本文主要是介绍Linux --绘制地图投影出现报错:无法成功下载地图背景数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linux --绘制地图投影出现报错:无法成功下载地图背景数据
- 主要原因是由于使用学院集群,该集群无法连接外网,在使用cartopy绘制地图投影时,导致无法成功加载地图背景数据
- 解决方法也很简单,自己手动下载所需要的地形数据然后放到cartopy存放地图数据的文件夹处即可
import cartopy
cartopy.config
找到地图存放路径:

进入到该路径下,cd ~/.local/share/cartopy/,你会发现会有一个名称为shapefiles的文件夹,进入该文件夹:
.local/share/cartopy/shapefiles
里面还有一个子文件夹:natural_earth,再次进入后,里面有个physical文件夹,在进入这个文件夹,这个.local/share/cartopy/shapefiles/natural_earth/physical
就是你要手动放置地图数据的地方,下载地图的网址如下:
https://www.naturalearthdata.com/downloads/
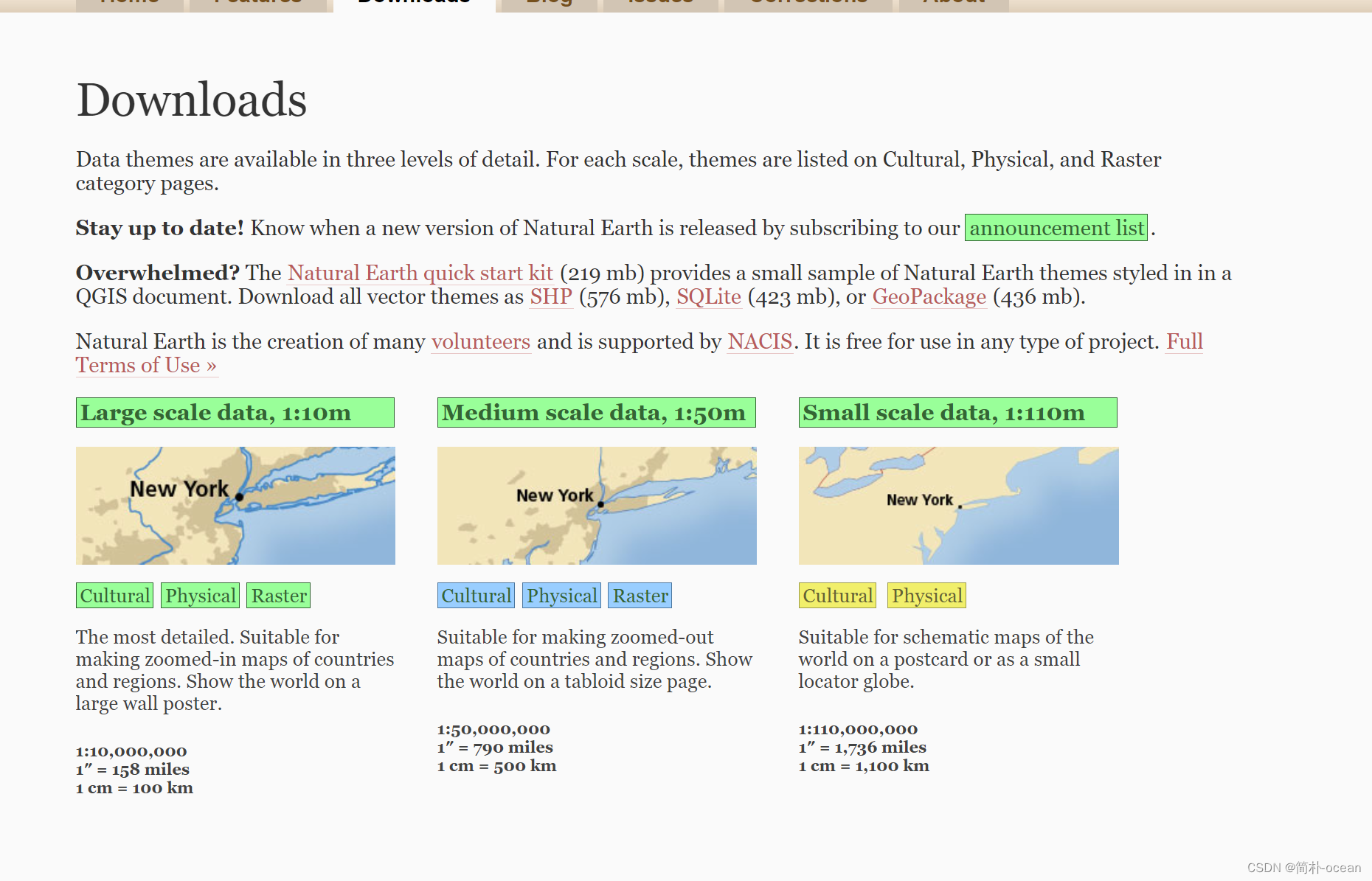
如上图所示,存在三个分辨率,110m、50m、10m,根据自己的需求进行下载,也可以三个都下载,点击Physical,跳转到下载页面: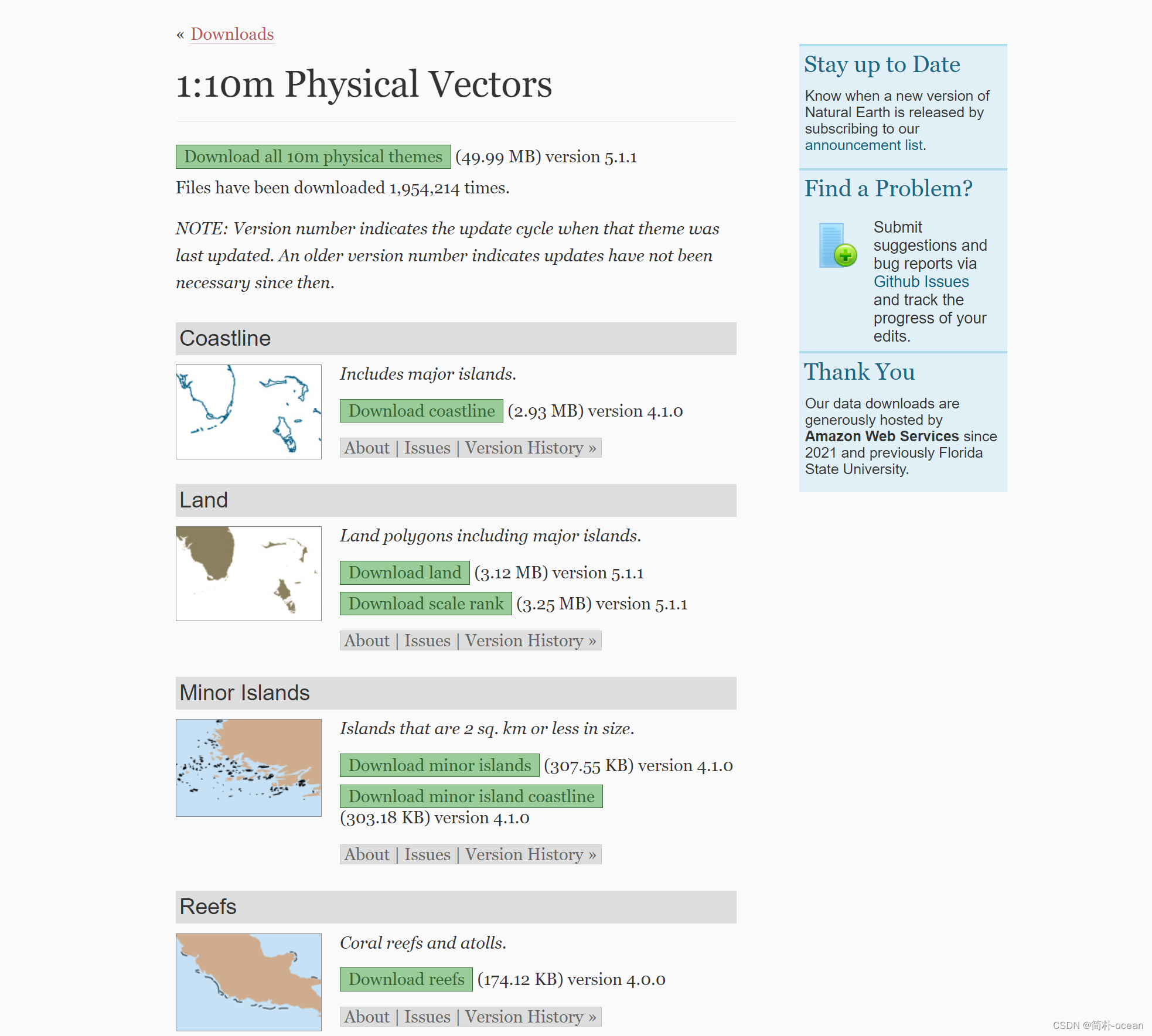
点击download all 10m physical themes,下载该分辨率下的地图数据,

下载后是一个压缩包的形式,
将这些压缩包通过scp命令传到你的服务器上,刚刚的找到的路径位置,然后解压缩即可。不会scp命令的话,这里推荐使用一个远程软件 MobaXterm ,使用ssh 远程连接服务器后,这个软件的左侧可以打开服务器上文件夹的目录,直接从本地将下载的压缩文件拖进去,就自动上传了
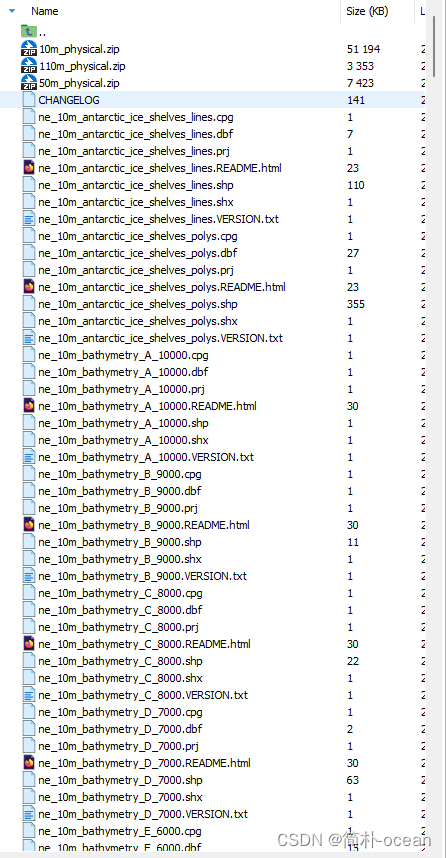
然后,解压缩地图数据:
unzip 10m_physical.zip
unzip 50m_physical.zip
unzip 110m_physical.zip
最后,运行测试代码,查看是否存在问题:
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
proj = ccrs.PlateCarree()
fig = plt.figure(figsize=(4, 4), dpi=200)
ax = plt.axes(projection=ccrs.PlateCarree())
ax.coastlines()
plt.show()
plt.savefig("cartopy_plot_test.png")
复制上述代码,在linux页面使用vi 新建一个python脚本:
vi plot_test.py
然后将代码粘贴进去,保存后运行改脚本,
python plot_test.py
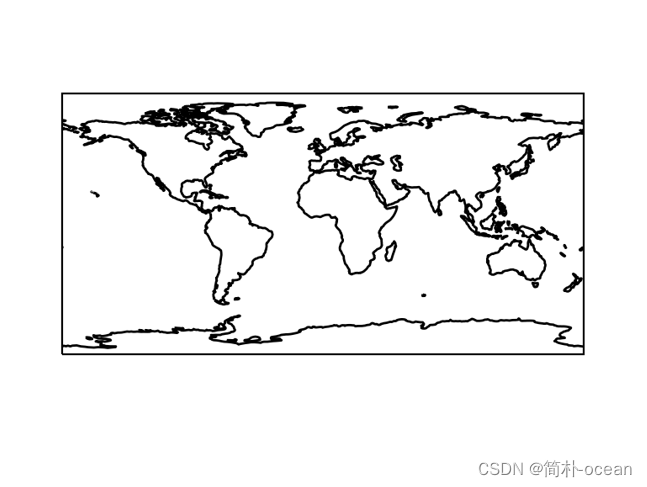
如果顺利保存图片,则运行成功,可以继续画图了
这篇关于Linux --绘制地图投影出现报错:无法成功下载地图背景数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









