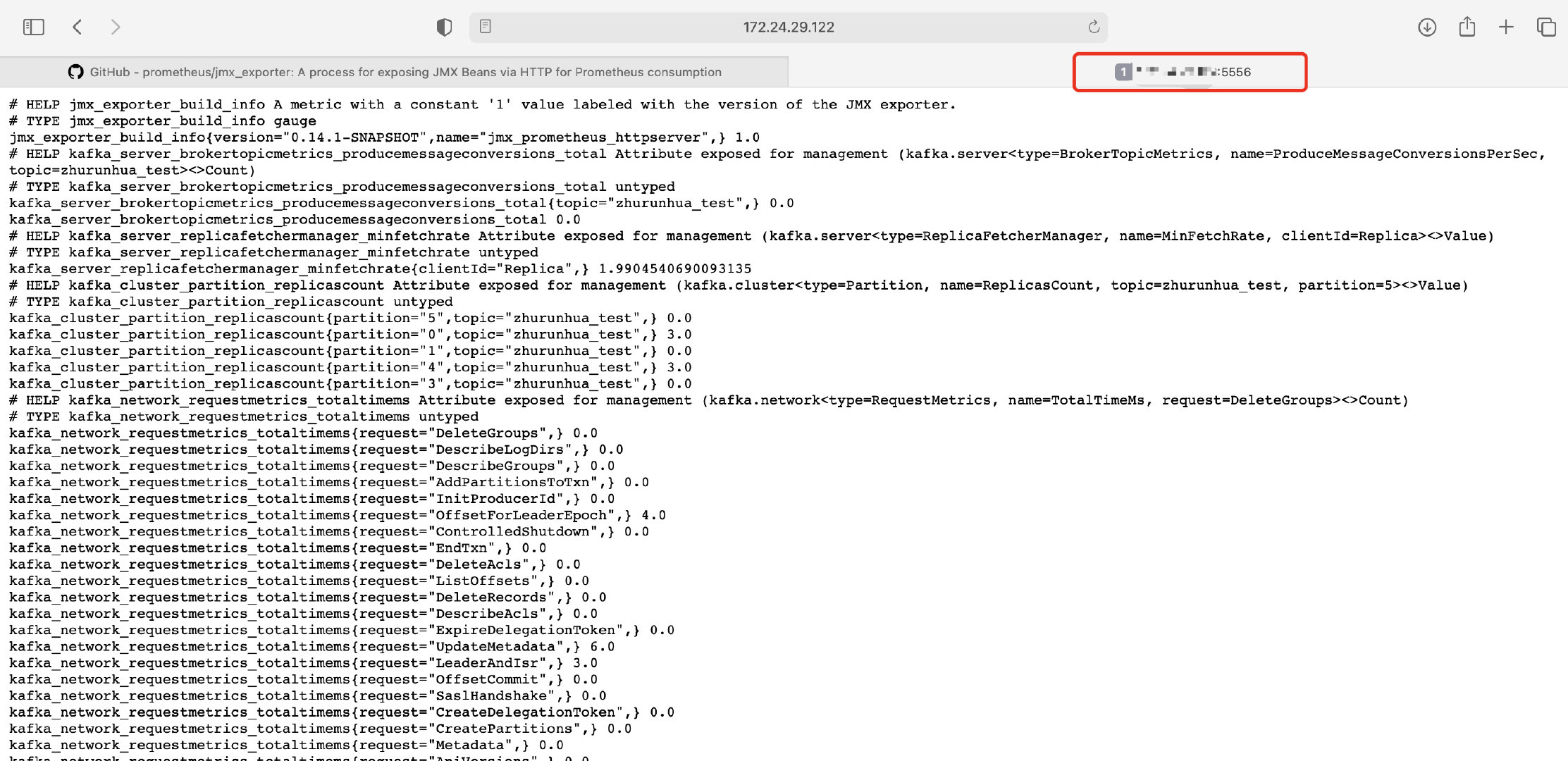
以上就说明启动成功了,并且根据配置的规则拉取信息了
记住四台机器上都要部署
配置Prometheus
安装prometheus和grafana的内容,本篇文章先不做介绍,不是很难,可以自行查阅,主要讲配置。
将四台机器的jmx_exporter配置到prometheus的job中
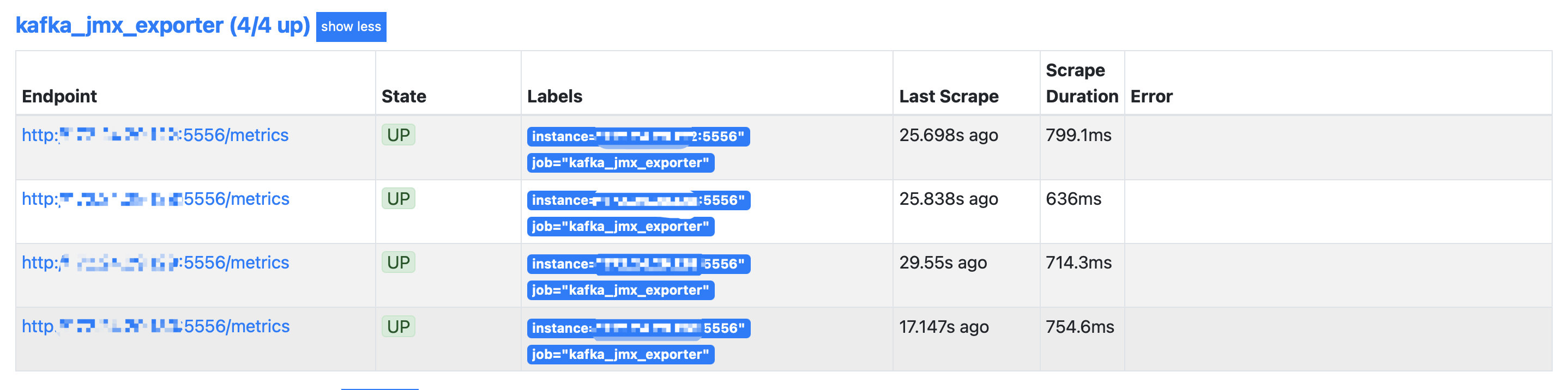
- job_name: 'kafka_jmx_exporter'static_configs:- targets: ['172.24.29.122:5556','172.24.29.128:5556','172.24.29.129:5556','172.24.29.130:5556']
配置完之后,在Prometheus的targets页面能看到新加的job
配置Grafana
我使用的Grafana是之前搭建好的,Prometheus对应的datasourse也配置好了,直接配置dashboard即可。
配置dashboard
先下载dashboard模版:https://grafana.com/grafana/dashboards?search=jmx_exporter

复制dashboard id
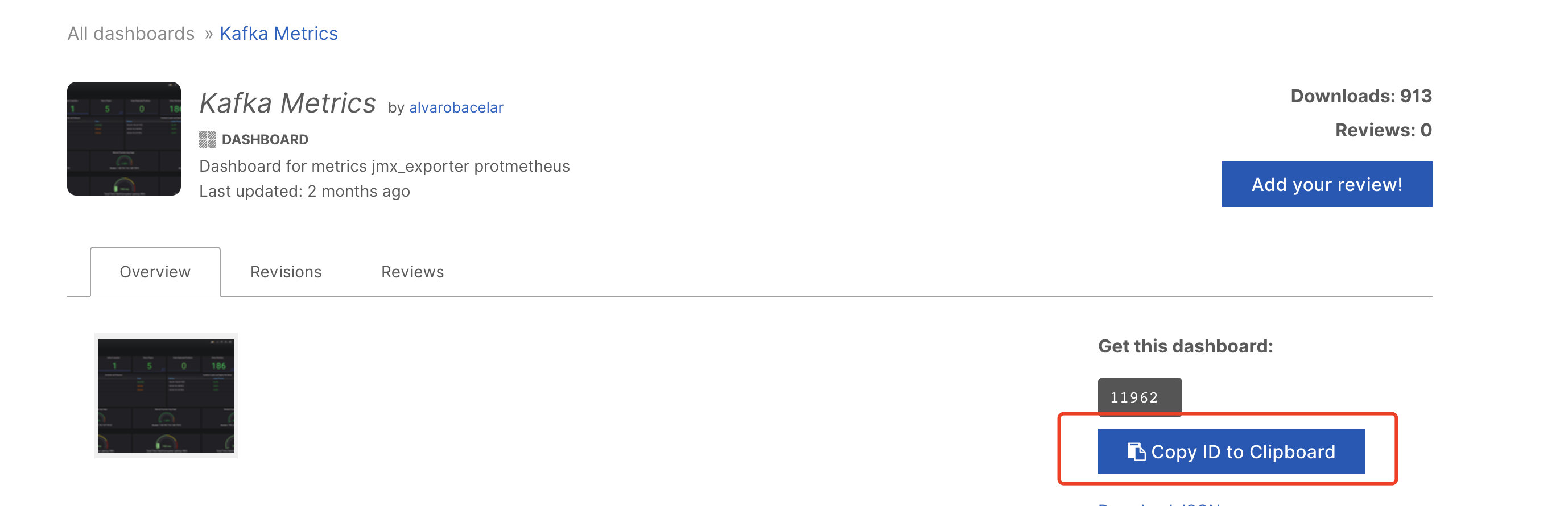
在grafana中创建dashboard
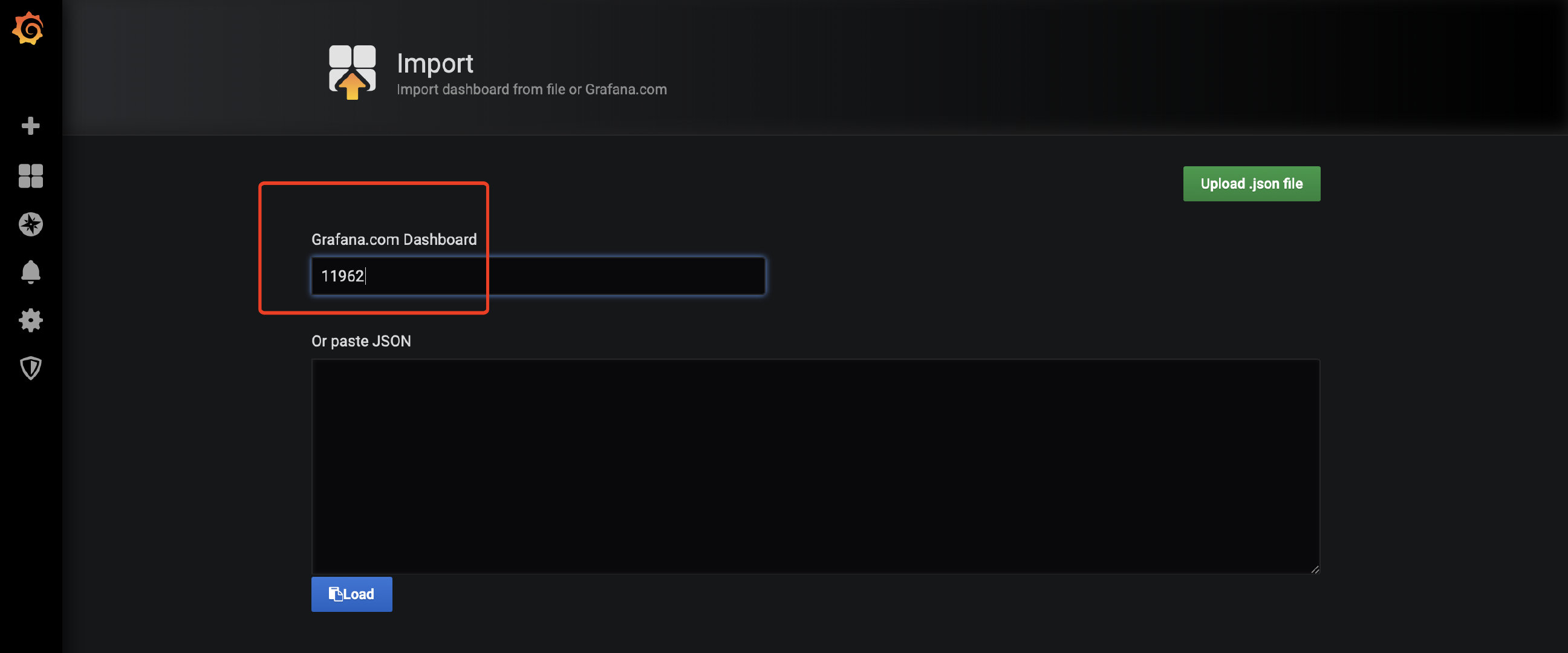
设置参数

最后点击import 完成dashboard导入
注意:因为grafana版本的问题,有些图表可能会不支持显示,此时需要升级grafana或者自定义图表,比如我用的是6.x的版本,出现以下情况:
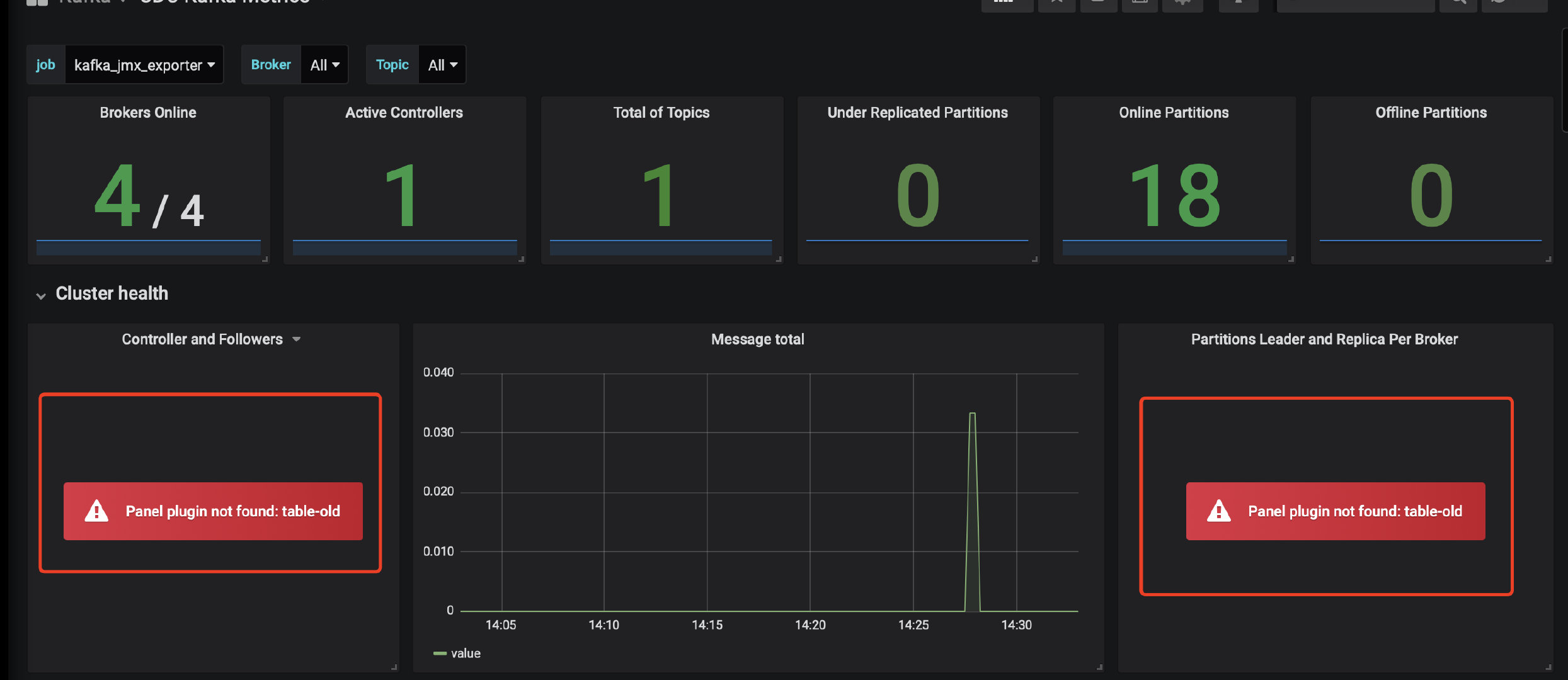
此时不要慌,数据是已经采集到了,只是没有显示而已,可以编辑该部分,进行自定义(下图是我调整好的效果)

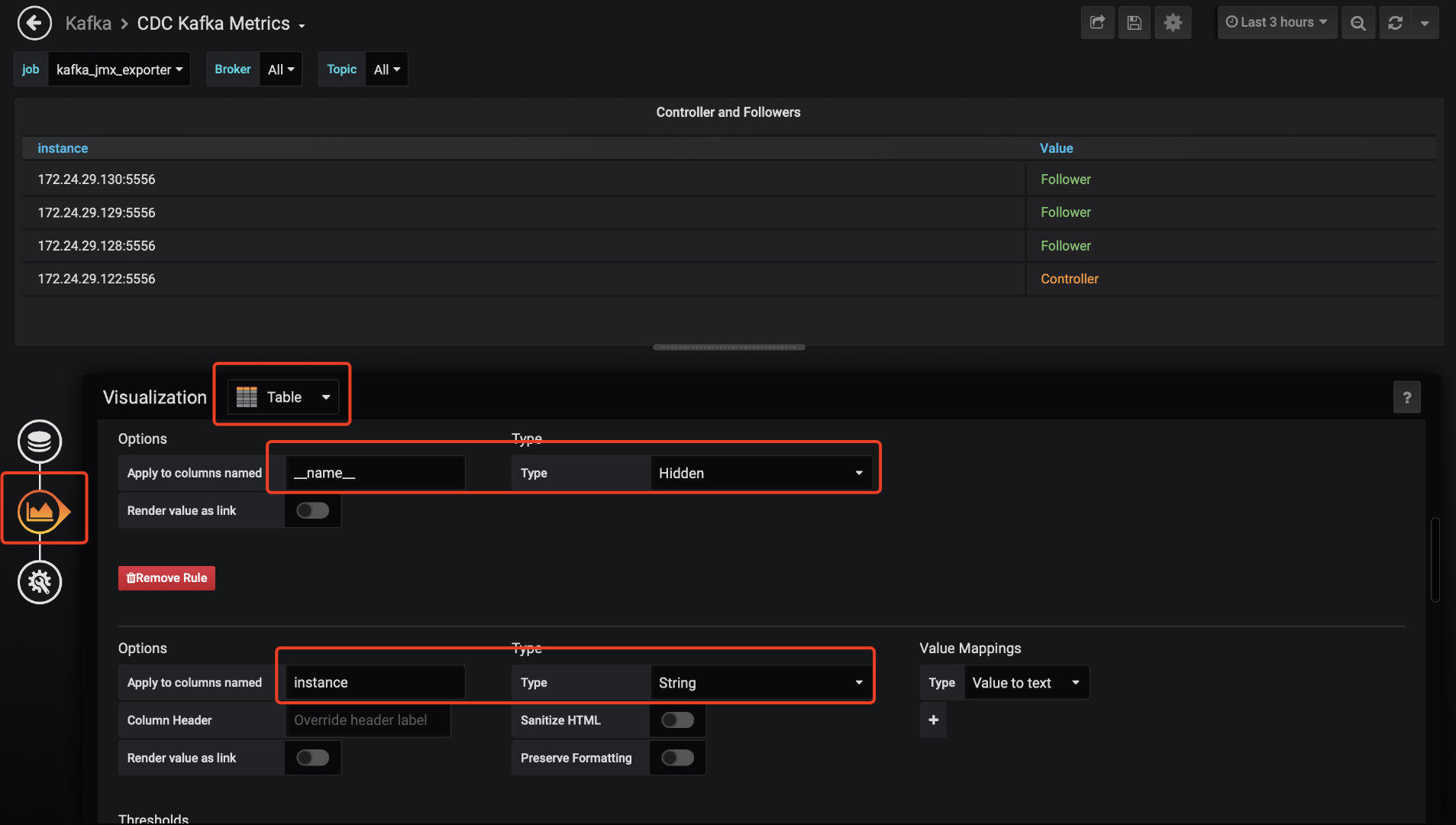
可以选择视图,我这块显示的是表格,所以选table,然后可以自定义每一列,包括是否显示、类型、转换、颜色、显示名字等等,编辑完之后,点击右上方的保存按钮即可
所以最后的效果图:
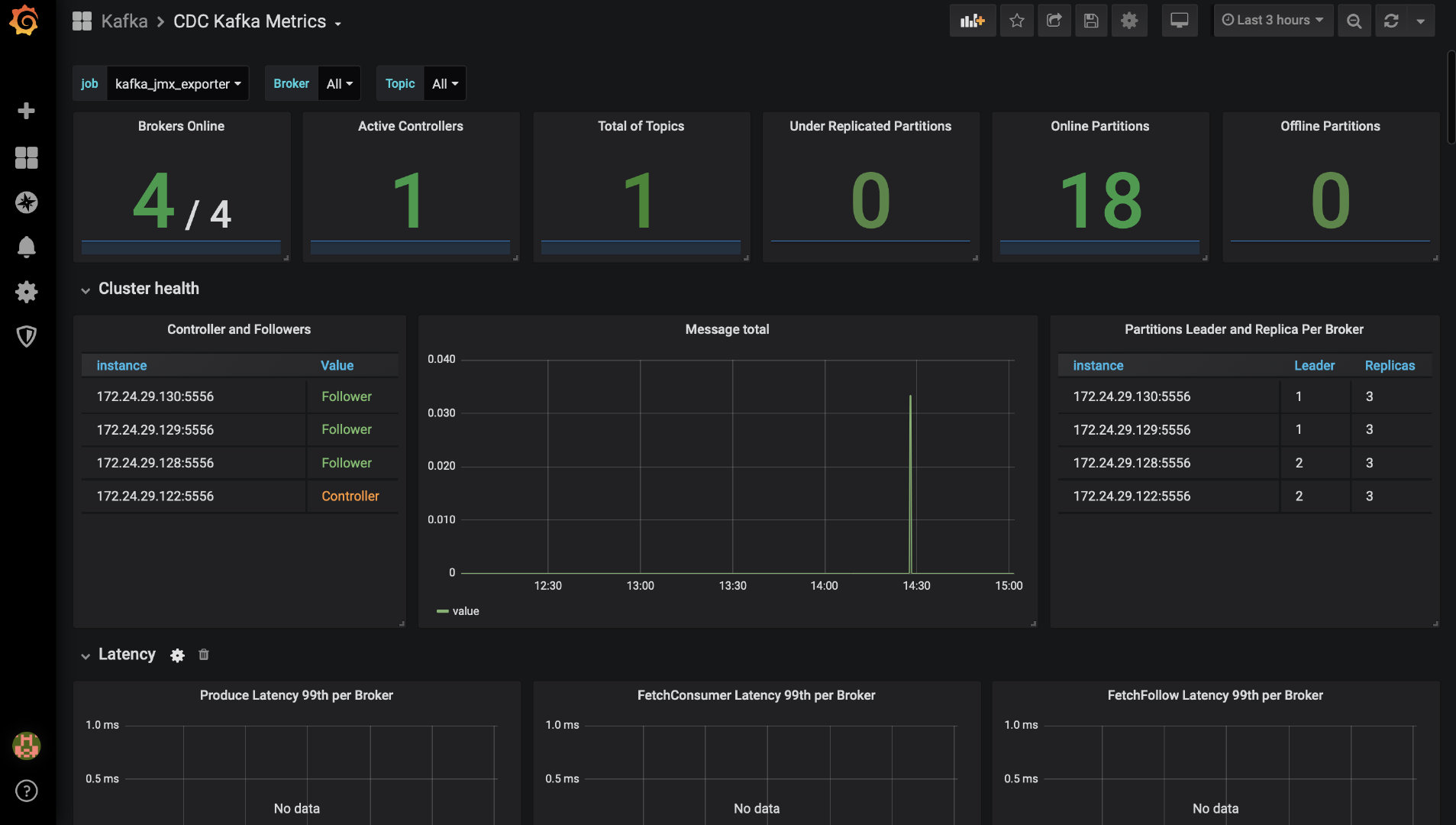
完美了,收工,回家过年。
后记
搭建的过程会遇到挺多问题,但是只有真正遇到问题,解决问题,才能成长,如果只是看书、学历理论,不做实践,终究是纸上谈兵,把整个过程捋了一遍,以后也会有经验,并且将过程记录下来,会大大加深印象,只有多锻炼,多实践,才能慢慢地独当一面。
这篇关于【Kafka】从安装到配置再到监控,教你搭建一套sasl/scram类型的Kafka集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







