本文主要是介绍NNDL实验三,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2.2线性回归
2.2.1数据集构建
构造一个小的回归数据集:
生成 150 个带噪音的样本,其中 100 个训练样本,50 个测试样本,并打印出训练数据的可视化分布。
import random
import torch
import matplotlib.pyplot as pltdef synthetic_data(w, b, num_examples,x_av=0,x_var=1,y_av=0,y_var=1):#torch.normal生成(均值,方差,形状)的高斯分布数据X = torch.normal(x_av, x_var, (num_examples, len(w)))#这里是x的分布y = torch.matmul(X, w) + b#进行线性变换y += torch.normal(y_av,y_var, y.shape)#这里是y加上变换之后的线性值得偏移return X, y.reshape((-1, 1))true_w = torch.tensor([3.4])
true_b = torch.tensor([4.2])
train_features, train_labels = synthetic_data(true_w, true_b, 100)#训练集
test_features,test_labels=synthetic_data(true_w,true_b,50)#测试集
#创建直线数据
start_train=min(train_features)#以下是取训练集的最大最小值显示未添加高斯噪声的直线
end_train=max(train_features)
line_x=torch.linspace(start_train[0],end_train[0],100)
line_y=torch.matmul(line_x.reshape((-1,1)), true_w) + true_b
#绘图
plt.scatter(train_features,train_labels,s=10,label='train data')
plt.scatter(test_features,test_labels,s=10,c='r',label='test data')
plt.plot(line_x,line_y,c='gray')
plt.legend()#显示标签
plt.show()

2.2.2模型构建
y = X w + b ( 1 ) y=Xw+b\quad(1) y=Xw+b(1)
其中 X ∈ R N × D \boldsymbol{X}\in\mathbb{R}^{N\times D} X∈RN×D为 N \boldsymbol{N} N个样本的特征矩阵, y ∈ R N \boldsymbol{y}\in\mathbb{R}^{N} y∈RN个预测值组成的列向量。或者写为 f ( x ; θ ) = w ⊤ X + b f(x;\theta)=w^{\top}\boldsymbol{X}+b f(x;θ)=w⊤X+b其中 θ \theta θ包含参数 w w w和 b b b
def linreg(X, w, b): #@save"""线性回归模型"""return torch.matmul(X, w) + b
2.2.3损失函数
均方误差(mean-square error, MSE)
L ( y , y ^ ) = 1 2 N ∥ y − y ^ ∥ 2 = 1 2 N ∥ X w + b − y ∥ 2 ( 2 ) \mathcal{L}(y,\hat{y})=\frac{1}{2N}\|y-\hat{y}\|^2=\frac{1}{2 N}\|\boldsymbol{X} \boldsymbol{w}+\boldsymbol{b}-\boldsymbol{y}\|^2 \quad(2) L(y,y^)=2N1∥y−y^∥2=2N1∥Xw+b−y∥2(2)
def squared_loss(y_hat, y): #@save"""均⽅损失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
其中 y y y由 ( 1 ) (1) (1)式给出为 N N N个样本的真实标签, y ^ \hat y y^为预测值标签
均方误差除以2的原因为在求导的时候会和指数的平方相抵消以便于书写,在2.2.4中我们可以看到
2.2.4模型优化
经验风险 ( Empirical Risk ),即在训练集上的平均损失。
均方误差对参数 b b b做偏导得到:
∂ L ( y , y ^ ) ∂ b = 1 T ( X w + b − y ) ( 3 ) \frac{\partial \mathcal{L}(\boldsymbol{y}, \hat{y})}{\partial b}=\mathbf{1}^T(\boldsymbol{X} \boldsymbol{w}+\boldsymbol{b}-\boldsymbol{y})\quad(3) ∂b∂L(y,y^)=1T(Xw+b−y)(3)
∂ L ( y , y ^ ) ∂ w = ( X − x ˉ T ) T ( ( X − x ˉ T ) w − ( y − y ˉ ) ) ( 4 ) \frac{\partial \mathcal{L}(y, \hat{y})}{\partial w}=\left(X-\bar{x}^T\right)^T\left(\left(X-\bar{x}^T\right) w-(y-\bar{y})\right) \quad(4) ∂w∂L(y,y^)=(X−xˉT)T((X−xˉT)w−(y−yˉ))(4)
令上式等于零得到:
b ∗ = y ˉ − x ˉ T ( 5 ) b^*=\bar{y}-\bar{x}^T \quad(5) b∗=yˉ−xˉT(5)
w ∗ = ( ( X − x ˉ T ) T ( X − x ˉ T ) ) − 1 ( X − x ˉ − T ) T ( y − y ˉ ) ( 6 ) w^*=\left(\left(\boldsymbol{X}-\bar{x}^T\right)^T\left(\boldsymbol{X}-\bar{x}^T\right)\right)^{-1}\left(X-\bar{x}^{-T}\right)^T(y-\bar{y})\quad(6) w∗=((X−xˉT)T(X−xˉT))−1(X−xˉ−T)T(y−yˉ)(6)
1)此处省略了 1 N \frac{1}{N} N1并没有很大,经验风险是为了求解w和b的最优值,通过偏导为零的求解方法,式子前的常数并不影响最终的结果,可以将squared_loss函数的表达式改写就可以了
2)最小二乘法是用一个超平面去拟合点集,其本质是对误差函数的优化问题所以在这种简单的模型里解析法和梯度下降法都可以完成如2.2.5中看到的’
2.2.5模型训练
在这里只不过对于最优的参数值的求解方法不同
#代码来自李沐的书,这里的梯度下降用的Torch所以其实没有自己写梯度下降的过程
def synthetic_data(w, b, num_examples): """⽣成y=Xw+b+噪声"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]def sgd(params, lr, batch_size): """⼩批量随机梯度下降"""with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_()def derect_loss(y_hat,y):
'''直接误差'''return (y_hat - y.reshape(y_hat.shape))
#生成数据的w和
true_w = torch.tensor([2, -3.4,10,1.1])
true_b = 4.2
#生成数据和标签
features, labels = synthetic_data(true_w, true_b, 100)
features_test, labels_test = synthetic_data(true_w, true_b, 50)
#为w,b,学习率,小批量个数进行初始化,这里的requires_grad
w = torch.normal(0, 0.01, size=(4,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
lr = 0.03
num_epochs = 3
#选择线性回归模型和均方误差函数
net = linreg
loss = squared_loss
#训练
for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()#在这里w.grad和b.grad才有值得只有在调用.backward方法后w,b的grad才更新,为了下次的导数正确sgd里做了处理sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
#输出误差
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
w的估计误差: tensor([ 2.1696e-05, -2.4271e-04, 7.9155e-05, -3.3510e-04],grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0006], grad_fn=<RsubBackward1>)
可以看到这的w和b的反向传播函数并不相同,这两种方法在于对参数的求导的路径在Torch里实现的不同
2.2.6模型评估
for X, y in data_iter(100, features_test, labels_test):l = derect_loss(linreg(X, w, b), y) # X和y的小批量损失
l=l.reshape(1,-1)[0]
c=[]
for i in l:c.append(float(i))
print('y平均误差:'sum(c)/len(c))
tensor([[ 2.0000],[-3.4002],[ 9.9998],[ 1.0997]], requires_grad=True) tensor([4.1998], requires_grad=True)
epoch 10, loss 0.000049
len_features: 50
y平均误差:0.0008958221971988678
2.2.7样本数量&正则化系数
调整样本数量
features, labels = synthetic_data(true_w, true_b, 1000)
w的估计误差: tensor([-1.1110e-04, 4.1342e-04, -3.6240e-05, -2.4235e-04],grad_fn=<SubBackward0>)
b的估计误差: tensor([-0.0002], grad_fn=<RsubBackward1>)
对参数w加上ℓ2正则化,则最优的w∗变为
w ∗ = ( ( X − x ˉ T ) T ( X − x T ) + λ I ) − 1 ( X − x ˉ T ) T ( y − y ˉ ) ( 7 ) w^*=\left(\left(\boldsymbol{X}-\bar{x}^T\right)^T\left(\boldsymbol{X}-\boldsymbol{x}^T\right)+\lambda I\right)^{-1}\left(\boldsymbol{X}-\bar{x}^T\right)^T(y-\bar{y})\quad(7) w∗=((X−xˉT)T(X−xT)+λI)−1(X−xˉT)T(y−yˉ)(7)
上式是对于解析求解的时候用的比较多其实这里用的是 ∑ i = 1 n ( y i − y ^ ) 2 = ∑ i = 1 n ( y i − ∑ j = 1 k ( w j x i j ) − b ) 2 + λ ∑ j = 1 p w j 2 ( 8 ) \sum_{i=1}^n\left(y_i-\hat{y}\right)^2=\sum_{i=1}^n\left(y_i-\sum_{j=1}^k\left(w_j x_{i j}\right)-b\right)^2+\lambda \sum_{j=1}^p w_j^2\quad(8) i=1∑n(yi−y^)2=i=1∑n(yi−j=1∑k(wjxij)−b)2+λj=1∑pwj2(8)
调整正则化系数
def l2_squared_loss(y_hat,y,w,reg_lambda=2):#print(y_hat,y,w)return ((y_hat - y.reshape(y_hat.shape)) ** 2).sum() +reg_lambda*(w**2).sum()#将本来在loss之外的.sum()移动到里面方便计算
loss=l2_squared_loss
for epoch in range(num_epochs):for X, y in data_iter(batch_size,features, labels):l = loss(net(X, w, b), y,w,reg_lambda=2) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(features, w, b), labels,w,reg_lambda=2)print(w,b)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')#当然这里的mean()就是对一个数求和了改不改都行
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
tensor([[ 1.5925],[-2.7842],[ 8.1125],[ 0.8044]], requires_grad=True) tensor([4.0725], requires_grad=True)
epoch 10, loss 4022.816406
w的估计误差: tensor([ 0.4075, -0.6158, 1.8875, 0.2956], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.1275], grad_fn=<RsubBackward1>)
2.3多项式回归
多项式回归是回归任务的一种形式,其中自变量和因变量之间的关系是 M M M 次多项式的一种线性回归形式, 即:
f ( x ; w ) = w 1 x + w 2 x 2 + … + w M x M + b = w T ϕ ( x ) + b ( 9 ) f(\boldsymbol{x} ; \boldsymbol{w})=w_1 x+w_2 x^2+\ldots+w_M x^M+b=w^T \phi(x)+b\quad(9) f(x;w)=w1x+w2x2+…+wMxM+b=wTϕ(x)+b(9)
其中 M M M 为多项式的阶数, w = [ w 1 , … , w M ] T w=\left[w_1, \ldots, w_M\right]^T w=[w1,…,wM]T 为多项式的系数, ϕ = [ x , x 2 , ⋯ , x M ] ⊤ \phi=\left[x,x^2,\cdots,x^M\right]^{\top} ϕ=[x,x2,⋯,xM]⊤ 为多项式基函数,将原始特征 x x x映射为 M M M维的向量。当 M = 0 M=0 M=0 时, f ( x ; w ) = b f(x ; w)=b f(x;w)=b.
公式(2.10)展示的是特征维度为1的多项式表达,当特征维度大于1时,存在不同特征之间交互的情况,这是线性回归无法实现。公式(2.11)展示的是当特征维度为2,多项式阶数为2时的多项式回归: f ( x ; w ) = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 1 x 2 + w 5 x 2 2 + b ( 10 ) f(\boldsymbol{x} ; \boldsymbol{w})=w_1 x_1+w_2 x_2+w_3 x_1^2+w_4 x_1 x_2+w_5 x_2^2+b\quad(10) f(x;w)=w1x1+w2x2+w3x12+w4x1x2+w5x22+b(10)
当自变量和因变量之间并不是线性关系时,我们可以定义非线性基函数对特征进行变换,从而可以使得线性回归算法实现非线性的曲线拟合。
2.3.1数据集的构建
import math
def sin(x):y = torch.sin(2 * math.pi * x)return ydef synthetic_data(num_examples): #@save"""⽣成y=Xw+b+噪声"""X = torch.normal(0, 0.3, (num_examples, 1))y = sin(X)y += torch.normal(0, 0.001, y.shape)print(X,y)return X, y.reshape((-1, 1))
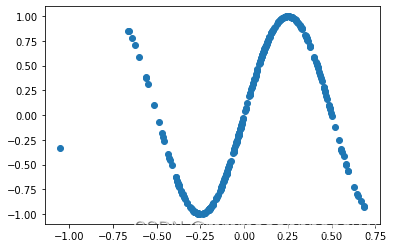
2.3.2模型的构建
def multinomial_func(x,w,b):'''多项式模型'''len_w=len(w)print(len_w)s_x_t=torch.tensor([],requires_grad=True)for i in range(len_w):x_lp=x**(i+1)s_x_t=torch.cat([s_x_t,x_lp],dim=1)y = torch.matmul(s_x_t,w)+breturn y
在这里将w的输入作为多项式的系数,直接决定输入多项式的阶数
2.3.4模型的评估
#初始化参数
w = torch.normal(0, 1, size=(5,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
lr = 0.03
loss=squared_loss
net=multinomial_func
loss=squared_loss
num_epochs=1
batch_size=10
#训练
for epoch in range(num_epochs):for X, y in data_iter(batch_size,train_features,train_labels):l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(train_features, w, b), train_labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')#画图
len_w=len(w)
x=torch.arange(-1,1,0.001);
y=x*float(w[0])
for i in range(1,len_w):print(i,'---',float(w[i])*x**(i+1))y+=float(w[i])*x**(i+1)
plt.scatter(train_features,train_labels)
plt.plot(x,y)
plt.show()
epoch 1, loss 0.226177
epoch 2, loss 0.352603
epoch 3, loss 0.191461
epoch 4, loss 0.268661
epoch 5, loss 0.264049
tensor([[ 5.1442],[-1.3861],[-7.7268],[-0.7148],[-2.8089]], requires_grad=True) tensor([0.0937], requires_grad=True)
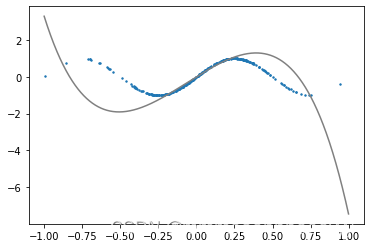
训练100轮:
tensor([[ 6.7778],[ -1.4367],[-31.4881],[ -0.3723],[ 26.5089]], requires_grad=True) tensor([4.1800], requires_grad=True)
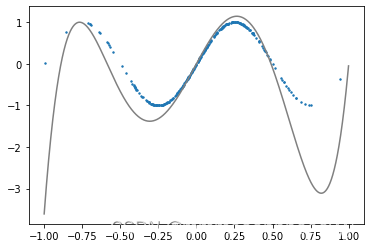
使用l2正则之后:
epoch 1, loss 0.180026
epoch 2, loss 0.181556
epoch 3, loss 0.193719
epoch 4, loss 0.219088
epoch 5, loss 0.157274
epoch 6, loss 0.168881
epoch 7, loss 0.109541
epoch 8, loss 0.108288
epoch 9, loss 0.125714
epoch 10, loss 0.099660
epoch 10, loss 0.099660
tensor([[ 2.4389],[ 1.0662],[-9.9077],[ 0.1167],[ 8.2819]], requires_grad=True) tensor([-0.2337], requires_grad=True)
效果反而会较差一些
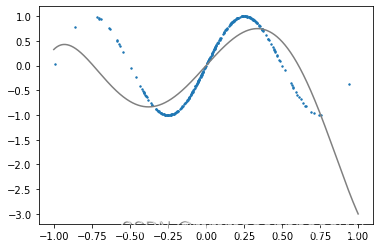
2.4Runner类
这里就修改邱锡鹏老师的代码:
import torch
import osclass Runner(object):def __init__(self, model, optimizer, loss_fn, metric):# 优化器和损失函数为None,不再关注# 模型self.model = model# 评估指标self.metric = metric# 优化器self.optimizer = optimizerdef train(self, dataset, reg_lambda, model_dir):X, y = datasetself.optimizer(self.model, X, y, reg_lambda)# 保存模型self.save_model(model_dir)def evaluate(self, dataset, **kwargs):X, y = datasety_pred = self.model(X)result = self.metric(y_pred, y)return resultdef predict(self, X, **kwargs):return self.model(X)def save_model(self, model_dir):if not os.path.exists(model_dir):os.makedirs(model_dir)params_saved_path = os.path.join(model_dir, 'params.pdtensor')torch.save(self.model.params, params_saved_path)def load_model(self, model_dir):params_saved_path = os.path.join(model_dir, 'params.pdtensor')self.model.params = torch.load(params_saved_path)2.5基于线性回归的波士顿房价预测
2.5.1数据处理
import pandas as pd
data=pd.read_csv("boston_house_prices.csv")
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222
4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222
.. ... ... ... ... ... ... ... ... ... ...
501 0.06263 0.0 11.93 0 0.573 6.593 69.1 2.4786 1 273
502 0.04527 0.0 11.93 0 0.573 6.120 76.7 2.2875 1 273
503 0.06076 0.0 11.93 0 0.573 6.976 91.0 2.1675 1 273
504 0.10959 0.0 11.93 0 0.573 6.794 89.3 2.3889 1 273
505 0.04741 0.0 11.93 0 0.573 6.030 80.8 2.5050 1 273 PTRATIO LSTAT MEDV
0 15.3 4.98 24.0
1 17.8 9.14 21.6
2 17.8 4.03 34.7
3 18.7 2.94 33.4
4 18.7 5.33 36.2
.. ... ... ...
501 21.0 9.67 22.4
502 21.0 9.08 20.6
503 21.0 5.64 23.9
504 21.0 6.48 22.0
505 21.0 7.88 11.9 [506 rows x 13 columns]
2.5.1.2数据清洗
print(data.isna().sum())#查看没个标签下的缺失值得情况
CRIM 0
ZN 0
INDUS 0
CHAS 0
NOX 0
RM 0
AGE 0
DIS 0
RAD 0
TAX 0
PTRATIO 0
LSTAT 0
MEDV 0
dtype: int64
#借鉴邱锡鹏
# 箱线图查看异常值分布
def boxplot(data, fig_name):# 绘制每个属性的箱线图data_col = list(data.columns)# 连续画几个图片plt.figure(figsize=(5, 5), dpi=300)# 子图调整plt.subplots_adjust(wspace=0.6)# 每个特征画一个箱线图for i, col_name in enumerate(data_col):plt.subplot(3, 5, i + 1)# 画箱线图plt.boxplot(data[col_name],showmeans=True,meanprops={"markersize": 1, "marker": "D", "markeredgecolor": '#f19ec2'}, # 均值的属性medianprops={"color": '#e4007f'}, # 中位数线的属性whiskerprops={"color": '#e4007f', "linewidth": 0.4, 'linestyle': "--"},flierprops={"markersize": 0.4},)# 图名plt.title(col_name, fontdict={"size": 5}, pad=2)# y方向刻度plt.yticks(fontsize=4, rotation=90)plt.tick_params(pad=0.5)# x方向刻度plt.xticks([])plt.savefig(fig_name)plt.show()num_features = data.select_dtypes(exclude=['object', 'bool']).columns.tolist()for feature in num_features:if feature == 'CHAS':continueQ1 = data[feature].quantile(q=0.25) # 下四分位Q3 = data[feature].quantile(q=0.75) # 上四分位IQR = Q3 - Q1top = Q3 + 1.5 * IQR # 最大估计值bot = Q1 - 1.5 * IQR # 最小估计值values = data[feature].valuesvalues[values > top] = top # 临界值取代噪声values[values < bot] = bot # 临界值取代噪声data[feature] = values.astype(data[feature].dtypes)
在处理完异常值之后:
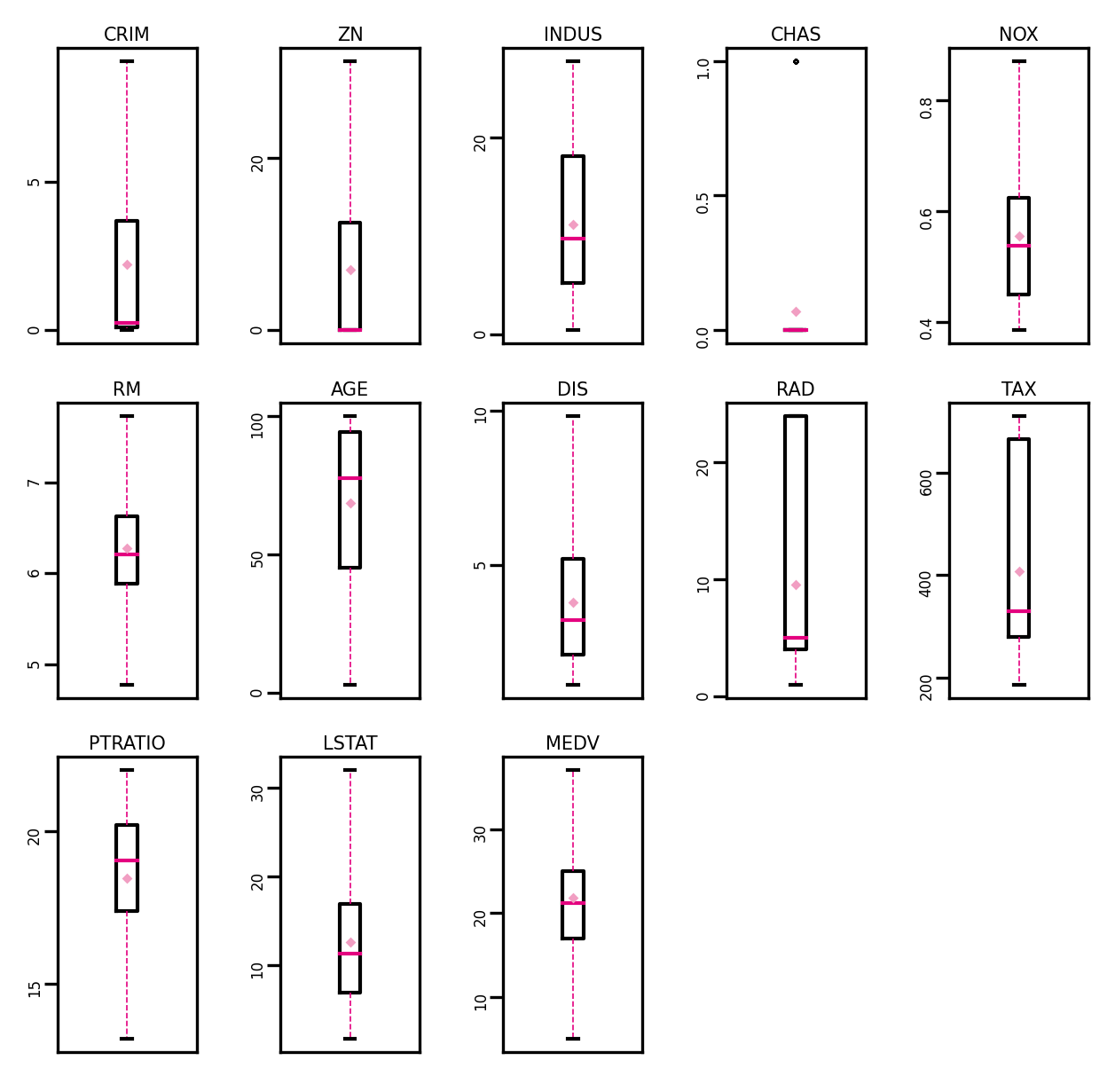
2.5.1.3数据集划分
def train_test_split(X, y, train_percent=0.8):n = len(X)shuffled_indices = torch.randperm(n) # 返回一个数值在0到n-1、随机排列的1-D Tensortrain_set_size = int(n * train_percent)train_indices = shuffled_indices[:train_set_size]test_indices = shuffled_indices[train_set_size:]X = X.valuesy = y.valuesX_train = X[train_indices]y_train = y[train_indices]X_test = X[test_indices]y_test = y[test_indices]return X_train, X_test, y_train, y_testX = data.drop(['MEDV'], axis=1)
y = data['MEDV']X_train, X_test, y_train, y_test = train_test_split(X, y) # X_train每一行是个样2.5.1.4特征工程
#特征工程
X_train = torch.tensor(X_train,dtype=torch.float32)
X_test = torch.tensor(X_test,dtype=torch.float32)
y_train = torch.tensor(y_train,dtype=torch.float32)
y_test = torch.tensor(y_test,dtype=torch.float32)X_min = torch.min(X_train,dim=0)[0]
X_max = torch.max(X_train,dim=0)[0]X_train = (X_train-X_min)/(X_max-X_min)
X_test = (X_test-X_min)/(X_max-X_min)# 训练集构造
train_dataset=(X_train,y_train)
# 测试集构造
test_dataset=(X_test,y_test)2.5.2模型构建
def linreg(X, w, b): #@save"""线性回归模型"""return torch.matmul(X, w) + b
2.5.2Runner类,算子
import torch
torch.manual_seed(10) #设置随机种子class Op(object):def __init__(self):passdef __call__(self, inputs):return self.forward(inputs)def forward(self, inputs):raise NotImplementedErrordef backward(self, inputs):raise NotImplementedError# 线性算子
class Linear(Op):def __init__(self, input_size):"""输入:- input_size:模型要处理的数据特征向量长度"""self.input_size = input_size# 模型参数self.params = {}self.params['w'] = torch.randn(size=[self.input_size, 1], dtype=torch.float32)self.params['b'] = torch.zeros(size=[1], dtype=torch.float32)def __call__(self, X):return self.forward(X)# 前向函数def forward(self, X):"""输入:- X: tensor, shape=[N,D]注意这里的X矩阵是由N个x向量的转置拼接成的,与原教材行向量表示方式不一致输出:- y_pred: tensor, shape=[N]"""N, D = X.shapeif self.input_size == 0:return torch.full(size=[N, 1], fill_value=self.params['b'])assert D == self.input_size # 输入数据维度合法性验证# 使用torch.matmul计算两个tensor的乘积y_pred = torch.matmul(X, self.params['w']) + self.params['b']return y_pred
2.5.4模型训练
lr = 0.03
num_epochs = 100
batch_size = 10
net = linreg
loss = squared_loss
w = torch.normal(0, 0.01, size=(12,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
print(w,b)
for epoch in range(num_epochs):for X, y in data_iter(batch_size,X_train, y_train):#print('load',X,y)l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数#print(w,b)with torch.no_grad():train_l = loss(net(X_train, w, b), y_train)print(w,b)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
tensor([[ -4.2613],[ 1.0628],[ 0.5212],[ 2.1252],[ -3.0859],[ 14.2895],[ -0.3103],[ -3.6776],[ 3.6394],[ -2.7991],[ -4.5872],[-10.7750]], requires_grad=True) tensor([24.1869], requires_grad=True)
epoch 100, loss 6.996277
2.5.5模型测试```python
for X, y in data_iter(batch_size,X_test, y_test):#print('load',X,y)l_x = loss(net(X, w, b), y)print(f'loss {float(l_x.mean()):f}')y=net(X,w,b)print(y)
loss 7.047848
tensor([[14.2231],[ 5.7950],[18.9050],[15.4746],[28.3919],[14.6761],[16.7302],[10.4911],[24.8447],[26.0152]], grad_fn=<AddBackward0>)
loss 2.432737
tensor([[19.2010],[20.0434],[24.9964],[14.2848],[35.3022],[27.2165],[26.8912],[18.1415],[26.5540],[19.6659]], grad_fn=<AddBackward0>)
loss 4.868561
tensor([[ 9.8344],[22.0588],[28.4817],[28.0053],[25.5395],[19.2421],[15.3564],[34.6426],[17.0798],[12.5536]], grad_fn=<AddBackward0>)
loss 2.791060
tensor([[22.6083],[26.6892],[16.5962],[22.2141],[23.9226],[22.1962],[17.9146],[30.6747],[24.2466],[21.9983]], grad_fn=<AddBackward0>)
loss 4.287356
.......
2.5.6模型预测
yy=y-y_test
yy=yy.reshape(-1,1)
xx=torch.arange(0,len(yy),1)
print(xx.detach().numpy(),'---',yy.detach().numpy())
plt.plot(xx.detach().numpy(),yy.detach().numpy())
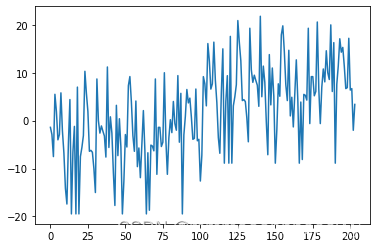
2.6感想
这些代码使用torch就是用的梯度下降算法,不得不说最主要的就是梯度下降的算法,干脆梯度下降也别用torch了呗,而梯度下降决定了网络可能的形状。
关于op和runner类我只是写了没用,主要是觉得缺点什么先放着
在多项式拟合的时候容易不收敛,对于不同的初始值不容易收敛到最优值,容易陷入局部值,不得说可能是参数量或者数据集不够的问题,感觉可以改改梯度下降。(瞎说的<_<)
这篇关于NNDL实验三的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









