本文主要是介绍linux网络编程之posix 线程(二):线程的属性和 线程特定数据 Thread-specific Data,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、posix 线程属性
POSIX 线程库定义了线程属性对象 pthread_attr_t ,它封装了线程的创建者可以访问和修改的线程属性。主要包括如下属性:
1. 作用域(scope)
2. 栈尺寸(stack size)
3. 栈地址(stack address)
4. 优先级(priority)
5. 分离的状态(detached state)
6. 调度策略和参数(scheduling policy and parameters)
线程属性对象可以与一个线程或多个线程相关联。当使用线程属性对象时,它是对线程和线程组行为的配置。使用属性对象的所有线程都将具有由属性对象所定义的所有属 性。虽然它们共享属性对象,但它们维护各自独立的线程 ID 和寄存器。
线程可以在两种竞争域内竞争资源:
1. 进程域(process scope):与同一进程内的其他线程
2. 系统域(system scope):与系统中的所有线程
作用域属性描述特定线程将与哪些线程竞争资源。一个具有系统域的线程将与整个系 统中所有具有系统域的线程按照优先级竞争处理器资源,进行调度。
分离线程是指不需要和进程中其他线程同步的线程。也就是说,没有线程会等待分离 线程退出系统。因此,一旦该线程退出,它的资源(如线程 ID)可以立即被重用。
线程的布局嵌入在进程的布局中。进程有代码段、数据段和栈段,而线程与进程中的 其他线程共享代码段和数据段,每个线程都有自己的栈段,这个栈段在进程地址空间的栈 段中进行分配。线程栈的尺寸在线程创建时设置。如果在创建时没有设置,那么系统将会 指定一个默认值,缺省值的大小依赖于具体的系统。
POSIX 线程属性对象中可设置的线程属性及其含义参见下表:
| 函数 | 属性 | 含义 |
| int pthread_attr_setdetachstate (pthread_attr_t* attr ,int detachstate) | detachstate | detachstate 属性控制一个线程是否 是可分离的 |
| int pthread_attr_setguardsize (pthread_attr_t* attr ,size_t guardsize) | guardsize | guardsize 属性设置新创建线程栈的溢出 保护区大小 |
| int pthread_attr_setinheritsched (pthread_attr_t* attr, int inheritsched) | inheritsched | inheritsched 决定怎样设置新创建 线程的调度属性 |
| int pthread_attr_setschedparam (pthread_attr_t* attr , const struct sched_param* restrict param) | param |
param 用来设置新创建线程的优先级 |
| int pthread_attr_setschedpolicy (pthread_attr_t* attr, int policy) | policy | Policy 用来设置先创建线程的调度 策略 |
| int pthread_attr_setscope (pthread_attr_t* attr , int contentionscope) | contentionscope | contentionscope 用于设置新创建线 程的作用域 |
| int pthread_attr_setstack (pthread_attr_t* attr, void* stackader, size_t stacksize) | stackader stacksize | 两者共同决定了线程栈的基地址 以及堆栈的最小尺寸(以字节为 单位) |
| int pthread_attr_setstackaddr(pthread _attr_t* attr, void*stackader) | stackader | stackader 决定了新创建线程的栈的基地址 |
int pthread_attr_setstacksize(pthread_attr_t* attr, size_t stacksize) stacksize 决定了新创建线程的栈的最小尺寸
guardsize意思是如果我们使用线程栈超过了设定大小之后,系统还会使用部分扩展内存来防止栈溢出。而这部分扩展内存大小就是guardsize. 不过如果自己修改了栈分配位置的话,那么这个选项失效,效果相当于将guardsize设置为0.
每个线程都存在自己的堆栈,如果这些堆栈是相连的话,访问超过自己的堆栈的话那么可能会修改到其他线程的堆栈。 如果我们设置了guardsize的话,线程堆栈会多开辟guarszie大小的内存,当访问到这块内存时会触发SIGSEGV信号。
进程的调度策略和优先级属于主线程,换句话说就是设置进程的调度策略和优先级只 会影响主线程的调度策略和优先级,而不会改变对等线程的调度策略和优先级(注这句话不完全正确)。每个对等线程可以拥有它自己的独立于主线程的调度策略和优先级。
在 Linux 系统中,进程有三种调度策略:SCHED_FIFO、SCHED_RR 和 SCHED_OTHER,线程也不例外,也具有这三种策略。
在 pthread 库中,提供了一个函数,用来设置被创建的线程的调度属性:是从创建者线 程继承调度属性(调度策略和优先级),还是从属性对象设置调度属性。该函数就是:
int pthread_attr_setinheritsched (pthread_attr_t * attr, int inherit) 其中,inherit 的值为下列值中的其一:
enum
{
PTHREAD_INHERIT_SCHED, //线程调度属性从创建者线程继承
PTHREAD_EXPLICIT_SCHED //线程调度属性设置为 attr 设置的属性
};
如果在创建新的线程时,调用该函数将参数设置为 PTHREAD_INHERIT_SCHED 时,那么当修改进程的优先级时,该进程中继承这个优先级并且还没有改变其优先级的所 有线程也将会跟着改变优先级(也就是刚才那句话部分正确的原因)。
下面写个程序测试一下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | #include <unistd.h> #include <sys/types.h> #include <pthread.h> #include <stdlib.h> #include <stdio.h> #include <errno.h> #include <string.h> #define ERR_EXIT(m) \ do \ { \ perror(m); \ exit(EXIT_FAILURE); \ } while( 0) int main( void) { pthread_attr_t attr; pthread_attr_init(&attr); int state; pthread_attr_getdetachstate(&attr, &state); if (state == PTHREAD_CREATE_JOINABLE) printf( "detachstate:PTHREAD_CREATE_JOINABLE\n"); else if (state == PTHREAD_CREATE_DETACHED) printf( "detachstate:PTHREAD_CREATE_DETACHED"); size_t size; pthread_attr_getstacksize(&attr, &size); printf( "stacksize:%d\n", size); pthread_attr_getguardsize(&attr, &size); printf( "guardsize:%d\n", size); int scope; pthread_attr_getscope(&attr, &scope); if (scope == PTHREAD_SCOPE_PROCESS) printf( "scope:PTHREAD_SCOPE_PROCESS\n"); if (scope == PTHREAD_SCOPE_SYSTEM) printf( "scope:PTHREAD_SCOPE_SYSTEM\n"); int policy; pthread_attr_getschedpolicy(&attr, &policy); if (policy == SCHED_FIFO) printf( "policy:SCHED_FIFO\n"); else if (policy == SCHED_RR) printf( "policy:SCHED_RR\n"); else if (policy == SCHED_OTHER) printf( "policy:SCHED_OTHER\n"); int inheritsched; pthread_attr_getinheritsched(&attr, &inheritsched); if (inheritsched == PTHREAD_INHERIT_SCHED) printf( "inheritsched:PTHREAD_INHERIT_SCHED\n"); else if (inheritsched == PTHREAD_EXPLICIT_SCHED) printf( "inheritsched:PTHREAD_EXPLICIT_SCHED\n"); struct sched_param param; pthread_attr_getschedparam(&attr, ¶m); printf( "sched_priority:%d\n", param.sched_priority); pthread_attr_destroy(&attr); return 0; } |
在调用各个函数设置线程属性对象的属性时需要先调用 pthread_attr_init 初始化这个对象,最后调用pthread_attr_destroy 销毁这个对象。
simba@ubuntu:~/Documents/code/linux_programming/UNP/pthread$ ./pthread_attr
detachstate:PTHREAD_CREATE_JOINABLE
stacksize:8388608
guardsize:4096
scope:PTHREAD_SCOPE_SYSTEM
policy:SCHED_OTHER // 普通线程
inheritsched:PTHREAD_INHERIT_SCHED
sched_priority:0
二、线程特定数据 Thread-specific Data
在单线程程序中,我们经常要用到"全局变量"以实现多个函数间共享数据。
在多线程环境下,由于数据空间是共享的,因此全局变量也为所有线程所共有。
但有时应用程序设计中有必要提供线程私有的全局变量,仅在某个线程中有效,但却可以跨多个函数访问。
POSIX线程库通过维护一定的数据结构来解决这个问题,这个些数据称为(Thread-specific Data,或 TSD)。
相关函数如下:
int pthread_key_create(pthread_key_t *key, void (*destructor)(void*));
int pthread_key_delete(pthread_key_t key);
void *pthread_getspecific(pthread_key_t key);
int pthread_setspecific(pthread_key_t key, const void *value);
int pthread_once(pthread_once_t *once_control, void (*init_routine)(void));
pthread_once_t once_control = PTHREAD_ONCE_INIT;
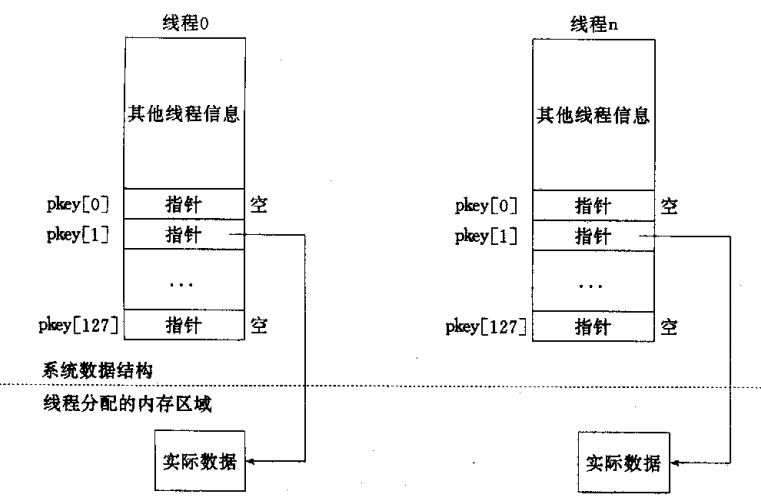
当调用pthread_key_create 后会产生一个所有线程都可见的线程特定数据(TSD)的pthread_key_t 值,调用pthread_setspecific 后会将每个线程的特定数据与pthread_key_t 绑定起来,虽然只有一个pthread_key_t,但每个线程的特定数据是独立的内存空间,当线程退出时会执行destructor 函数。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 | #include <unistd.h> #include <sys/types.h> #include <pthread.h> #include <stdlib.h> #include <stdio.h> #include <errno.h> #include <string.h> #define ERR_EXIT(m) \ do \ { \ perror(m); \ exit(EXIT_FAILURE); \ } while( 0) typedef struct tsd { pthread_t tid; char *str; } tsd_t; pthread_key_t key_tsd; pthread_once_t once_control = PTHREAD_ONCE_INIT; void destroy_routine( void *value) { printf( "destory ...\n"); free(value); } void once_routine( void) { pthread_key_create(&key_tsd, destroy_routine); printf( "key init ...\n"); } void *thread_routine( void *arg) { pthread_once(&once_control, once_routine); tsd_t *value = (tsd_t *)malloc( sizeof(tsd_t)); value->tid = pthread_self(); value->str = ( char *)arg; pthread_setspecific(key_tsd, value); printf( "%s setspecific ptr=%p\n", ( char *)arg, value); value = pthread_getspecific(key_tsd); printf( "tid=0x%x str=%s ptr=%p\n", ( int)value->tid, value->str, value); sleep( 2); value = pthread_getspecific(key_tsd); printf( "tid=0x%x str=%s ptr=%p\n", ( int)value->tid, value->str, value); return NULL; } int main( void) { //pthread_key_create(&key_tsd, destroy_routine); pthread_t tid1; pthread_t tid2; pthread_create(&tid1, NULL, thread_routine, "thread1"); pthread_create(&tid2, NULL, thread_routine, "thread2"); pthread_join(tid1, NULL); pthread_join(tid2, NULL); pthread_key_delete(key_tsd); return 0; } |
主线程创建了两个线程然后join 等待他们退出;给每个线程的执行函数都是thread_routine,thread_routine 中调用了pthread_once,此函数表示如果当第一个线程调用它时会执行once_routine,然后从once_routine返回即pthread_once 返回,而接下去的其他线程调用它时将不再执行once_routine,此举是为了只调用pthread_key_create 一次,即产生一个pthread_key_t 值。
在thread_routine 函数中自定义了线程特定数据的类型,对于不同的线程来说TSD的内容不同,假设线程1在第一次打印完进入睡眠的时候,线程2也开始执行并调用pthread_setspecific 绑定线程2的TSD 和key_t,此时线程1调用pthread_getspecific 返回key_t 绑定的TSD指针,仍然是线程1的TSD指针,即虽然key_t 只有一个,但每个线程都有自己的TSD。
simba@ubuntu:~/Documents/code/linux_programming/UNP/pthread$ ./pthread_tsd
key init ...
thread2 setspecific ptr=0xb6400468
tid=0xb6d90b40 str=thread2 ptr=0xb6400468
thread1 setspecific ptr=0xb6200468
tid=0xb7591b40 str=thread1 ptr=0xb6200468
tid=0xb7591b40 str=thread1 ptr=0xb6200468
destory ...
tid=0xb6d90b40 str=thread2 ptr=0xb6400468
destory ...
其中tid 是线程的id,str 是传递给thread_routine 的参数,可以看到有两个不同的ptr,且destroy 调用两次。
参考:
《UNP》
《炉边夜话--多核多线程杂谈》
这篇关于linux网络编程之posix 线程(二):线程的属性和 线程特定数据 Thread-specific Data的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






