本文主要是介绍云原生数据库极致弹性体验 - Amazon Aurora Serverless v2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
Aurora Serverless 是 Amazon Aurora 的按需自动扩展配置。Aurora Serverless v2 在几分之一秒内将数据库工作负载扩展到数十万个事务。它以细粒度的增量调整容量,为应用程序的需求提供适量的数据库资源。您无需管理数据库容量,只需为应用程序消耗的资源付费。早在2018年Amazon Aurora 即提供了 Serverless 选项。
Amazon Aurora 最新提供的 Aurora Serverless V2 版本相比于上一代 V1 版本更上一层楼,重点提升部分:资源容量采用原地扩展,使资源容量扩展速度由V1分钟级提升到秒级,v2 版本能够在容量调整时做到更细粒度, 以0.5 ACU作为扩展单元(V1翻倍扩展),并能够依据多个维度进行容量调整,通过持续的监控和尽可能大的利用缓冲池。Aurora Serverless v2 相比 V1 增加了完整的 Amazon Aurora 功能,包括多可用区支持、只读副本和全球数据库等,支持跨 AZ 和跨区域的高可用部署和读取扩展。
Amazon Aurora Serverless v2 非常适合各种应用程序。例如,面对业务快速增长场景与海量多租户场景时,当拥有数十万个应用程序的企业,或拥有具有成百上千个数据库的多租户环境的软件即服务 (SaaS) 供应商,可以使用 Amazon Aurora Serverless v2 来管理整个 SaaS 应用中众多数据库的容量,同时还适用于业务吞吐量波动明显的场景,如游戏业务、电商业务、测试环境等,以及无法预估吞吐量的新业务系统。对于大部分时间都处于低谷的业务系统,Amazon Aurora Serverless v2 可以有效地为客户节省成本。
作为新一代云原生无服务数据库, Aurora Serverless V2 提供了无与伦比弹性伸缩性, 动如脱兔;同时也提供了面向企业级应用的坚不可摧的高可用性,静若磐石。
本博客重点会围绕着 Aurora Serverless V2 的弹性伸缩和高可用特性,展开测试和分析,进一步向您展示 Aurora Serverless V2 的特点。
二、测试
2.1 扩展性测试
2.1.1 测试目标
-
Aurora Serverless V2 随负载变化的弹性伸缩能力
-
Aurora Serverless V2 与 V1弹性伸缩能力比较
Aurora Serverless 资源扩展以 ACU 为单位,关于ACU定义:
-
Aurora Capacity Unit (ACU)用于测量 Aurora Serverless 所分配资源容量
-
1个 ACU 有2 GiB 的内存,同时具有相应的 CPU 和网络等资源, CPU、网络和内存的配比与预置 Aurora 实例相同
-
Aurora Serverless V2启动容量可以最低设置成0.5 ACU(1 GiB 内存),最高 ACU 支持设置为128
2.1.2 测试结果和分析
模拟负载波峰波谷,采用 sysbench 读写负载,基于不同线程压测 10/100/50/600/10,每轮 压测120秒,观测在初始20秒 Aurora Serverless V2/V1资源扩展情况:

测试过程中 CloudWatch Dashboard 监控指标:
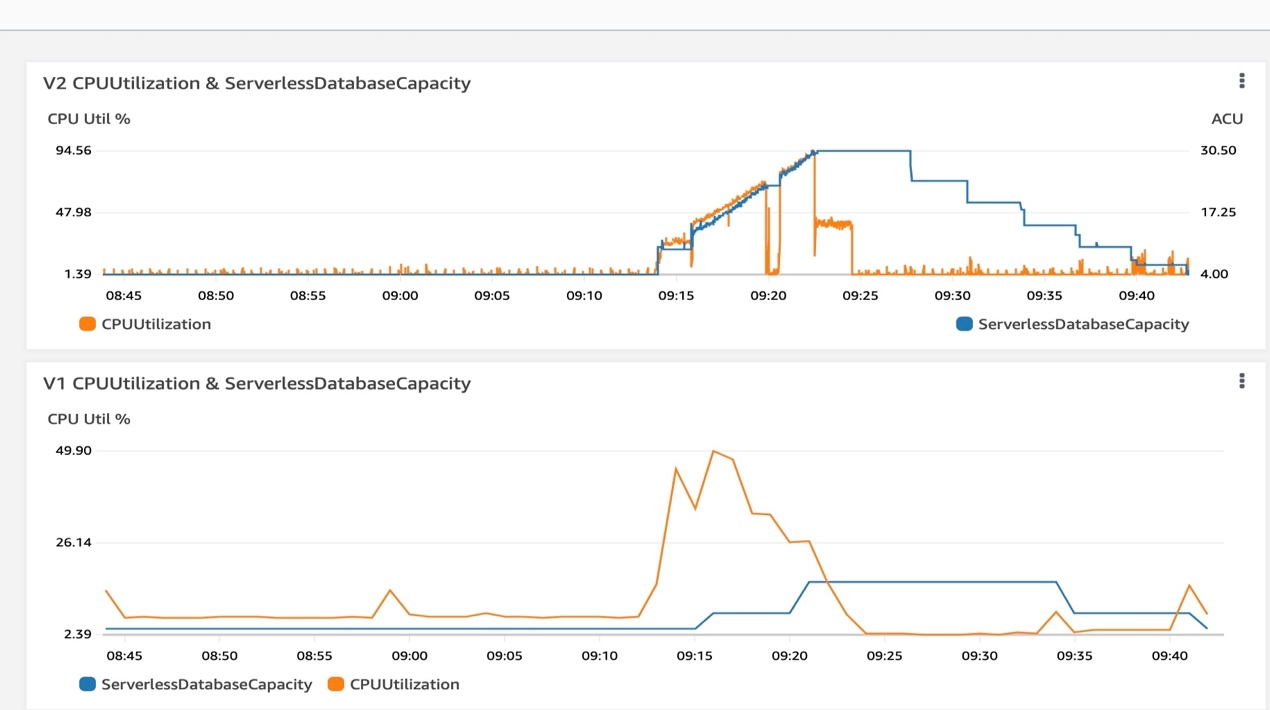
观测结果: V2 CPUUtilization与ServerlessDabaseCapacity 曲线拟合度非常高,ACU 值随着 CPU 指标变化而变化,特别是负载上升期间 CPU上升 ACU 可达到瞬间上升; CPU 下降时 ACU 值相对平稳下降
V1 ServerlessDabaseCapacity 扩展相对于 CPUUtilization 扩展有一定的延迟和滞后
V2/V1总体性能比较:
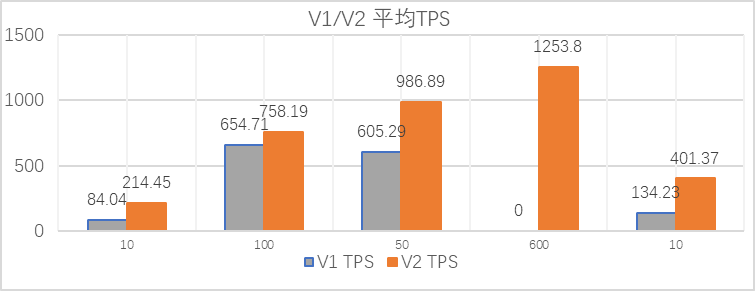
由于 Aurora Serverless V2 系统扩展更敏捷 负载上升 V2 始终获得比 V1 更高的资源配置(ACU)因而 Aurora Serverless V2 相比 V1 在不同压测场景 性能提升1.5-3 倍(TPS & QPS) 同时 V2 采用 MySQL 8.0 V1采用MySQL 5.7 版本不同 性能表现也会有所差异
扩展速度测试:
将 V2 Min ACU 设置成8 ACU 和4 ACU 查看 ACU 扩展速度是否有提升 测试负载 sysbench 读写 线程数采用恒定值100 运行15分钟
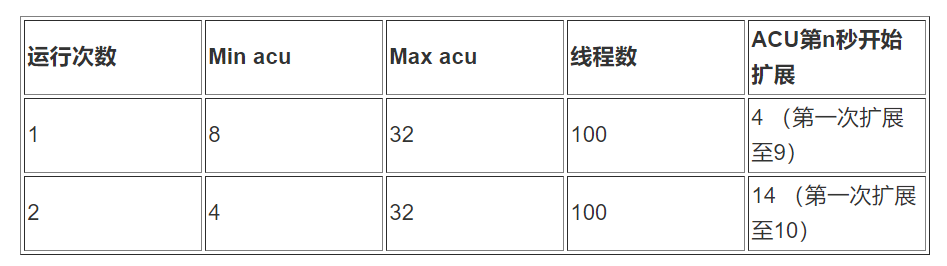
测试观察:
ACU 扩展速度 与Min ACU 或者当前数据库的 ACU 值相关 ACU 值越大 扩展速度越快
2.1.3扩展性测试总结
-
Aurora Serverless V2 采用即时原地扩展 随负载变化可实现敏捷扩展 实现秒级 ACU 扩展
-
实现细颗粒度资源扩展 以0.5ACU 为扩展单元
-
Aurora Serverless V2 ACU 资源扩展同时,其它相应资源, 例如数据库引擎缓存池 innodb_buffer_pool 也实现动态扩展
-
ACU 扩展速度 与min ACU 或者当前数据库的 ACU 值相关 ACU 值越大 扩展速度越快
-
Aurora Serverless V2 资源扩展速度敏捷 回缩相对平稳 以保障系统负载平稳支撑
-
Aurora Serverless V2 vs V1
-
体性能提升5-3倍
-
资源扩展速度提升10-15倍
-
扩展单元更细粒度
-
在高并发场景 可平稳运行
2.2读副本测试
Aurora Serverless V2 增加了读副本功能 可以通过增加读副本 最多可创建15个读副本 实现跨AZ容灾以及读负载扩展; Aurora Serverless V2 的高 failover 优先级读副本(Tier 0/1)ACU 会随着主节点 ACU 伸缩 从而保障在主从负载故障切换后 快速承载主节点负载;Aurora Serverless V2 低 failover 优先级读副本(Tier 2-15)ACU 不会随着主节点ACU伸缩 会依据自身实例负载实现资源 ACU 伸缩
2.2.1 测试目标
-
Aurora Serverless V2 tier 0/1 读副本是否会随着主节点 ACU 扩展而扩展
-
Aurora Serverless V2 tier 2-15 读副本负载是否会独立主节点而扩展
-
Aurora Serverless V2 主从节点切换时间
2.2.2 测试结果和分析
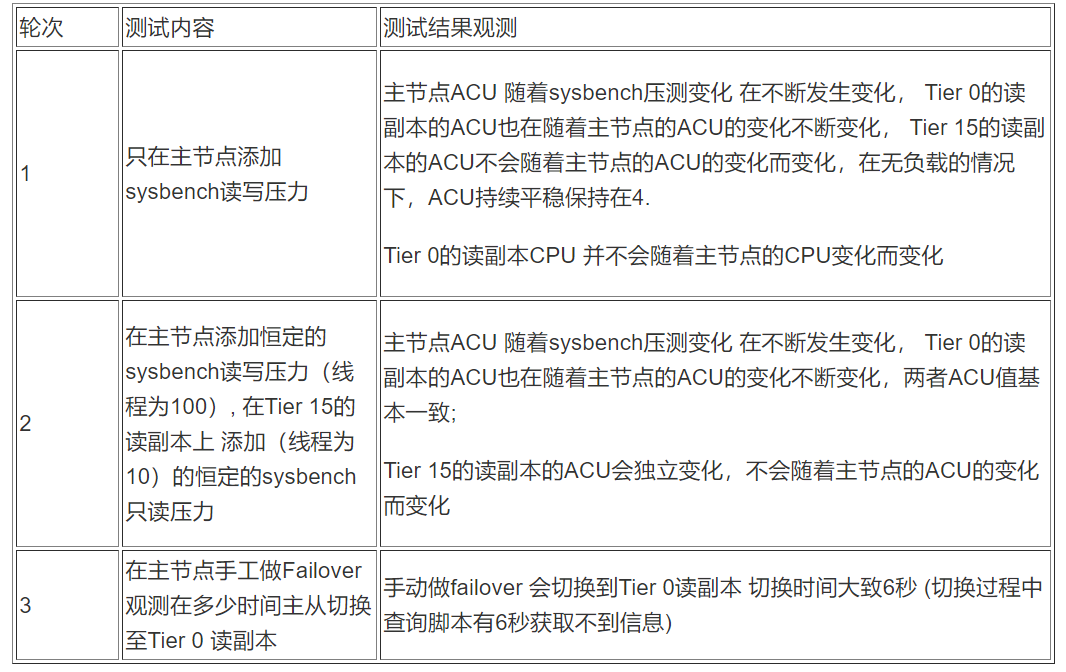
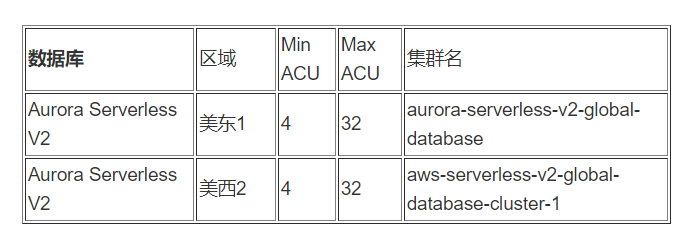
创建一主两从 Aurora Serverless V2集群 读副本 failover 级别分别为Tier 0和Tier 15 (Min ACU:4;Max ACU:32):
2.2.3读副本测试总结
-
Aurora Serverless V2 通过读副本 可实现跨AZ 高可用性 主从切换时间在秒级
-
Aurora Serverless V2 通过读副本 实现读负载的水平扩展
-
Tier 0/1 读副本的ACU也在随着主节点的 ACU 的变化不断变化 两者 ACU 值基本一致 可保障主从切换后 资源充足供应
-
Tier 2-15读副本读副本的 ACU 会独立变化,不会随着主节点的 ACU 的变化而变化
2.3 全球数据库测试
Aurora Serverless V2 增加了全局数据库功能 可以通过增加全局数据库 实现跨区域容灾以及就近本地读访问; 全球数据库采用物理复制方式以及通过亚马逊云科技跨区域主干网高效传输数据 使得跨区域数据复制延迟低 小于1秒;容灾发生时 可以在分钟级将从集群提升为主集群;一个主集群 可建最多达五个从集群 主从集群总共可以创建多达90个读副本
2.3.1 测试目标
-
Aurora Serverless V2 全球数据库: 主集群上运行读写负载 在从集群上运行只读负载 观测主从集群 ACU 变化
-
Aurora Serverless V2 全球数据库: 在主集群上运行高并发只写负载 在从集群上观测主从集群复制延迟
-
Aurora Serverless V2 全球数据库:执行 Managed Planned Failover 操作观测 Failover 所需要时间
2.3.2 测试结果和分析
主集群(4 ACU-32 ACU)在美东1
从集群 (4 ACU – 32 ACU)在美西2
2.3.3全球数据库测试总结
-
Aurora Serverless V2 通过全球数据库 可实现跨 Region 高可用性 主从切换时间在分钟级
-
Aurora Serverless V2 通过全球数据库实现跨区域容灾和就近数据访问
-
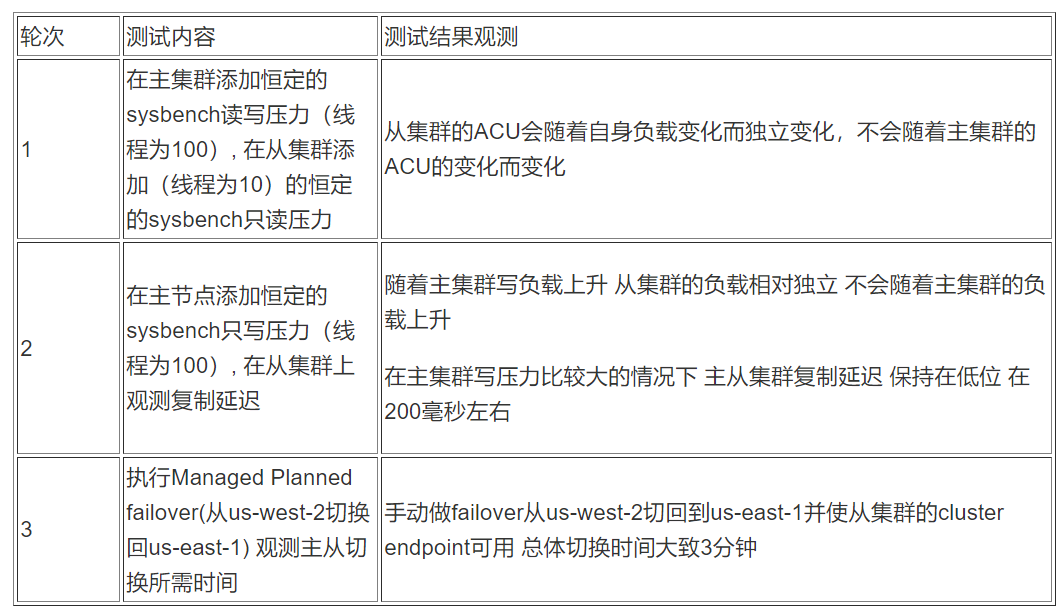
从集群的ACU会随着自身负载变化而独立变化,不会随着主集群的 ACU 的变化而变化
-
主从集群复制延迟比较低 通常保持在200毫秒左右
三、迁移数据库到 Aurora Serverless V2
3.1 选择 Aurora Serverless V2 的理由
选择Aurora Serverless V2 有众多益处, 以下从四个方面概括阐述选择Aurora Serverless V2的理由:
-
高度可扩展
创新的云原生无服务数据库,实现数据库的弹性伸缩,进一步简化客户创建、维护和扩展数据库,实现高度扩展性及自动伸缩容量。
Amazon Aurora Serverless v2 采用即时原地扩展技术,在扩展性方面比上一代更上一层楼,可以立即扩展以支持最苛刻的应用程序,瞬间扩展不到一秒时间,即可将数据库工作负载由支持几百个事务扩展至支持数十万个事务。
-
提供面向企业级应用高可用性
Aurora Serverless V2 提供所有的 Aurora 功能,包括回溯、克隆、全球数据库、多可用区部署以及只读副本等,满足业务关键型应用程序的需求,可以通过创建只读副本实现跨多可用区高可用性,实现秒级跨可用区故障切换;可以通过创建全球数据库实现跨区域高可用性,实现分钟级跨区域故障切换,可提供面向企业级应用高可用性。
-
易管理
Aurora Serverless V2 可按需自动扩展,根据应用程序的需求自动扩展或缩减容量,简化客户创建、维护和扩展数据库, 不再需要进行复杂的数据库容量预置和管理, 数据库会根据应用程序的需求自动扩展资源。
-
经济高效
Aurora Serverless V2 可以以细粒度的0.5 ACU 增量资源扩展,确保恰好提供应用所需的数据库资源量,并且仅为使用的容量付费,同时 Aurora Serverless V2 可按秒计费, 实现更细粒度计费模式。
3.2 如何迁移数据库到 Aurora Serverless V2
版本要求:
Aurora Serverless V2 MySQL: Aurora MySQL 3.0.2及以上 (兼容MySQL 8.0)
Aurora Serverless V2 PostgreSQL: Aurora PostgreSQL 13.6及以上
迁移:
迁移场景1: 将预置模式 Aurora 集群迁移到 Aurora Serverless V2
Aurora Serverless V2 支持集群里采用灵活的混合配置架构, 即主节点可以是预置模式实例, 读节点是 Aurora Serverless V2实例; 同时也支持主节点是 Aurora Serverless V2 实例, 读节点是 Aurora 预置模式实例
迁移方法:创建 Aurora Serverless V2 混合配置架构 通过主从切换将预置模式主节点实例转换成 Aurora Serverless V2 实例:
-
将 Aurora 预置模式主节点升级到 Aurora Serverless V2 所需版本
-
在集群级别设置 Min ACU 和 Max ACU
-
增加实例类型为 Serverless 读副本 (Failover 级别:Tier 0/1)
-
执行主从切换: Provisioned Writer变成Provisioned Reader; Serverless Reader 变成 Serverless Writer
迁移场景2: 将 Aurora Serverless V1 迁移到 Aurora Serverless V2
迁移方法:通过创建快照迁移
-
基于 Aurora Serverless V1 创建快照
-
基于快照恢复预置 Aurora 集群
-
将 Aurora 预置模式主节点升级到 Aurora Serverless V2 所需版本
-
在集群级别设置 Min ACU 和 Max ACU
-
增加实例类型为 Serverless 读副本 (Failover 级别:Tier 0/1)
-
执行主从切换: Provisioned Writer 变成 Provisioned Reader; Serverless Reader 变成 Serverless Writer
四、总结
本博客重点展示了 Aurora Serverless V2 作为新一代云原生数据库特点:高度可扩展性-动如脱兔,以及面向企业级应用高可用性-静若磐石;当云原生数据库 Aurora 深度融合无服务,必将数据库创新做到极致!
希望读完此博客的您, 能即刻构建,享用 Aurora Serverless V2 的创新,来构建您的面向未来的创新的现代化应用。点击了解云原生数据库精英班正式课程精彩内容。
五、附录:整体测试过程
5.1测试环境
创建和安装两台 EC2测试机 :
测试区域:us-east-1
测试端:
两台C5 4XLarge: AMI amzn2-ami-hvm (Root Device 100g)
安装和配置 sysbench:
在两台 EC2 测试机上 分别安装 sysbench
sudo yum -y install git gcc make automake libtool openssl-devel ncurses-compat-libs
sudo yum -y install https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
sudo yum repolist
sudo rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
sudo yum -y install mysql-community-devel mysql-community-client mysql-community-common
git clone https://github.com/akopytov/sysbench
cd sysbench
./autogen.sh
./configure
make
sudo make install
sysbench --version5.2扩展性测试
5.2.1 测试环境准备
测试环境:
测试端
之前安装 sysbench 的两台 EC2 C5 4XLarge

准备 sysbench 数据
-
分别在两台 EC2 压测机准备 sh 设置相关环境变量
host=<Aurora Serverless V2/V1 endpoint>
username=<master user name>
password=<password>
run_time=200
interval=1执行:
source set_variables.sh
-
在 Aurora Serverless V2 和 V1 库上 分别创建测试数据库 demo
create database demo
-
Sysbench 准备数据500张表 每张表5万行 总共5GB 数据
-
检查测试表状态和数据 总体测试数据5GB
/usr/bin/mysqlcheck -u ${username} -p${password} -h ${host} -P 3306 -a -B demo--Connect and query table sizes
/usr/bin/mysql -u ${username} -p${password} -h ${host} -P 3306SELECT TABLE_SCHEMA, count(TABLE_NAME) AS "Table count",sum(DATA_LENGTH/1024/1024/1024) AS "Data size in GB" FROM INFORMATION_SCHEMA.TABLESWHERE TABLE_SCHEMA='demo' GROUP BY TABLE_SCHEMA;创建 Cloudwatch Dashboard 为后续测试监控做准备:
Name: Aurora Serverless Monitor
在 Dashboard Aurora Serverless Monitor 创建6个 Widgets:
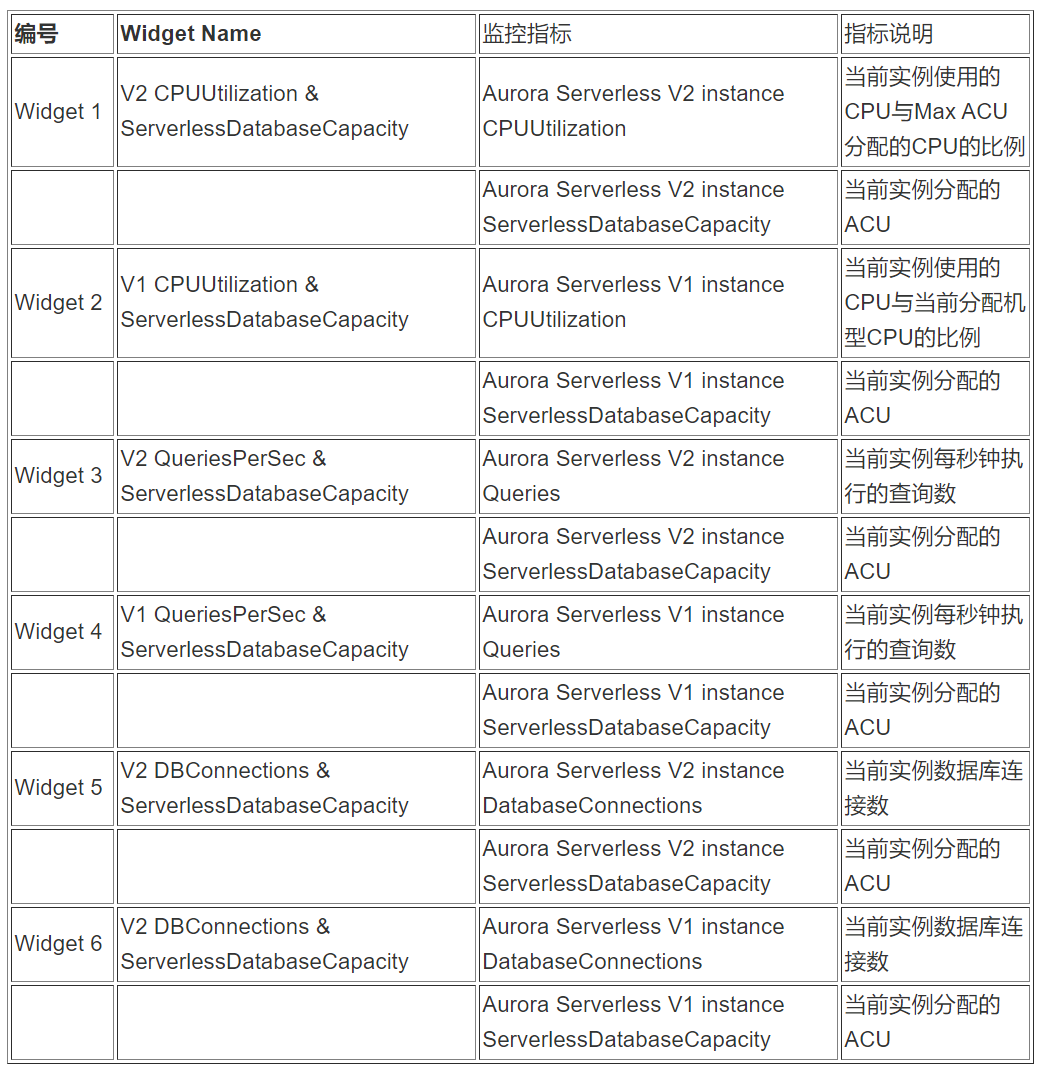
5.2.2测试
1、分别在两台 Ec2压测机上 准备 sysbench 压测脚本 读写测试 基于不同线程压测 10/100/50/600/10 不同线程规格压测120秒(2分钟) 每秒钟打印统计信息
$ cat sysbench_read_write.sh
#!/bin/bash
host= <Aurora Serverless V2/V1 endpoint>(请替换)
username=admin
password=<password>
interval=1
run_time=120
for threads in 10 100 50 600 10
do
echo "start ......................... `date` "
sysbench --db-driver=mysql --mysql-user=${username} --mysql-password=${password} --mysql-db=demo --mysql-host=${host} --mysql-port=3306 --tables=500 --table-size=50000 --time=${run_time} --forced-shutdown --rand-type=uniform --db-ps-mode=disable --report-interval=${interval} --threads=${threads} /usr/local/share/sysbench/oltp_read_write.lua run
echo "end ......................... `date` "
done/2、分别在两台 Ec2压测机 准备监控脚本 每秒钟监控数据库动态变量 (innodb_buffer_pool_size和max_connections)
$ cat stats-loop.sh
host=< Aurora Serverless V2/V1 endpoint >
username=<master user name>
export MYSQL_PWD=<password>while true; do /usr/bin/mysql -u ${username} -h ${host} -P 3306 -e "select NOW() AS 'Time',
@@max_connections AS 'Max Connections',
COUNT(host) as 'Current Connections',
round(@@innodb_buffer_pool_size/1024/1024/1024,2) AS 'Innodb Buffer Pool Size (GiB)',
COUNT AS 'InnoDB history length'
From information_schema.innodb_metrics,
information_schema.processlist
where name='trx_rseg_history_len'"; sleep 1; done3、运行 Amazon configure 配置 id/key/region 为后续 Amazon cli 运行做准备
4、分别在两台 Ec2压测机 准备监控脚本 每秒钟监控数据库 ACU
$ cat stats-loop-acu.sh
cluster_name="aurora-serverless-v2-demo" (请替换成你的Aurora Serverless V2集群名字)
export LC_ALL=Cwhile true; do
aws cloudwatch get-metric-statistics —metric-name "ServerlessDatabaseCapacity" \
--start-time "$(date -d '5 sec ago')" —end-time "$(date -d 'now')" —period 1 \
--namespace "AWS/RDS" \
--statistics Average \
--dimensions Name=DBClusterIdentifier,Value=$cluster_name
sleep 1; done5、分别在两台 Ec2压测机 调用 sysbench 压测脚本 分别对 Aurora Serverless V2/V1 进行线程10/100/50/600/10压测 每轮压测执行120秒 每秒钟跟踪 Aurora Serverless V2/V1 数据库的 Innodb_buffer_pool_size 和 max_connections 大小 同时每秒钟跟踪 Aurora Serverless V2/V1 数据库分配的 ACU (整体测试运行3次)
$ cat run_sysbench.sh
sh sysbench_read_write.sh > $1_$2_sysbench.log &
sh stats-loop.sh > $1_$2_buffer_pool.log &
sh stats-loop-acu.sh > $1_$2_acu.log &
$1 – 参数1=V2/V1 (代表在V2还是V1上运行)
$2 – 参数2 = 1/2/3 (代表第几次执行)
示例:sh run_sysbench.sh 2 1 (表示针对Aurora Serverless V2 做第一轮测试) 测试输出三个log格式:v2_1_sysbench.log/v2_1_buffer_pool.log/v2_1_acu.logsysbench 整体测试结束后 从上面三个监控logs(sysbench.log/buffer_pool.log/acu.log) 整理每轮线程压测 前20秒信息 来进一步分析 Aurora Serverless V2 在系统负载变化时 是否可以实现按需敏捷扩展
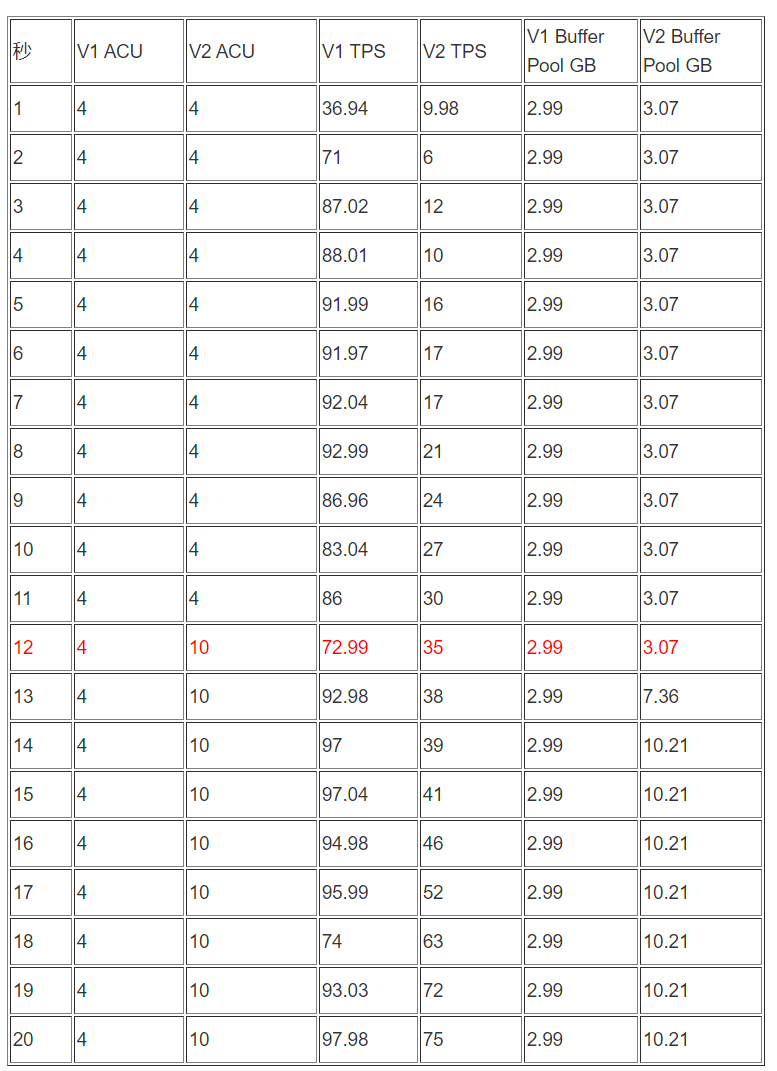
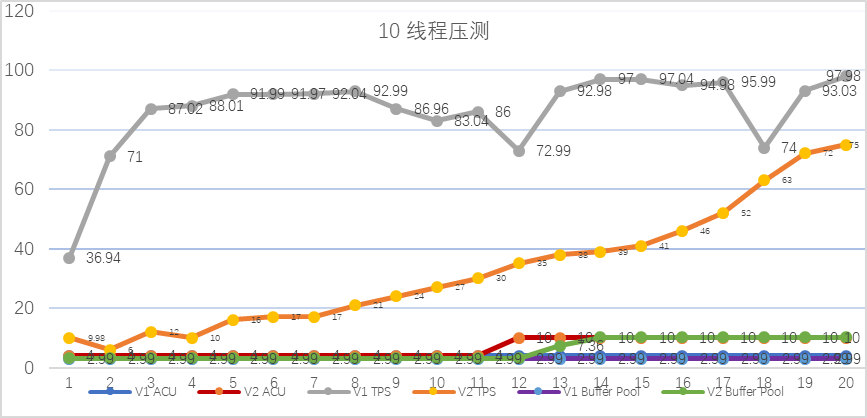
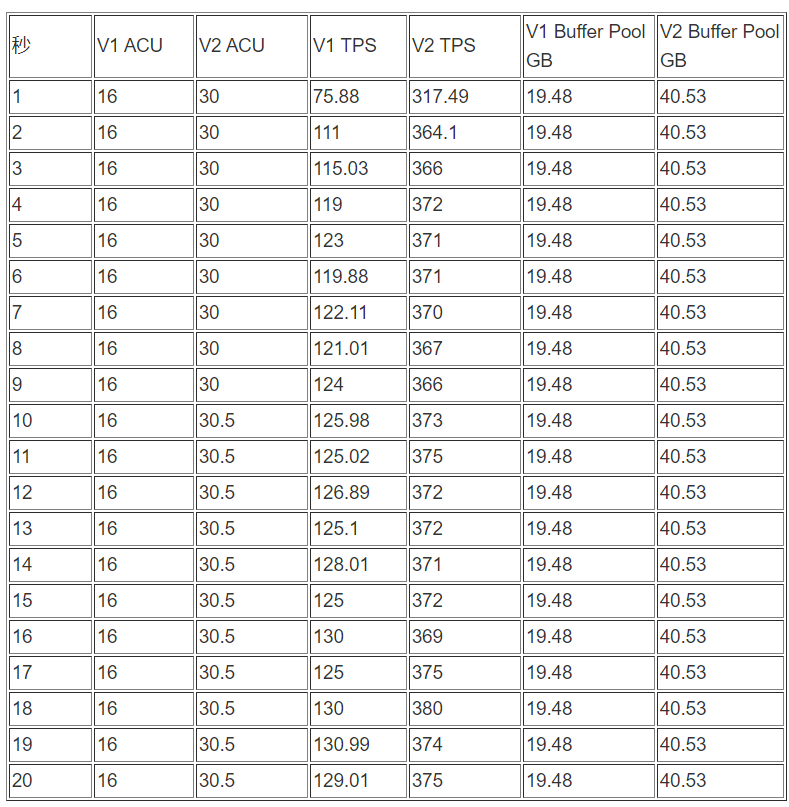
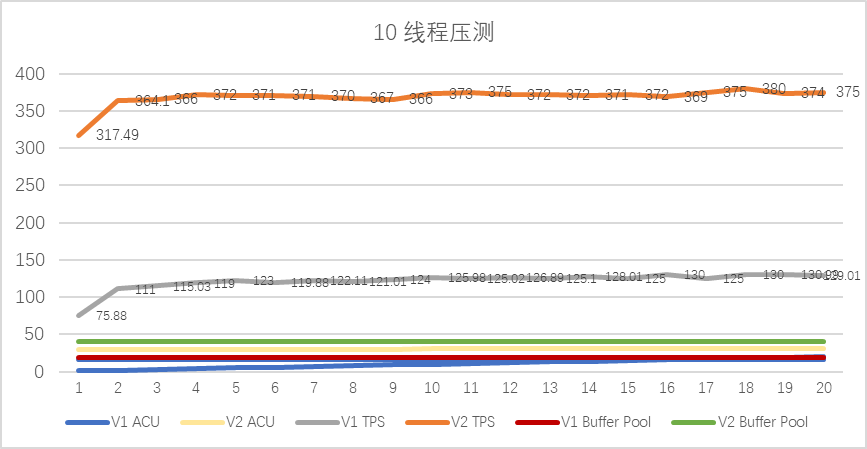
sysbench 线程10压测 :
-
测试数据整理(前20秒)
sysbench 线程100压测:
-
测试数据整理(前20秒)
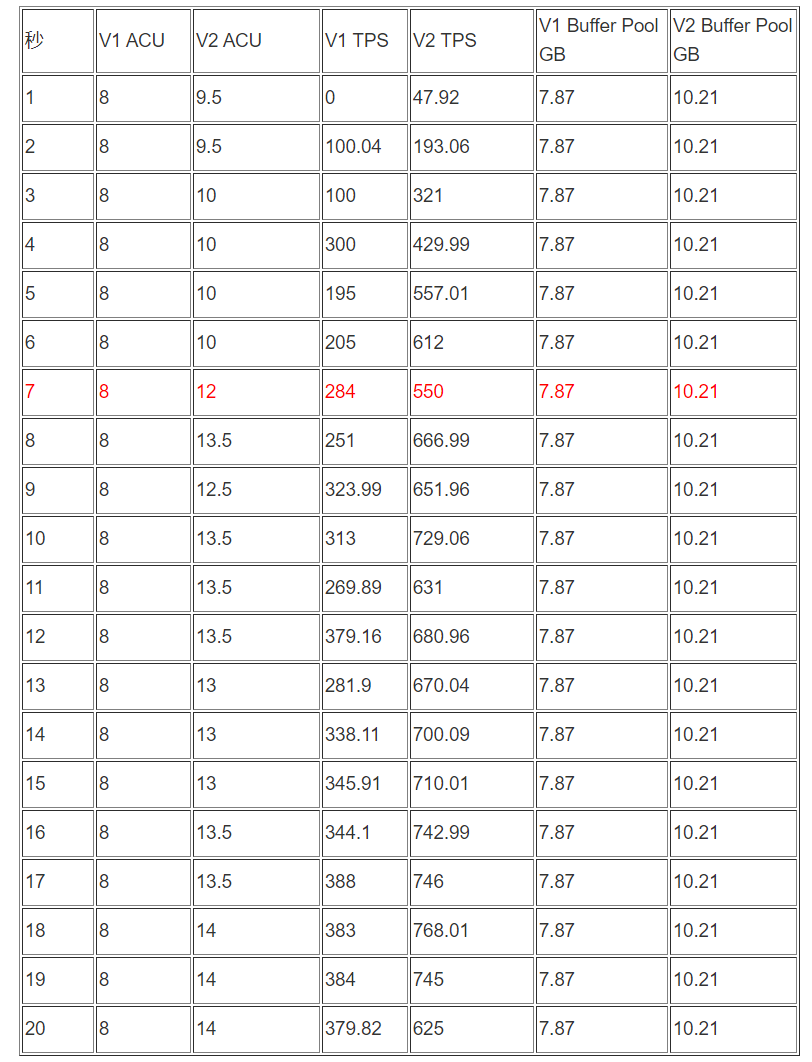
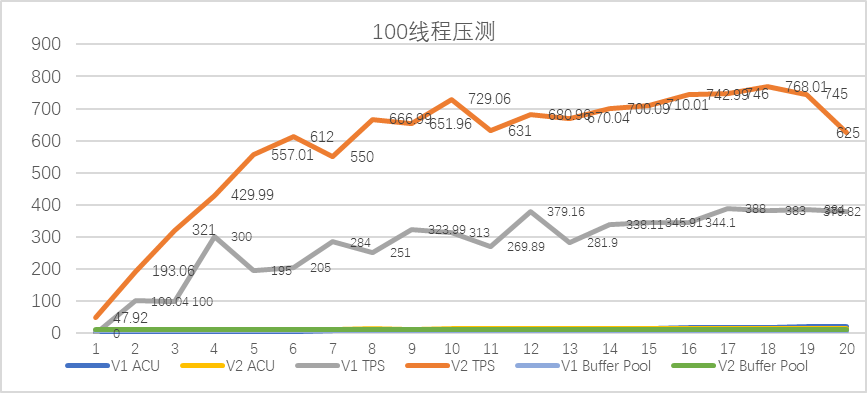
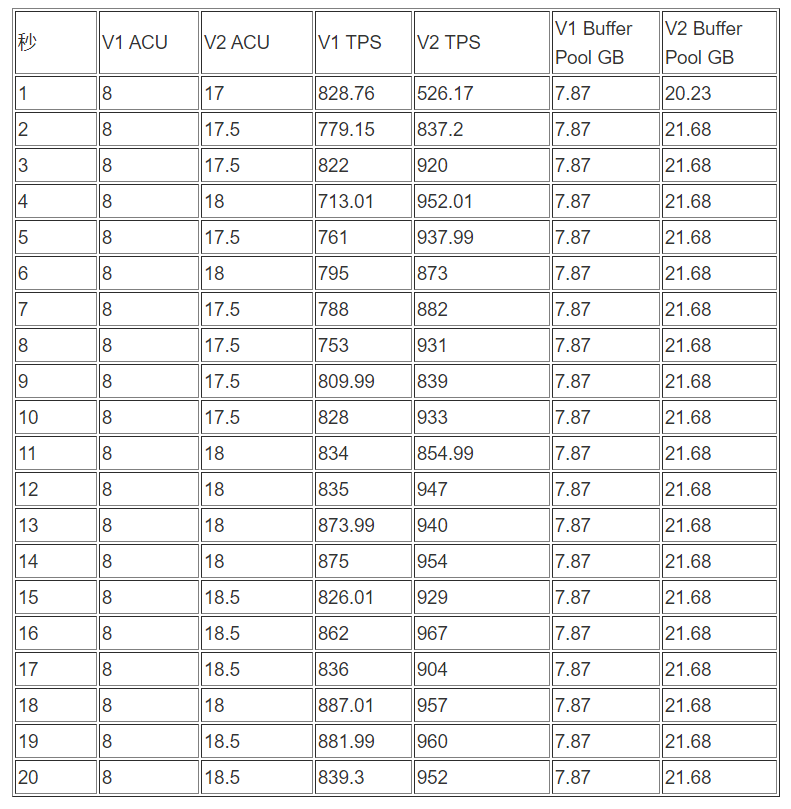
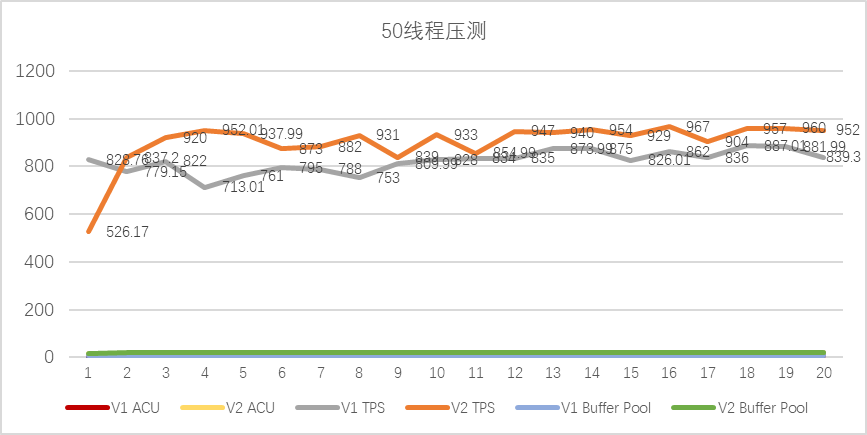
sysbench 线程50压测 :
-
测试数据整理(前20秒)
sysbench 线程600压测 :
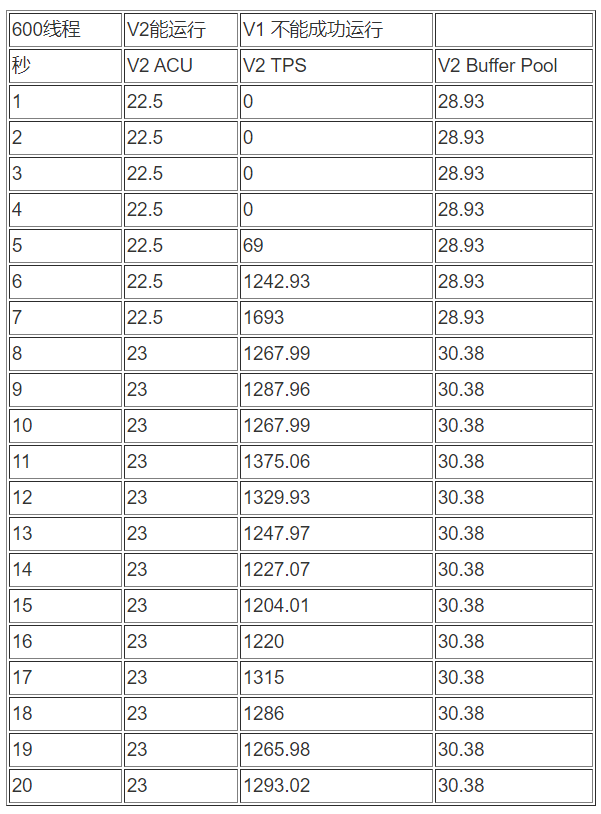
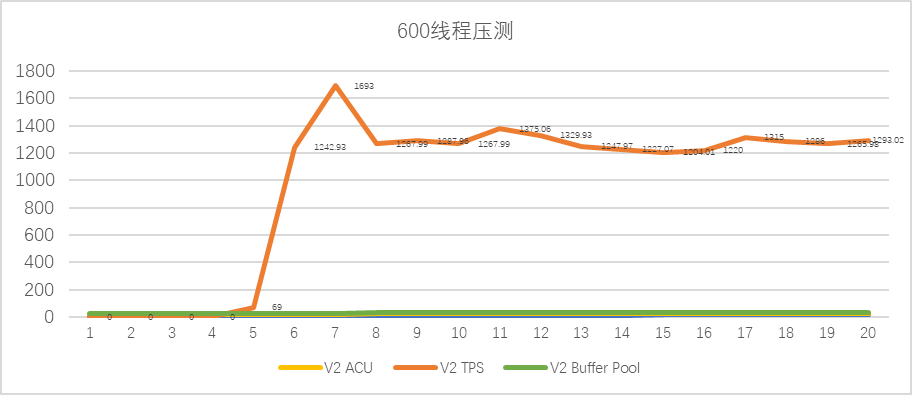
sysbench 线程10压测:
测试期间 CloudWatch Dashboard 监控指标:

观测结果: V2 CPUUtilization与ServerlessDabaseCapacity 曲线拟合度非常高 ACU 值随着 CPU 指标变化而变化 特别是负载上升期间 CPU 上升 ACU 可达到瞬间上升; CPU 下降时 ACU 值相对平稳下降
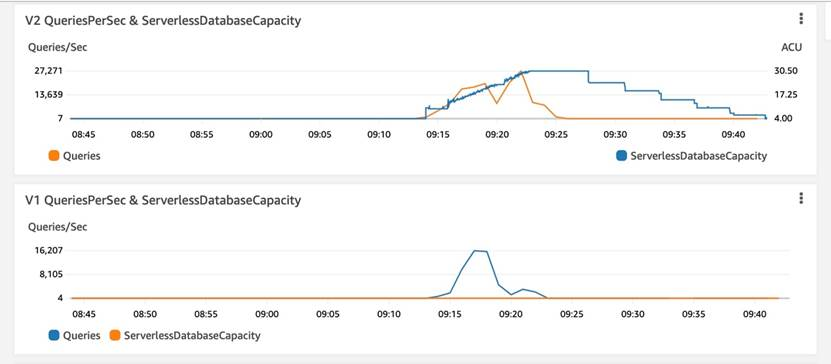
观测结果: V2 QueriesPerSec与ServerlessDabaseCapacity 曲线拟合度比较高
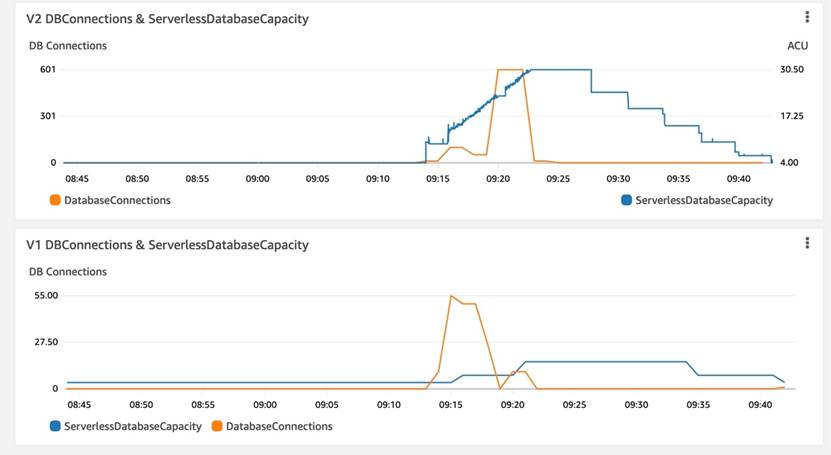
观测结果: V2 DBConnections与ServerlessDabaseCapacity 曲线拟合度比较高
5.3读副本测试
5.3.1 测试环境准备
测试环境:
测试端
之前安装的 Aurora Serverless V2 测试机: EC2 C5 4XLarge
创建一主两从 Aurora Serverless V2 集群 读副本 failover 级别分别为 Tier 0 和 Tier 15:

准备 sysbench 数据:
连接到主节点 create demo database 准备 sysbench 测试数据 (500张表 每张表5万条记录 总共5GB 数据)(具体步骤请参照上章测试)
创建Cloudwatch Dashboard 为后续测试监控做准备:
Dashboard Name: Aurora-Serverless-v2-reader
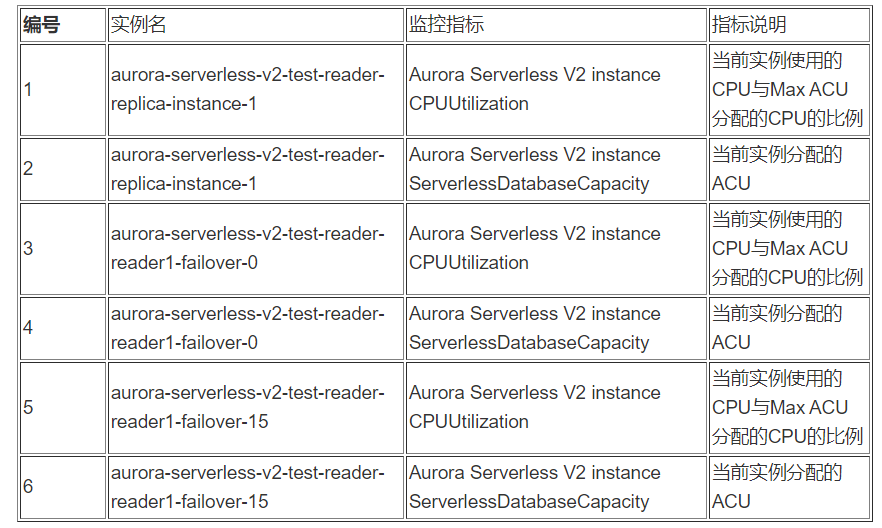
测试负载:
-
sysbench 读写负载 (具体测试脚本 请参照上章测试)
-
sysbench 只写负载 (请参考以下所附脚本)
-
sysbench 只读负载 (请参考以下所附脚本)
sysbench 只写负载:(循环执行sysbench 只写负载 每次执行10分钟)
$ cat same_sysbench_only_write.sh
host="请替换成你的Aurora Endpoint "
username="admin"
password="****"
interval=1
run_time= 600
threads=$1
while true
do echo $threads
echo "start ......................... `date` "
sysbench --db-driver=mysql --mysql-user=${username} --mysql-password=${password} --mysql-db=demo --mysql-host=${host} --mysql-port=3306 --tables=500 --table-size=50000 --time=${run_time} --forced-shutdown --rand-type=uniform --db-ps-mode=disable --report-interval=${interval} --threads=${threads} /usr/local/share/sysbench/oltp_write_only.lua run
echo "end ......................... `date` "
sleep 1
donesh same_sysbench_only_write.sh 100 (参数为并发线程数)sysbench 只读负载:(循环执行 sysbench 只读负载 每次执行10分钟)
$ cat same_sysbench_only_read.sh
host="请替换成你的Aurora Endpoint"
username="admin"
password="******"
interval=1
run_time=600
threads=$1
while true
do
echo "start ......................... `date` "
sysbench --db-driver=mysql --mysql-user=${username} --mysql-password=${password} --mysql-db=demo --mysql-host=${host} --mysql-port=3306 --tables=500 --table-size=50000 --time=${run_time} --forced-shutdown --rand-type=uniform --db-ps-mode=disable --report-interval=${interval} --threads=${threads} /usr/local/share/sysbench/oltp_read_only.lua run
echo "end ......................... `date` "
sleep 1
done
sh same_sysbench_only_read.sh 100 (参数为并发线程数)5.3.2测试
测试场景1:
测试: 只在主节点添加 sysbench 读写压力:
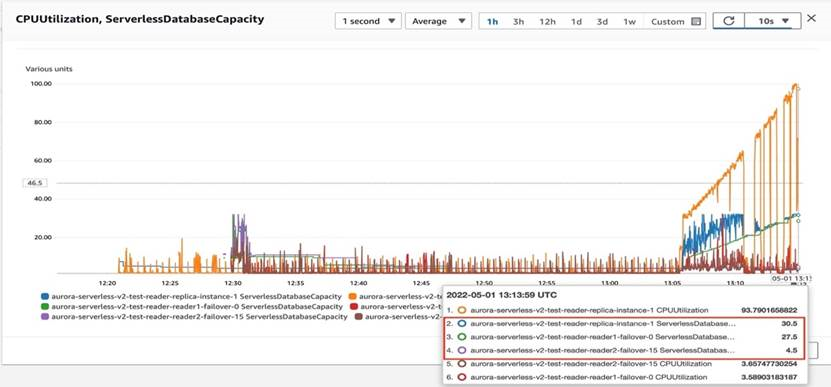
测试场景2:
测试: 在主节点添加恒定的sysbench读写压力(线程为100), 在 Tier 15的读副本上 添加(线程为10)的恒定的 sysbench 只读压力:
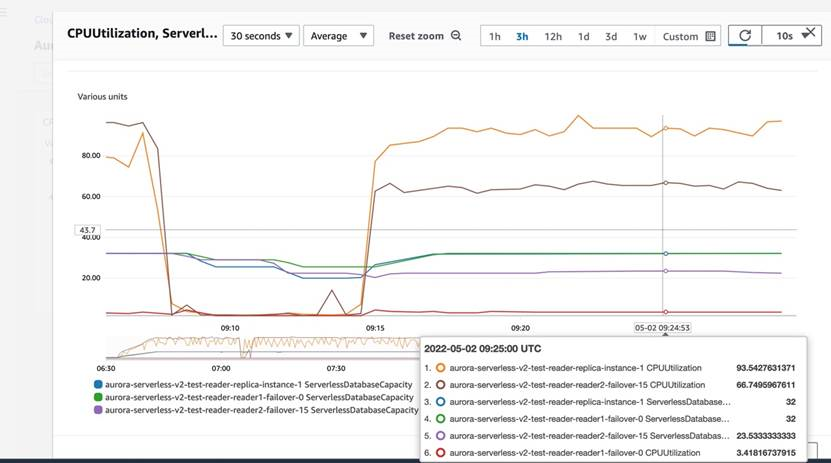
测试场景3:
测试: 在主节点手工做Failover 观测在多少时间主从切换至Tier 0 读副本:

5.4全局数据库 测试
5.4.1 测试环境准备
测试环境:
测试端
-
之前美东1安装的 Aurora Serverless V2 测试机: EC2 C5 4XLarge
-
美西2 新安装的 Aurora Serverless V2 测试机: EC2 C5 4XLarge 安装 sysbench 测试软件 (具体步骤 请参照前面章节)
数据库环境
-
主集群(4 ACU-32 ACU)在美东1
-
从集群 (4 ACU – 32 ACU)在美西2
准备 sysbench 数据:
连接到主集群主节点 create demo database 准备sysbench测试数据 (500张表 每张表5万条记录 总共5GB数据)(具体步骤请参照前面章节)
创建 Cloudwatch Dashboard 为后续测试监控做准备:
Dashboard Name: Aurora-Serverless-v2-reader
测试负载:
-
sysbench 读写负载 (具体测试脚本 请参照前面章节)
-
sysbench 只写负载 (具体测试脚本 请参照前面章节)
-
sysbench 只读负载 (具体测试脚本 请参照前面章节)
5.4.2 测试
测试场景1:
测试: 在主集群添加恒定的 sysbench 读写压力(线程为100), 在从集群添加(线程为10)的恒定的 sysbench 只读压力:

测试场景2:
测试:在主节点添加恒定的 sysbench 只写压力(线程为100), 在从集群上观测复制延迟:
测试场景3:
测试: 执行Managed-failover(从us-west-2切换回us-east-1) 观测主从切换所需时间:
-
连接到从集群 cluster endpoint 持续运行脚本查询集群的 max_connections 信息 (请参照前面章节查询脚本)
-
在主集群上 手动做 managed-failover 操作
-
记录 failover 操作发生时间
-
观测大致经过有多少时间 从集群能查询到信息

本篇作者
Bingbing liu
刘冰冰,亚马逊云科技数据库解决方案架构师,负责基于亚马逊云科技的数据库解决方案的咨询与架构设计,同时致力于大数据方面的研究和推广。在加入亚马逊云科技之前曾在 Oracle 工作多年,在数据库云规划、设计运维调优、DR 解决方案、大数据和数仓以及企业应用等方面有丰富的经验。
这篇关于云原生数据库极致弹性体验 - Amazon Aurora Serverless v2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







