本文主要是介绍脱离ZooKeeper依赖的Kafka Controller Quorum(KRaft)机制浅析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

前言
相信这几天大家正在被“Kafka要弃用ZooKeeper”的消息刷屏,并且无一例外地将其视为这个老当益壮的消息系统近年来最重大的变革。当然,由于ZooKeeper在Kafka中承担了Controller选举、Broker注册、TopicPartition注册与Leader选举、Consumer/Producer元数据管理和负载均衡等等很多任务,使Kafka完全摆脱ZooKeeper的依赖也不是一朝一夕就能完成的事情。
本文挑选一个较为基础而重要的方面做简单的说明,即基于Raft共识协议的Controller Quorum机制。看官若不了解Raft协议,请务必先阅读这篇文章获取前置知识。
从单点Controller到Controller Quorum
现阶段的Controller本质上就是Kafka集群中的一台Broker,通过ZK选举出来,负责根据ZK中的元数据维护所有Broker、Partition和Replica的状态。但是,一旦没有了ZK的辅助,Controller就要接手ZK的元数据存储,并且单点Controller失败会对集群造成破坏性的影响。因此,在将来的版本中,Controller会变为一个符合Quorum原则(过半原则)的Broker集合,如下图所示。
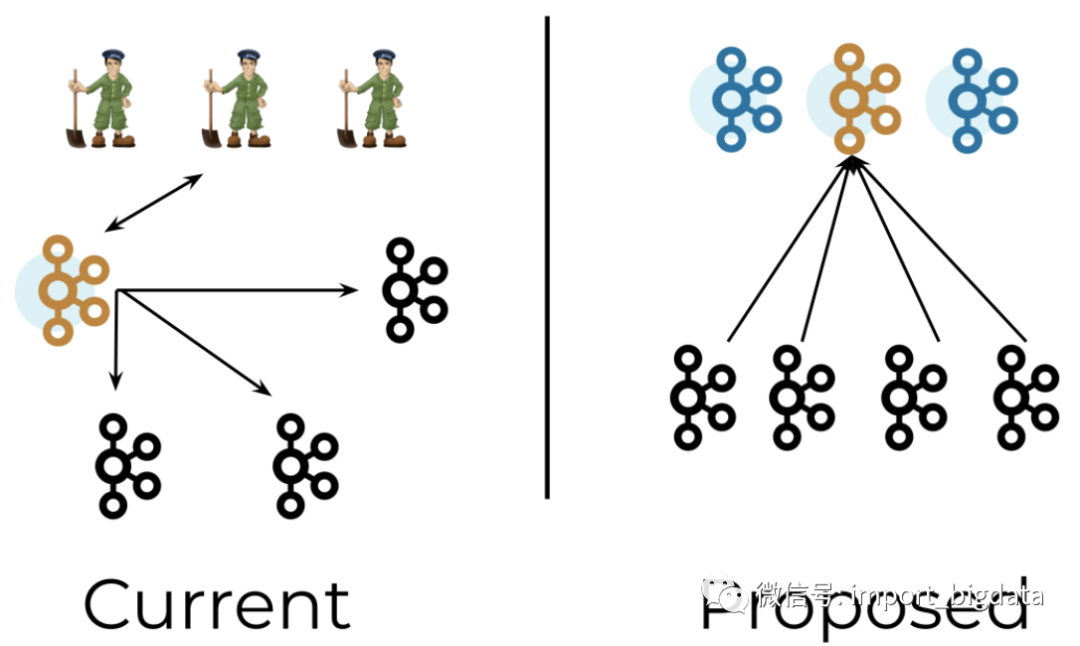
也就是说,在实际应用中要求Controller Quorum的节点数为奇数且大于等于3,最多可以容忍(n / 2 - 1)个节点失败。当然,只有一个节点能成为领导节点即Active Controller,领导选举就依赖于内置的Raft协议变种(又称为KRaft)实现。按照介绍Raft的思路,首先来看看Controller Quorum节点的状态与转移规则。复制状态机的理论请见参考文章。
Quorum节点状态机
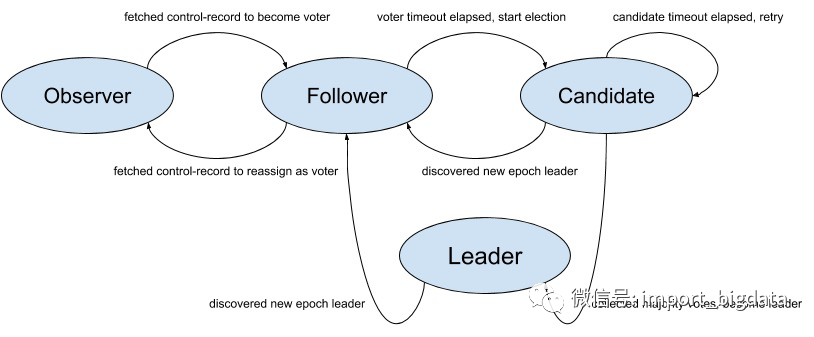
在KRaft协议下,Quorum中的一个节点可以处于以下4种状态之一。
Candidate(候选者)——主动发起选举;
Leader(领导者)——在选举过程中获得多数票;
Follower(跟随者)——已经投票给Candidate,或者正在从Leader复制日志;
Observer(观察者)——没有投票权的Follower,与ZK中的Observer含义相同,本文暂不考虑。
状态转换图如下所示。看官可以与经典Raft协议的状态转换图对比一下,基本是相似的。
消息定义
经典Raft协议只定义了两种RPC消息,即AppendEntries与RequestVote,并且是以推模式交互的。为了适应Kafka环境,KRaft协议以拉模式交互,定义的RPC消息有如下几种。
Vote:选举的选票信息,由Candidate发送;
BeginQuorumEpoch:新Leader当选时发送,告知其他节点当前的Leader信息;
EndQuorumEpoch:当前Leader退位时发送,触发重新选举,用于graceful shutdown;
Fetch:复制Leader日志,由Follower/Observer发送——可见,经典Raft协议中的AppendEntries消息是Leader将日志推给Follower,而KRaft协议中则是靠Fetch消息从Leader拉取日志。同时Fetch也可以作为Follower对Leader的活性探测。
根据KIP-595的说明,采用拉模式可以将一致性检查的工作放在Leader端,同时也可以更快速地bootstrap一个全新的Follower(直接从offset 0开始复制日志即可)以及淘汰过期的Follower。拉模式的缺点主要是处理僵尸Leader和Fetch的延迟可能较大。
领导选举
当满足以下三个条件之一时,Quorum中的某个节点就会触发选举:
向Leader发送Fetch请求后,在超时阈值quorum.fetch.timeout.ms之后仍然没有得到Fetch响应,表示Leader疑似失败;
从当前Leader收到了EndQuorumEpoch请求,表示Leader已退位;
Candidate状态下,在超时阈值quorum.election.timeout.ms之后仍然没有收到多数票,也没有Candidate赢得选举,表示此次选举作废,重新进行选举。
接下来的投票流程与经典Raft协议相同,不再赘述。当然,选举过程中仍然要对无效的选票进行处理,如集群ID或纪元值过期的选票。
元数据日志复制
与维护Consumer offset的方式类似,脱离ZK之后的Kafka集群将元数据视为日志,保存在一个内置的Topic中,且该Topic只有一个Partition。

元数据日志的消息格式与普通消息没有太大不同,但必须携带Leader的纪元值(即之前的Controller epoch):
Record => Offset LeaderEpoch ControlType Key Value Timestamp
这样,Follower以拉模式复制Leader日志,就相当于以Consumer角色消费元数据Topic,符合Kafka原生的语义。
那么在KRaft协议中,是如何维护哪些元数据日志已经提交——即已经成功复制到多数的Follower节点上的呢?Kafka仍然借用了原生副本机制中的概念——high watermark(HW,高水位线)保证日志不会丢失,HW的示意图如下。
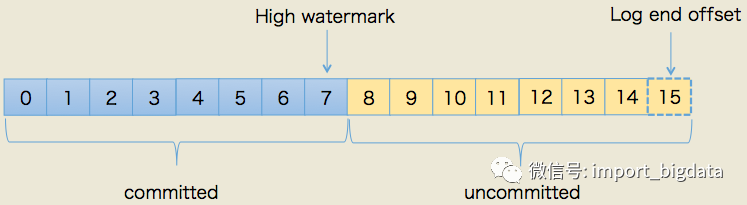
如果看官不了解HW,可以去搜索对应的资料,本文不废话了。
状态机安全性保证
在安全性方面,KRaft与传统Raft的选举安全性、领导者只追加、日志匹配和领导者完全性保证都是几乎相同的。下面只简单看看状态机安全性是如何保证的,仍然举论文中的极端栗子:
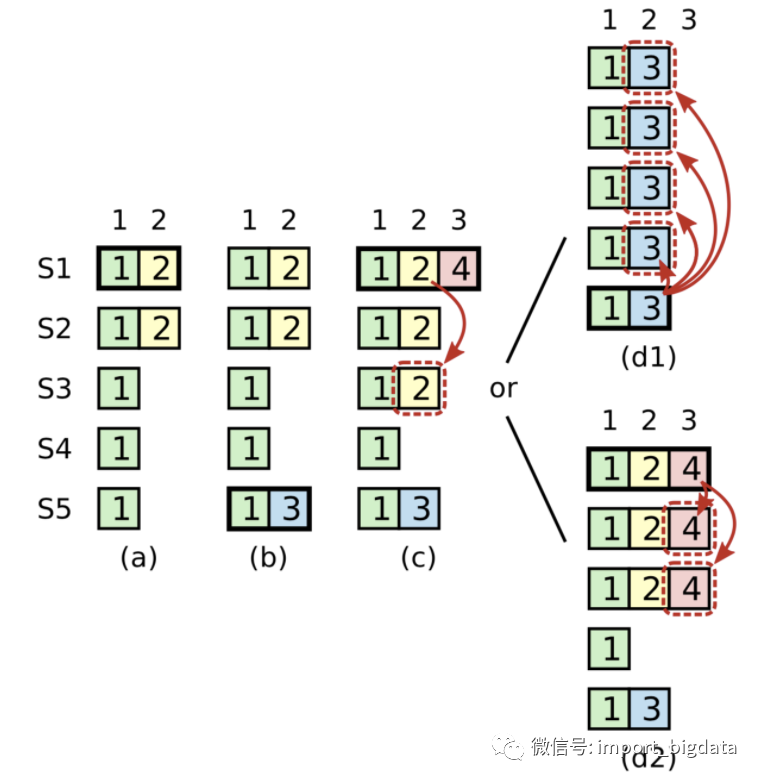
在时刻a,节点S1是Leader,epoch=2的日志只复制给了S2就崩溃了;
在时刻b,S5被选举为Leader,epoch=3的日志还没来得及复制,也崩溃了;
在时刻c,S1又被选举为Leader,继续复制日志,将epoch=2的日志给了S3。此时该日志复制给了多数节点,但还未提交;
在时刻d,S1又崩溃,并且S5重新被选举为领导者,将epoch=3的日志复制给S0~S4。
此时日志与新Leader S5的日志发生了冲突,如果按上图中d1的方式处理,消息2就会丢失。传统Raft协议的处理方式是:在Leader任期开始时,立刻提交一条空的日志,所以上图中时刻c的情况不会发生,而是如同d2一样先提交epoch=4的日志,连带提交epoch=2的日志。
与传统Raft不同,KRaft附加了一个较强的约束:当新的Leader被选举出来,但还没有成功提交属于它的epoch的日志时,不会向前推进HW。也就是说,即使上图中时刻c的情况发生了,消息2也被视为没有成功提交,所以按照d1方式处理是安全的。

背景调查时在调查些什么?
缓存之王 | Redis最佳实践&开发规范&FAQ
【大数据技术与架构】2021年大数据面试进阶系列系统总结
这篇关于脱离ZooKeeper依赖的Kafka Controller Quorum(KRaft)机制浅析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





