本文主要是介绍python+pytest接口自动化(16)-接口自动化项目中日志的使用 (使用loguru模块),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过上篇文章日志管理模块loguru简介,我们已经知道了loguru日志记录模块的简单使用。在自动化测试项目中,一般都需要通过记录日志的方式来确定项目运行的状态及结果,以方便定位问题。
这篇文章我们使用loguru模块来记录接口自动化测试中的日志。
一,封装日志记录器
实际项目中,我们不可能每个模块都去导入loguru模块,每个模块都单独去写一遍日志配置,这样麻烦又冗余。
最好的方式是针对项目单独封装、配置一个日志记录模块,作为公共的日志记录器,这既其他模块进行调用,也方便维护。
在loggerController.py中封装的日志记录器,代码及注释示例如下:
from loguru import logger
from datetime import datetimeclass ApiAutoLog():'''利用loguru封装接口自动化项目日志记录器'''def __new__(cls, *args, **kwargs):log_name = datetime.now().strftime("%Y-%m-%d") # 以时间命名日志文件,格式为"年-月-日"sink = "../log/{}.log".format(log_name) # 日志记录文件路径level = "DEBUG" # 记录的最低日志级别为DEBUGencoding = "utf-8" # 写入日志文件时编码格式为utf-8enqueue = True # 多线程多进程时保证线程安全rotation = "500MB" # 日志文件最大为500MB,超过则新建文件记录日志retention = "1 week" # 日志保留时长为一星期,超时则清除logger.add(sink=sink, level=level, encoding=encoding,enqueue=enqueue, rotation=rotation, retention=retention)return loggerlog = ApiAutoLog()if __name__ == '__main__':log.debug("这是一条debug日志信息")log.info("这是一条info日志信息")log.warning("这是一条warning日志信息")log.critical("这是一条critical日志信息")如果你想学习自动化测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的自动化测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)_哔哩哔哩_bilibili【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)共计200条视频,包括:1、接口自动化之为什么要做接口自动化、2、接口自动化之request全局观、3、接口自动化之接口实战等,UP主更多精彩视频,请关注UP账号。![]() https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click
这样,在别的地方需要记录日志时,只需导入该模块即可使用,且当天的日志会记录在以指定时间格式命名的.log文件里,如2022-04-05.log。
接下来我们通过调用该日志记录器来记录日志。
二,调用日志记录器记录日志
1. 明确接口自动化需要记录哪些日志
在做接口自动化时,我们首先需要确定测试用例需要记录哪些信息,换句话说,记录哪些日志才有意义?
-
为了清晰地定位执行了哪条用例,执行时测试用例名称需要记录在日志信息里。
-
接口的请求参数与返回参数必须记录在日志里,方便定位接口问题。
总之,博主认为,在接口自动化测试中,日志主要记录执行某条用例时对应的请求参数与返回参数即可,当然也可以更细化,这里不做过多说明。
2. 用例中记录日志示例
在明确了测试用例中需记录哪些日志信息后,我们用封装好的日志记录器去记录测试用例执行时的日志。
测试用例模块test_log.py中加入日志记录代码,示例如下:
import requests
import pytest
import json
# 导入封装好的日志记录器
from tools.loggerController import log# 测试类,仅为示例
class TestLogDemo:'''get请求'''def test_get_weather_normal(self):'''校验百度天气查询接口'''url = "https://weathernew.pae.baidu.com/weathernew/pc"params = {"query": "浙江杭州天气","srcid": 4982}log.info("请求参数为:{}, {}".format(url, params))res = requests.get(url=url, params=params)log.info("返回结果为:{}".format(res.text))assert res.status_code == 200assert "window.tplData" in res.text# 测试函数,post请求
def test_login_normal():'''正确用户名、正确密码登录'''url = "http://127.0.0.1:5000/login"headers = {"Content-Type": "application/json;charset=utf8"}data = {"username": "AndyLiu","password": "123456"}log.info("请求参数为:{}, {}, {}".format(url, headers, data))res = requests.post(url=url, json=data, headers=headers)log.info("返回结果为:{}".format(res.text))# 断言assert res.status_code == 200assert json.loads(res.text)["token"]if __name__ == '__main__':pytest.main()用例test_get_weather_normal即请求查询天气接口。用例test_login_normal查询的是自定义接口,该接口构造比较简单,学习过程中没有可用于请求调试的接口,则可以参考文章使用Flask开发简单接口自己开发简单接口。
接下来我们来运行该测试模块test_log.py,结果如下:
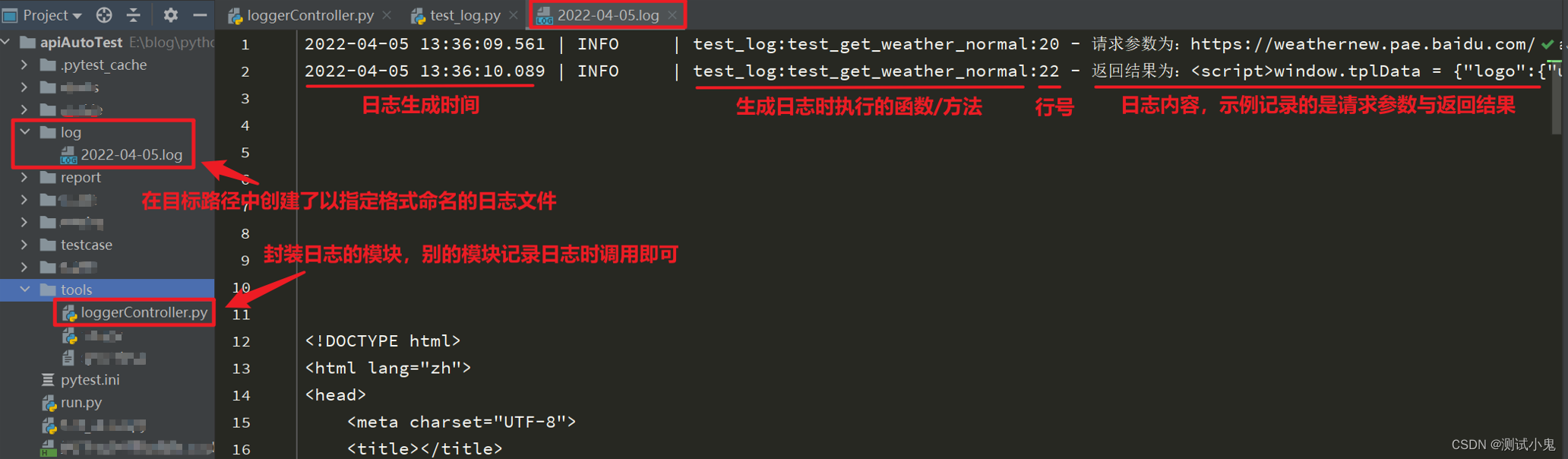
用例test_get_weather_normal返回的结果是一大串html文档内容。用例test_login_normal显示在日志文件的最后面,如下所示:
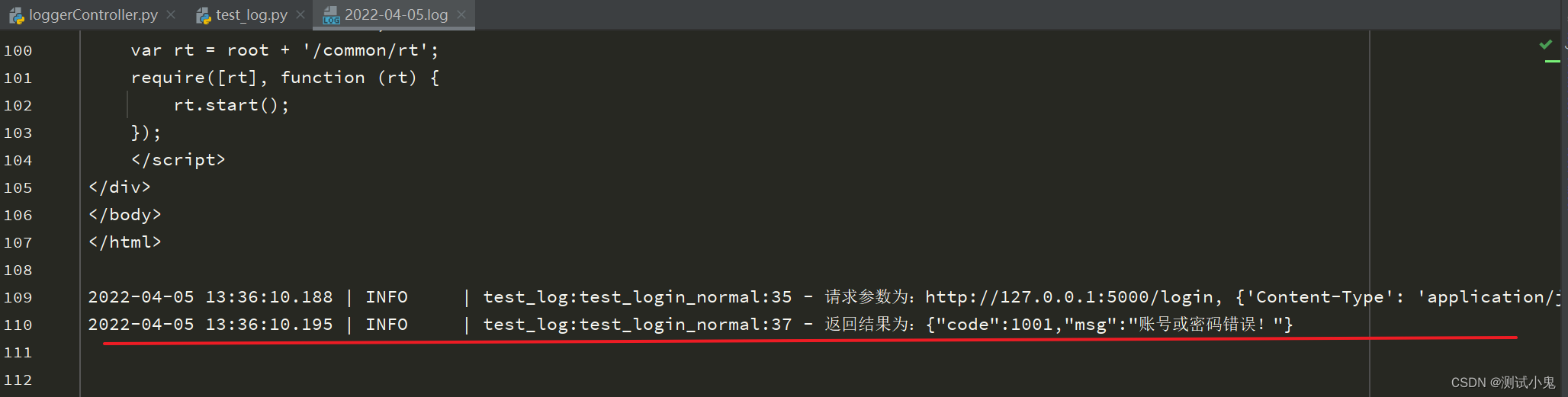
从结果可以看出来,日志文件中记录的日志非常清晰,且使用loguru默认的format格式时,会自动记录日志对应的函数名、方法名。
三,总结
最后我们一起来做个总结,如下:
-
在实际项目中需要自己封装相应配置的日志记录器用于公共调用,而不是每个模块单独配置使用
loguru或者logging。 -
我们要先明确自动化项目运行过程中需要哪些信息需要记录,然后再在代码中记录对应的内容。
-
相对于python自带的
logging模块,我们进一步看到了loguru模块简单得不可以思议。
这篇关于python+pytest接口自动化(16)-接口自动化项目中日志的使用 (使用loguru模块)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






