本文主要是介绍表情分析计算机,利用深度学习和计算机视觉分析脸部表情,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原标题:利用深度学习和计算机视觉分析脸部表情

辨别脸部表情和情绪是人类社会互动早期阶段中一项基本且非常重要的技能。人类可以观察一个人的脸部,并且快速辨识常见的情绪:怒、喜、惊、厌、悲、恐。将这一技能传达给机器是一项复杂的任务。研究人员经过几十年的工程设计,试图编写出能够准确辨识一项特征的电脑程序,但仍必须不断地反覆尝试,才能辨识出仅有细微差别的特征。
那么,如果不对机器进行编程,而是直接教机器精确地辨识情绪,这样是否可行呢?
深度学习(deep learning)技术对于降低计算机视觉(computer vision)辨识和分类的错误率展现出巨大的优势。在嵌入式系统中实施深度神经网络(见图1)有助于机器透过视觉解读脸部表情,并达到类似人类的准确度。
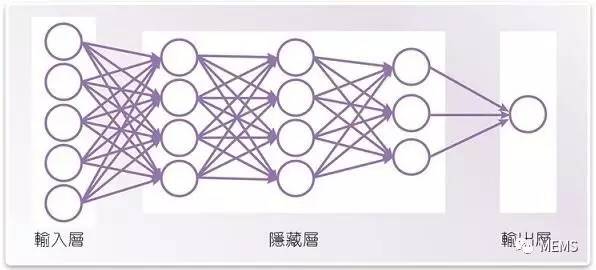
图1 深度神经网络的简单例子
神经网络可经由训练而辨识出模式,而且如果它拥有输入输出层以及至少一个隐藏的中间层,则被认为具有「深度」辨识能力。每个节点从上一层中多个节点的加权输入值而计算出来。这些加权值可经过调整而执行特别的图像辨识任务。这称为神经网络训练过程。
例如,为了训练深度神经网络辨识面带开心笑脸的照片,我们向其展示开心的图片作为输入层上的原始资料(图像画素)。由于知道结果是开心,网络就会辨识图片中的模式,并调整节点加权,尽可能地减少开心类别图片的错误。每个显示出开心表情并带有注解的新图片都有助于最佳化图片权重。借由充份的输入资讯与训练,网络可以摄入不带标记的图片,并且准确地分析和辨识与开心表情相对应的模式。
深度神经网络需要大量的运算能力,用于计算所有这些互连节点的加权值。此外,资料存储器和高效的资料移动也很重要。卷积神经网路(CNN)(见图2)是目前针对视觉实施深度神经网路中实现效率最高的先进技术。CNN之所以效率更高,原因是这些网络能够重复使用图片间的大量权重资料。它们利用资料的二维(2D)输入结构减少重复运算。
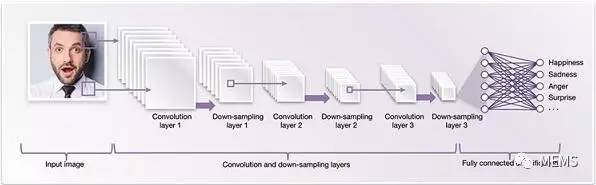
图2 用于脸部分析的卷积神经网路架构(示意图)
实施用于脸部分析的CNN需要两个独特且互相独立的阶段。第一个是训练阶段,第二个是部署阶段。
训练阶段(见图3)需要一种深度学习架构——例如,Caffe或TensorFlow——它采用中央处理器(CPU)和绘图处理器(GPU)进行训练计算,并提供架构使用知识。这些架构通常提供可用作起点的CNN图形范例。深度学习架构可对图形进行微调。为了实现尽可能最佳的精确度,可以增加、移除或修改分层。
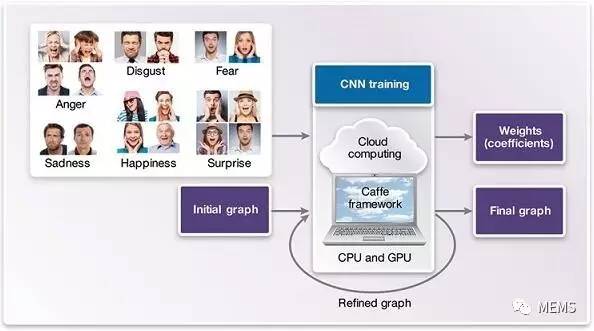
图3 CNN训练阶段
在训练阶段的一个最大挑战是寻找标记正确的资料集,以对网络进行训练。深度网络的精确度高度依赖于训练资料的分布和品质。脸部分析必须考虑的多个选项是来自「脸部表情识别挑战赛」(FREC)的情感标注资料集和来自VicarVision (VV)的多标注私有资料集。
针对即时嵌入式设计,部署阶段(见图4)可实施在嵌入式视觉处理器上,例如带有可编程CNN引擎的Synopsys DesignWare EV6x嵌入式视觉处理器。嵌入式视觉处理器是均衡性能和小面积以及更低功耗关系的最佳选择。
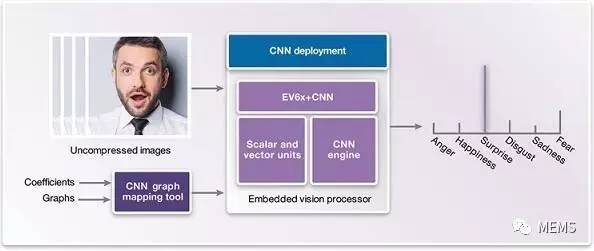
图4 CNN部署阶段
虽然标量单元和向量单元都采用C和OpenCL C(用于实现向量化)进行编程设计,但CNN引擎不必手动编程设计。来自训练阶段的最终图形和权重(系数)可以传送到CNN映射工具中,而嵌入式视觉处理器的CNN引擎则可经由配置而随时用于执行脸部分析。
从摄影机和图像传感器获取的图像或视频画面被馈送至嵌入式视觉处理器。在照明条件或者脸部姿态有显着变化的辨识场景中,CNN比较难以处理,因此,图像的预处理可以使脸部更加统一。先进的嵌入式视觉处理器的异质架构和CNN能让CNN引擎对图像进行分类,而向量单元则会对下一个图像进行预处理——光线校正、图像缩放、平面旋转等,而标量单元则处理决策(即如何处理CNN检测结果)。
图像解析度、画面更新率、图层数和预期的精确度都要考虑所需的平行乘积累加数量和性能要求。Synopsys带有CNN的EV6x嵌入式视觉处理器采用28nm工艺技术,以800MHz的速率执行,同时提供高达880MAC的性能。
一旦CNN经过配置和训练而具备检测情感的能力,它就可以更轻松地进行重新配置,进而处理脸部分析任务,例如确定年龄范围、辨识性别或种族,并且分辨发型或是否戴眼镜。
总结
可在嵌入式视觉处理器上执行的CNN开辟了视觉处理的新领域。很快地,我们周围将会充斥着能够解读情感的电子产品,例如检测开心情绪的玩具,以及能经由辨识脸部表情而确定学生理解情况的电子教师。深度学习、嵌入式视觉处理和高性能CNN的结合将很快地让这一愿景成为现实。
责任编辑:
这篇关于表情分析计算机,利用深度学习和计算机视觉分析脸部表情的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




