本文主要是介绍2023.12.14 hive sql的聚合增强函数 grouping set,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.建库建表
2.需求
3.使用union all来完成需求
4.聚合函数增强 grouping set
5.聚合增强函数cube ,rollup
6.rollup翻滚
7.聚合函数增强 -- grouping判断
1.建库建表
-- 建库
create database if not exists test;
use test;
-- 建表
create table test.t_cookie(month string, day string, cookieid string)
row format delimited fields terminated by ',';
-- 数据样例内容
insert into test.t_cookie values
('2015-03','2015-03-10','cookie1'),
('2015-03','2015-03-10','cookie5'),
('2015-03','2015-03-12','cookie7'),
('2015-04','2015-04-12','cookie3'),
('2015-04','2015-04-13','cookie2'),
('2015-04','2015-04-13','cookie4'),
('2015-04','2015-04-16','cookie4'),
('2015-03','2015-03-10','cookie2'),
('2015-03','2015-03-10','cookie3'),
('2015-04','2015-04-12','cookie5'),
('2015-04','2015-04-13','cookie6'),
('2015-04','2015-04-15','cookie3'),
('2015-04','2015-04-15','cookie2'),
('2015-04','2015-04-16','cookie1');建表完成后

2.需求
分别按照月,天,月和天统计来访用户cookieid个数,并获取三者的结果集,一起插到目标宽表中
3.使用union all来完成需求
select month,null as day, count(cookieid) cnt from test.t_cookie
group by monthunion allselect null as month, day, count(cookieid) cnt from test.t_cookiegroup by dayunion allselect month,day, count(cookieid) cnt from test.t_cookie
group by month,day;使用union all的表

--这些指标都是来源from来自了一个表,因为是3个查询后的结果集进行合并
--这样的好处是可以在一个表中直观的看到多个结果
-- union all也单独占用了资源,当维度与指标多的时候,效率会很低
--group month ,day属于一个维度,因为是一起的
4.聚合函数增强 grouping set
==grouping sets函数解释==:
就是通过指定的多个维度进行查询的. 即: 你写了哪些维度, 它就按照哪些维度进行聚合计算.
细节: 维度要用小括号括起来, 如果是1个维度, 小括号可以省略, 但是建议写上.
grouping sets函数在hive中 和 presto中的写法略有不同
如果是在hive中, group by后边必须要写分组字段, 将来我们可以根据这些 分组字段的不同组合, 形成不同的维度. 如果是在Presto中, group by后边什么都不写, 因为它(presto)会根据你写的 维度, 自动根据字段进行分组.
==grouping sets函数优点==:
使用grouping sets==只会对表进行一次扫描==。
使用grouping sets==查询速度吊打==多个分组查询结果union all。
使用grouping sets==执行结果==与多个分组查询结果union all的结果集==一样==;
--grouping sets聚合增强函数
--依然是查询每月,每天,和月和天来统计用户个数 ,使用hive
select month,day,count(cookieid) cntfrom hive_test.t_cookiegroup by month, daygrouping sets ((month,day),(month),(day));select month,day,count(cookieid) cntfrom hive_test.t_cookiegroup by month, daygrouping sets ((month,day),month,day); --括号可以省略-- 下面这个是Presto SQL语法支持
select month,day,count(cookieid) from test.t_cookie group bygrouping sets (month,day,(month,day));总结:
--group by后面需要加维度字段名字
--维度要用小括号括起来,如果grouping set后面不写维度,默认就是所有维度,题目中就会count全部数量,最后结果是14
--grouping set的速度快了5倍,(month),day,month,(),单个指标括号可以省略,
--union all需要从上到下一个一个运行,grouping set 则是并行
5.聚合增强函数cube ,rollup

以上的grouping set已经可以自定想要分组的维度了,但还是需要自己手动输入分组,那么cube可以只输入指定的原始维度字段,然后他就会考虑到所有维度的组合方式,自动生成所有排列组合情况,
例如: 你传入month, day, 就相当于写了 (), (month), (day), (month,day) 这四个维度
公式:假如说有==N个维度,那么所有维度的组合的个数:2^N==
-- 使用cube函数生成指定维度的所有组合
select month,day,count(cookieid)
from test.t_cookie
group by
cube (month, day);-- 上述sql等价于
select month,day,count(cookieid)
from test.t_cookie
group by
grouping sets ((month,day), month, day, ());总结:
cube可以自动生成所有排列组合
但是cube默认所有组合,无法自己决定想组合的部分
group by后面不用加上原始维度 ,只有hive中grouping set需要在group by后面加维度字段
6.rollup翻滚
-
rollup的功能:实现==从右到左多级递减==的统计,显示统计某一层次结构的聚合。
-
==rollup函数解释==:
按照你指定的字段, 进行维度组合查询, 它相当于是 cube的子集, cube是所有维度, rollup是部分维度. -- 例如: 你写的维度是a,b, 则组合后的维度有: (a,b), (a), ()
即: 从右往左多级递减(结论, 记忆)
写的维度假如是c,b,a 则组合后的维度有(c,b,a) , (c,b) , (c) , ()
-- rollup的功能:实现从右到左递减多级的统计
select month,day,count(cookieid)
from test.t_cookie
group by
rollup (month,day); -- (month,day),month,()-- 等价于
select month,day,count(cookieid)
from test.t_cookie
group by
grouping sets ((month,day), (month), ());7.聚合函数增强 -- grouping判断
grouping的功能,判断当前数据是按照哪个字段来进行分组的,
grouping(维度字段1,维度字段2)
如果分组中有相应字段,则将位设置为0,否则将其设置为1,总之就是有0没1
在语法上,grouping 要求group by后面不能有分组字段,grouping set在hive上运行的时候要求加分组字段,所以 要想grouping和grouping set配合使用,必须在presto上运行,hive不行.
-- 在Presto引擎中进行执行
select month,day,count(cookieid),grouping(month) as m,grouping(day) as d,grouping(month, day) as m_d
from test.t_cookie
group by grouping sets (month, day, (month, day));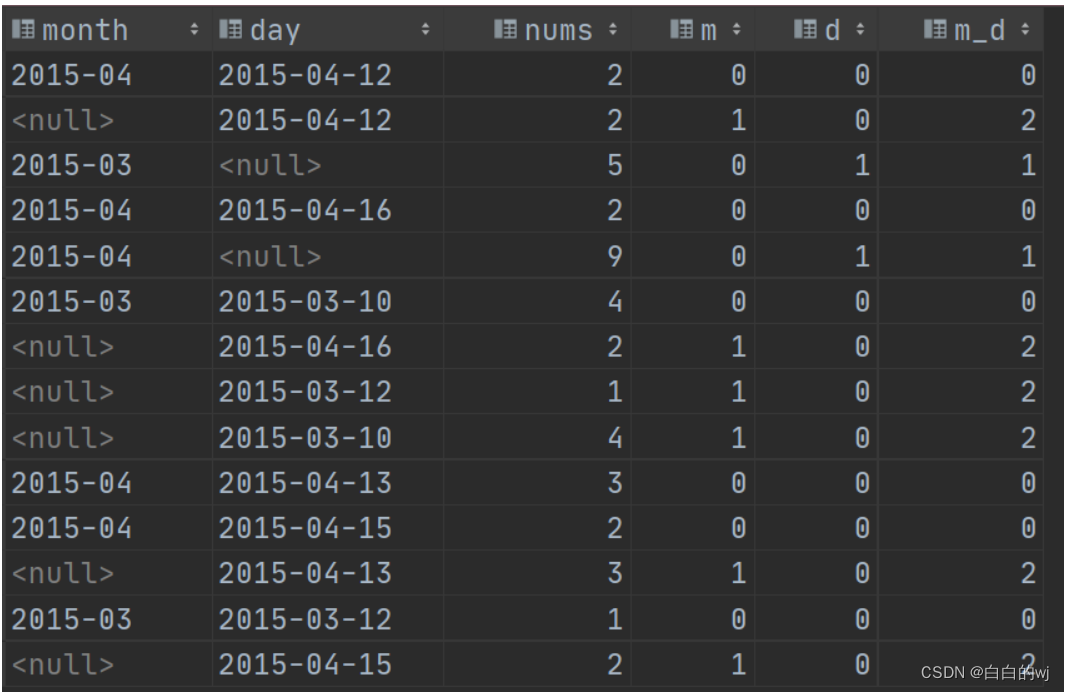
有是0,没有是1,group by
grouping sets (month, day, (month, day));
第一行中month 和 day都是0,代表这分组没有这两个字段
第二行中,month为1,day为0,说明月是没有的,天是有的, 10是二进制,转为十进制后得到数字2
第三行中,月0日1,说明月有,01是二进制,转为十进制后得到数字1
grouping(month)列为0时,可以看到month列都是有值的,为1时则相反,证明当前行是按照month来进行分组统计的
grouping(day)列为0时,也看到day列有值,为1时day则相反,证明当前行时按照day来进行分组统计的
grouping(month, day)是grouping(month)、grouping(day)二进制数值组合后转换得到的数字
a. 按照month分组,则month=0,day=1,组合后为01,二进制转换为十进制得到数字1;
b. 按照day分组,则month=1,day=0,组合后为10,二进制转换为十进制得到数字2;
c. 同时按照month和day分组,则month=0,day=0,组合后为00,二进制转换为十进制得到数字0。
因此可以使用grouping操作来判断当前数据是按照哪个字段来分组的。
grouping(日期、城市、商圈、店铺) = 1010(二进制) = 10(十进制) 证明有(城市, 店铺)维度
grouping(日期、城市、商圈、店铺) = 1001 = 9(十进制) 证明有( 城市, 商圈)维度 grouping(日期、城市、商圈、店铺) = 0100 = 4(十进制) 证明有(日期, 商圈, 店铺)维度
这篇关于2023.12.14 hive sql的聚合增强函数 grouping set的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



