本文主要是介绍关于“文档图像前沿技术探索 —多模态及图像安全”专题报告分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- ⭐️前言
- ⭐️多模态模型进展与探索
- ⭐️LLM时代文档图像处理技术
- ⭐️知名文档图像大模型OCR性能分析
- ⭐️图像安全
- ⭐️图像篡改检测
- ⭐️AIGC判别
- ⭐️标准制定
- ⭐️合合信息
- ⭐️总结
⭐️前言
10月14日第六届中国模式识别与计算机视觉大会在厦门举办。PRCV 2023由中国计算机学会(CCF)、中国自动化学会(CAA)、中国图象图形学学会(CSIG)和中国人工智能学会(CAAI)联合主办,厦门大学承办,是国内顶级的模式识别和计算机视觉领域学术盛会,CCF推荐会议(C类)。 本届会议主题为“相约鹭岛,启智未来”。会议旨在汇聚国内国外模式识别和计算机视觉理论与应用研究的广大科研工作者及工业界同行,共同分享我国模式识别与计算机视觉领域的最新理论和技术成果。
PRCV2023共设5个大会主旨报告,8个特邀报告、32个口头报告,9个专题论坛,7个讲习班,共接收投稿论文1420篇,最终录取论文532篇。本文分享给大家由合合信息智能技术平台事业部副总经理郭丰俊博士带来的企业报告:“文档图像前沿技术探索 —多模态及图像安全”。
⭐️多模态模型进展与探索
多模态模型是指能够处理多种不同类型数据的模型,例如图像、文本、语音等。在过去几年中,随着深度学习技术的发展,多模态模型在计算机视觉、自然语言处理、语音识别等领域得到了广泛应用。在本次专题报告上,郭博士首先介绍了文档图像在多模态大模型方向上的一些探索。
文档图像从字面上看就是文字+图像,所以它天然的就是一个多模态属性。如下面这张本次中国模式识别与计算机视觉大会的海报,从这个海报可以看出文字本身其实也有图像属性,我们的汉字从外观来看也是一个图形,是一种象形文字。所以在对文档图像处理时首先会想到多模态大模型,现在也一直在思考怎么把多模态这个技术引入到OCR里面。

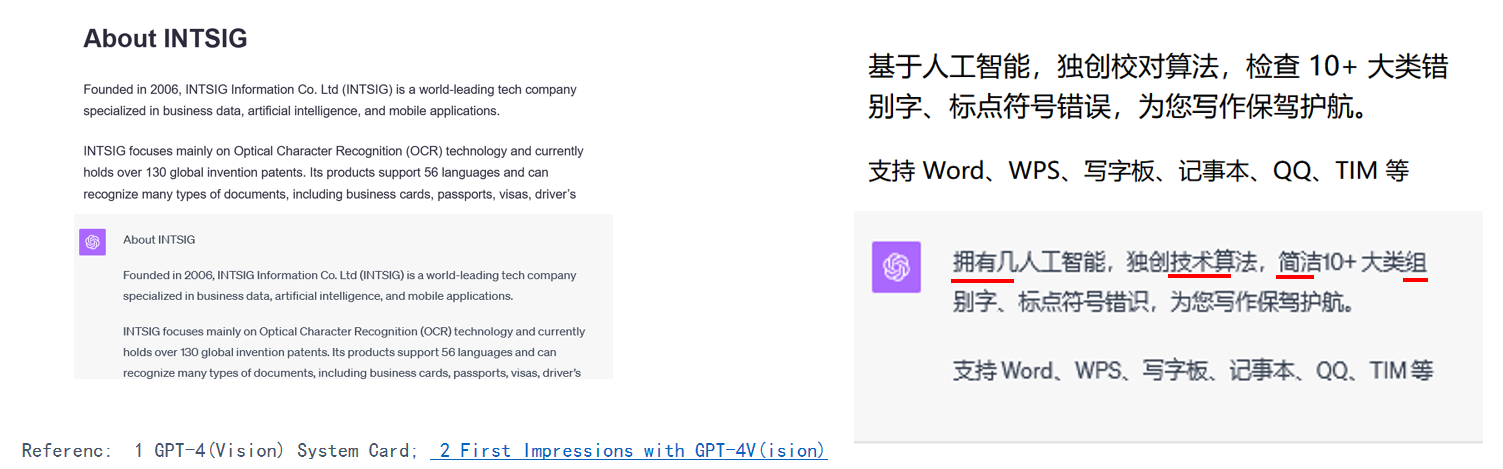
人工智能世界正在迅速发展,OpenAI 继续引领潮流。9月25日,该组织宣布对其 ChatGPT 系统进行了重大升级,引入了具有视觉功能的 GPT-4V 模型和多模态对话功能。
经过一系列测评下来,发现GPT-4V在识别英文时的效果还是很不错的,但在识别中文方面就有点差强人意,并且对一些数学符号的识别也会有问题。如下图是中英文识别的效果。
⭐️LLM时代文档图像处理技术
近年来,随着多模态模型的研究进展迅速。其中,一些基于深度学习的多模态模型已经在图像描述、视频理解、情感分析等任务中取得了很好的效果。
文档图像领域的专家一致认为LLM时代文档图像处理技术会有以下三个趋势。
- 输入:多模态
- 架构:Transformer Encoder / Decoder
- 数据:海量/高质量数据
虽然现在多模态大模型势头正盛,但OCR仍然是一个非常重要的技术。至少目前这个阶段,想要训练一个大模型必须要依赖于高质量的大数据,而OCR本身就是一个非常好的提供大数据的工具,它不仅可以高效录入,还能够处理不同格式以及困难的图像数据。
⭐️知名文档图像大模型OCR性能分析
下面列举了一些在文档图像处理领域比较有名的系统。
- BLIP2:Q-Former连接图像编码器(ViT)和LLM解码器; 仅需训练Q-Former部分
- Flamingo:在LLM中增加Gated Attention层引入视觉信息
- LLaVA:将CLIP ViT-L和LLaMA采用全连接层连接; 使用GPT-4和Self-Instruct生成高质量的158k instruction following数据
- MiniGPT:ViT+ Q-Former + Vicuna
- Nougat: Swin Transformer + Transformer Decoder 图像到序列范式; 820万页文档的数据集
- Kosmos: win Transformer + Transformer Decoder 范式; 3.2亿的数据和1.3B的模型达到远超Nougat等Sota指标
- Donut: 无需OCR, 用于文档理解的Transformer模型
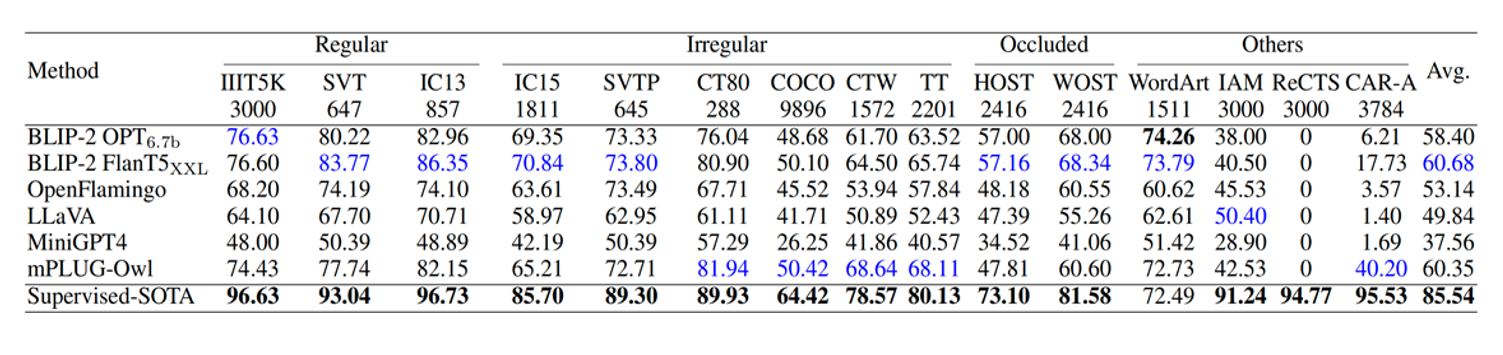
领域内不少专家将这些知名系统和OCR进行了一些比较,从性能上看识别率还是有所不如。分析下来的原因可能是视觉编码器的分辨率和训练数据限制。
⭐️图像安全
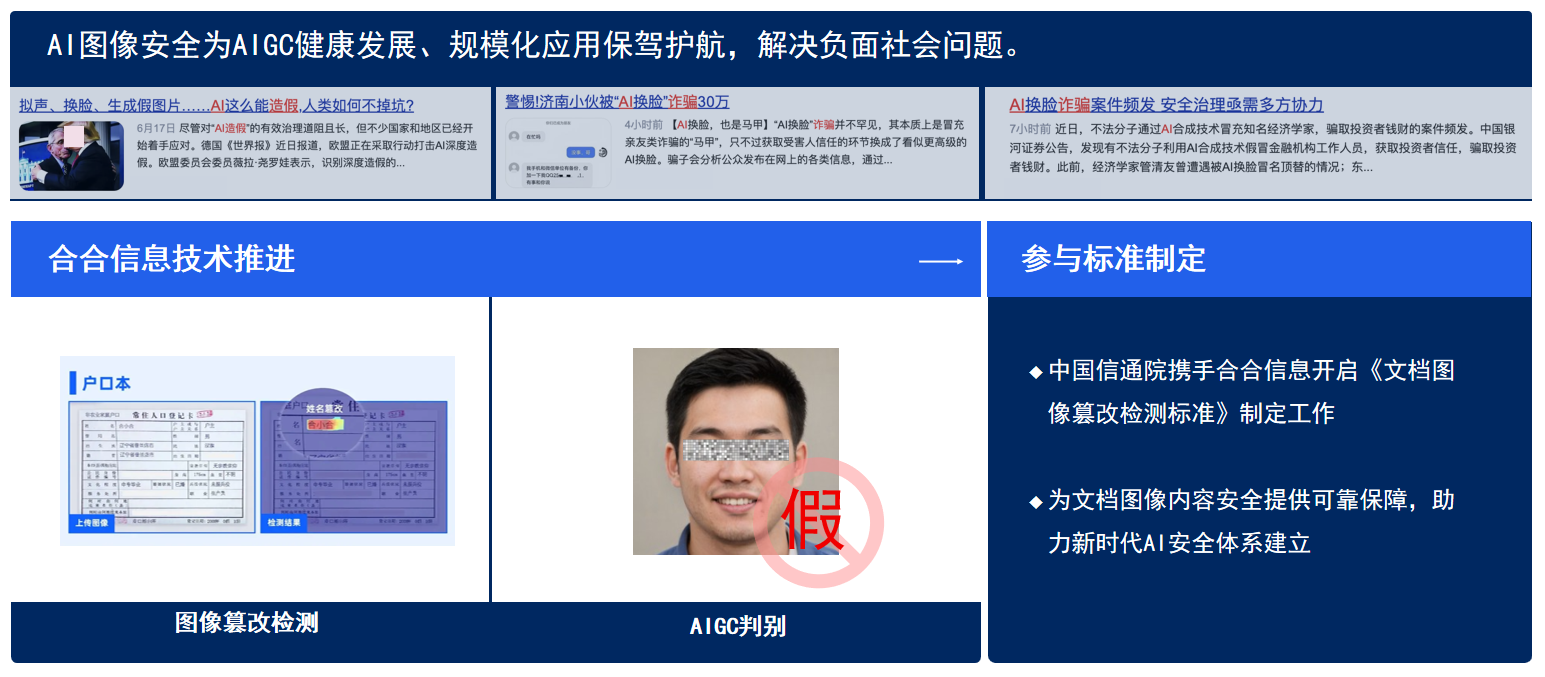
近年随着人工智能(AI)技术的迅速发展,AI 在图像领域的应用也日益广泛。但同时也出现了一些与图像安全相关的问题,例如图像篡改、虚假图像生成、图像隐写等,大量基于虚假图片产生的诈骗案件、网络暴力事件在全球范围内造成了恶劣的影响。
基于这个研发背景,合合信息提供两种图像安全技术解决方案包括图像篡改检测和AIGC判别,并且参与了图像篡改检测标准的制定。
⭐️图像篡改检测
合合信息使用监督学习的方法,将已知的图像篡改样本输入到模型中,让模型通过不断地调整权重和偏置,使得模型的输出结果与真实标签(篡改或未篡改)尽可能地接近。整体上图像篡改检测分为四个类型:
- 复制移动: 某一个图像中的某个区域复制到另外一个区域;
- 拼接: 两个毫不相干的图像拼接成一个新的图像;
- 擦除: 擦除图像中的一些关键信息;
- 重打印: 在擦除的基础上重新修改图像。

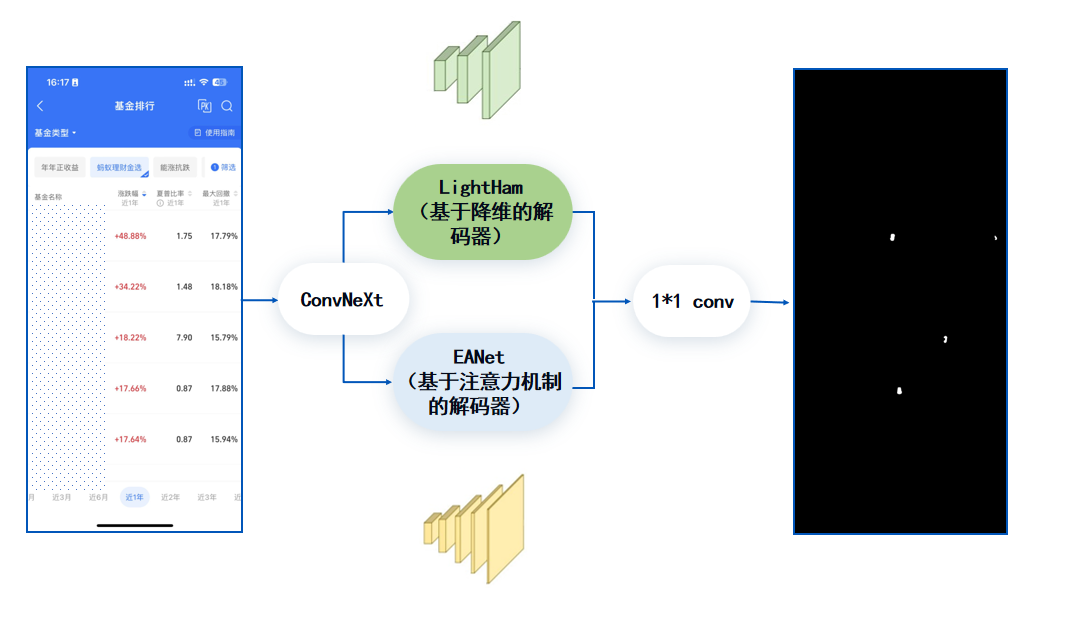
针对以上问题合合信息采用基于分割模型的系统架构。Backbone使用ConvNeXt作为编码器,使用LightHam和EANet两个网络并行作为解码器。通过两个解码器的融合可以得到一个较好的判断效果。这个判断不仅会给出是否篡改的结果,还会给出具体的篡改位置。
图像篡改检测在技术上任面临数据合成和训练策略两大挑战,数据合成方面通过对多种字体、多种场景、多种篡改形式和头像物体篡改等进行人工标注自动生成海量图像对,训练策略方面通过对网络架构、损失函数、数据增加、迭代训练和调整超参等进行大量实验得到最适合篡改检测任务的策略。
在今年文档分析与识别国际会议(ICDAR)挑战赛上,合合信息战胜了来自全球的上千支参赛团队,获得“文本篡改检测”赛道总冠军。

目前图像篡改检测系统在合合信息平台上已公开,并且已落地很多行业比如证券、保险、银行和零售等。
⭐️AIGC判别
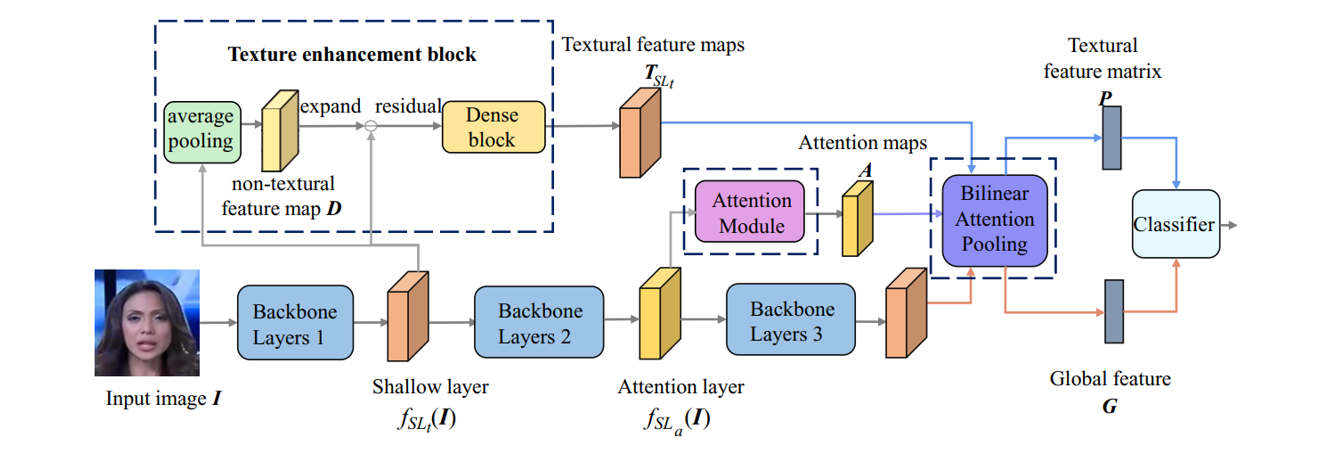
针对生成式AI造假,合合信息也研发了相关检测产品。以人脸场景为例,该产品可通过多个空间注意力头来关注空间特征,并使用纹理增强模块放大浅层特征中的细微伪影,增强模型对真实人脸和伪造人脸的感知与判断准确度。下面是一个比较接近的架构图。
⭐️标准制定
为贯彻落实《中华人民共和国网络安全法》《生成式人工智能服务管理》等文件中对于AI服务的规范性要求,系统性建立图像内容安全行业发展秩序,中国信息通信研究院(以下简称“中国信通院”)启动了《文档图像篡改检测标准》制定工作。该项标准由中国信通院牵头,上海合合信息科技股份有限公司、中国图象图形学学会、中国科学技术大学等科技创新企业及知名学术机构联合编制。

⭐️合合信息
合合信息主要致力于智能文字识别和商业大数据领域两个业务。底层技术包括模式识别、图像处理、神经网络、深度学习、STR和NLP等AI技术以及隐私计算、知识图谱等大数据技术。C端的明星产品主要有名片全能王、扫描全能王和启信宝等深受全球用户喜爱的效率工具,B端服务包括AI+大数据赋能数字化转型提供金融风险知识图谱解决方案、供应链大数据风控解决方案和政企大数据治理解决方案等。
目前,图像处理领域仍面临关于文档图像分析识别与理解的技术难题包括场景及版式多样、采集设备不确定性、用户需求多样性和文档图像质量退化严重等问题。

为了解决上述难题,合合信息在文档图像分析、版面分析和文档信息抽取等方面做了非常多的积累,也在不断地创新方法。同时合合信息也对外提供关于文档图像方面的文本识别、文本检测和版面元素标注等高质量的数据用于多模态大模型的训练。
⭐️总结
本次大会是一个非常重要的学术会议,旨在促进模式识别和计算机视觉领域的交流和合作。在本次会议上,来自国内外的专家学者就该领域的最新研究成果进行了分享和讨论,涉及到了图像处理、机器学习、深度学习等多个方面。
通过这次“文档图像前沿技术探索 —多模态及图像安全”专题报告的分享,展现出了合合信息在文档图像领域十余年的深耕底蕴。正是这种科技实力使得合合信息能够在这个不断变化的领域中保持竞争优势,并为社会提供更安全的图像解决方案。
总的来说,本次会议是一个非常成功的学术盛会,为该领域的发展做出了积极的贡献。
这篇关于关于“文档图像前沿技术探索 —多模态及图像安全”专题报告分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






