本文主要是介绍千万数据量秒级查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
**
详情见我的博客小生博客
**
双链表应用——千万数据量秒级查询

原理
利用双链表,
将数据全部读入内存,将读到的数据头插插入双链表,
因为链表头插效率高
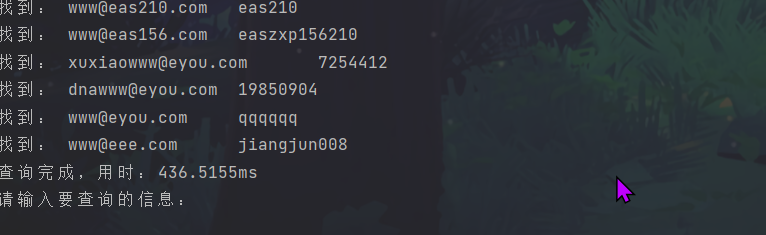
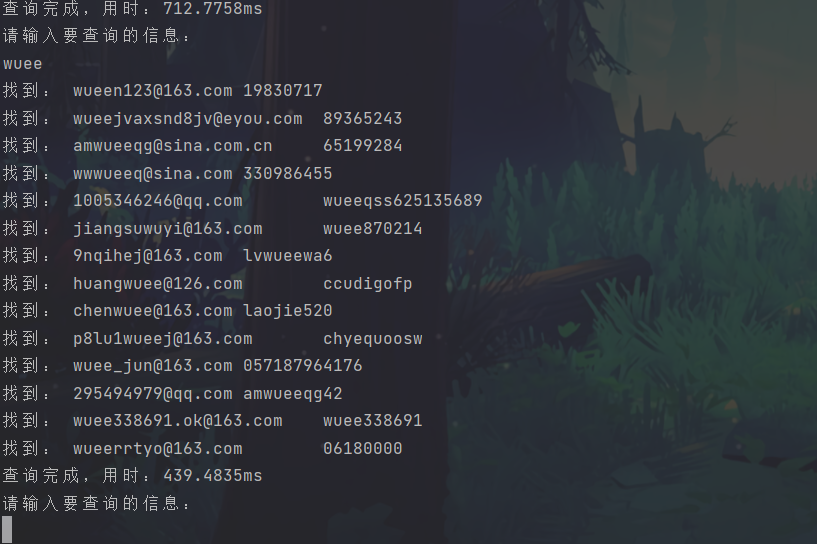
然后在内存中检索数据,检索到就输出
代码片段
// 读取文件
file,_ := os.Open(path) // 打开文件
br := bufio.NewReader(file) // 读出文件对象
for{line,_,end := br.ReadLine()if end == io.EOF{break //文件结束跳出循环}linestr := string(line)
}
代码
package mainimport ("bufio""fmt""io""os""strings""time"
)type DoubleLinkNode struct{Value interface{}Next *DoubleLinkNodePre *DoubleLinkNode
}type MyDoubleLinkList struct{Lens intHead *DoubleLinkNode
}func NewDoubleLinkNode(value interface{})*DoubleLinkNode{return &DoubleLinkNode{Value: value,Next: nil,Pre: nil,}
}//func (DoubleLinkNode)func Constructor()*MyDoubleLinkList{return &MyDoubleLinkList{Lens: 0,Head: nil,}
}// GetLength 获取长度
func (this *MyDoubleLinkList)GetLength()int{return this.Lens
}// InsertHead 头插
func (this *MyDoubleLinkList)InsertHead(node *DoubleLinkNode){bak := this.Headthis.Head = nodethis.Head.Pre = nilthis.Head.Next = bakif this.Head.Next!=nil{this.Head.Next.Pre = this.Head}this.Lens++
}func (this *MyDoubleLinkList)toString(){node := this.Headstr := ""fmt.Println("lens:", this.Lens)for node != nil{str += fmt.Sprintf("%v-->", node.Value)node = node.Next}str += fmt.Sprintf("nil")fmt.Println(str)
}func (this *MyDoubleLinkList)FindStr(value string)interface{}{node := this.Headfor node!= nil{if strings.Contains(node.Value.(string), value){fmt.Println("找到:", node.Value.(string))}node = node.Next}return false
}func main() {l := Constructor()startTime := time.Now()pathList := []string{"D:\\itcast\\社工\\压缩\\猴岛游戏社区\\houdao\\1_1.txt","D:\\itcast\\社工\\压缩\\猴岛游戏社区\\houdao\\1_2.txt","D:\\itcast\\社工\\压缩\\猴岛游戏社区\\houdao\\1_3.txt",}for i:=0; i<len(pathList);i++{path := pathList[i]file,_ := os.Open(path) // 打开文件br := bufio.NewReader(file) // 读出文件对象for{line,_,end := br.ReadLine()if end == io.EOF{break //文件结束跳出循环}linestr := string(line) //转化为字符串node := NewDoubleLinkNode(linestr) //新建节点l.InsertHead(node)}}fmt.Printf("内存载入完成, 数据量:%d, 用时:%v", l.GetLength(), time.Since(startTime))for;;{fmt.Println("\n请输入要查询的信息:")var str stringfmt.Scanln(&str)startTime2 := time.Now()l.FindStr(str)fmt.Printf("查询完成,用时:%v", time.Since(startTime2))}
}这篇关于千万数据量秒级查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






