本文主要是介绍5+铁死亡+分型+多组机器学习,铁死亡到现在还是大热,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给同学们分享一篇生信文章“Identification of ferroptosis-related molecular clusters and genes for diabetic osteoporosis based on the machine learning”,这篇文章发表在Front Endocrinol (Lausanne)期刊上,影响因子为5.2。

结果解读:
鉴定在糖尿病性骨质疏松症中特异表达的FRGs
在GSE35958中,使用“limma”软件包对4个对照样本和5个骨质疏松样本的表达谱数据进行了归一化处理(图2A、B)。根据adj. P-Value < 0.05和|log2fold change (FC)| ≥ 1的标准,通过差异分析鉴定出了1102个差异表达基因(DEGs),其中包括677个上调基因和425个下调基因(图2C)。作者从CTD数据库和GeneCards数据库分别获取了38253个和14818个与糖尿病相关的基因。从FerrDb数据库获取了259个与铁死亡相关的基因(FRGs)。作者将DEGs、与糖尿病相关的基因和与铁死亡相关的基因进行了交集分析,得到了15个交集基因,即与糖尿病性骨质疏松相关的FRGs,如Venn图所示(图2D)。通过绘制热图(图2E),作者可以观察到这15个与糖尿病性骨质疏松相关的FRGs在骨质疏松样本和对照样本之间的显著差异表达。为了阐明这15个FRGs之间的关系,作者采用了Spearman相关分析(图2F)。此外,染色体上15个FRG的定位显示在环状图中(图2G)。

鉴定骨质疏松症中的铁死亡亚群
作者使用无监督聚类分析探索了骨质疏松症中的铁死亡亚群,分析了与糖尿病性骨质疏松症相关的15个FRG的表达情况,共有42个骨质疏松样本。当k = 2时,共识矩阵的亚型数量最稳定,代表了两个明确定义的聚类(图3A)。如图3B所示,k = 2的CDF曲线在一致性指数范围0-1.0内波动最小。CDF图显示了k的变量值的相对面积变化(图3C)。主成分分析(PCA)进一步支持了两个聚类之间的显著差异(图3D)。

铁死亡亚群之间的差异
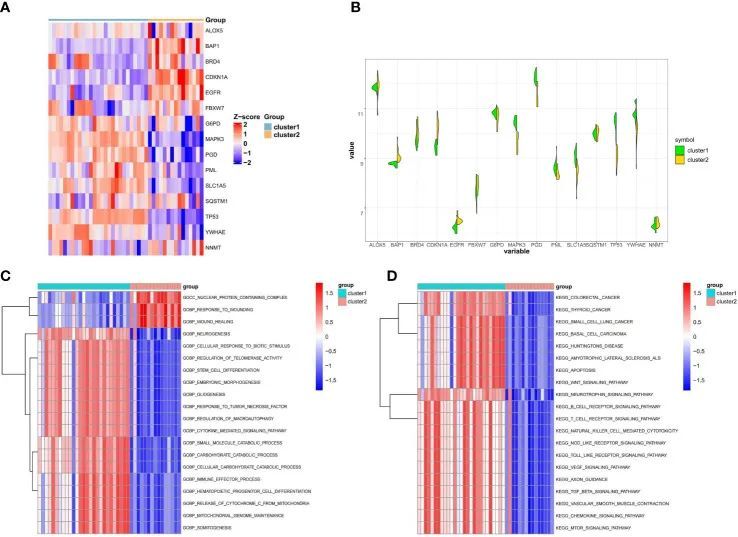
为了更好地理解两个铁死亡亚群之间的区别,作者分析了这两个亚群中15个FRG的表达差异和通路及生物活性的变化。两个亚群中的15个FRG的表达明显不同于对照组和骨质疏松样本(图4A)。亚群1表现出更高的FBXW7、G6PD、MAPK3、PML PGD、SLC1A5、SQSTM1、TP53和YWHAE的表达水平,而亚群2表现出更高的ALOX5、BAP1、BRD4、CDKN1A、EGFR和NNMT的表达水平(图4B)。GSVA分析的生物功能结果显示,亚群1中的核蛋白复合物、应对创伤和伤口愈合等功能受到下调,而亚群2中的神经发生、细胞对生物刺激的反应和调节端粒酶活性等功能受到上调(图4C)。此外,亚群1的富集通路主要上调,如结直肠癌、甲状腺癌和小细胞肺癌,而亚群2主要与下调通路相关,如基底细胞癌、亨廷顿病和肌萎缩性侧索硬化症(图4D)。 这些发现表明,在15个FRG的表达、富集通路和生物学角色方面,骨质疏松症患者的铁死亡亚群之间存在显著差异。针对不同的铁死亡亚群,需要采用特定的治疗方法。
WGCNA分析
基于基因表达谱,利用WGCNA算法构建了与铁死亡亚群最强连接的可能模块。如图5A所示,样本编号为GSM1369716的样本被排除为异常值。确定了保持无标度拓扑网络的理想软阈值为6(R2 = 0.85)(图5B)。根据相关聚类,将15个特征模块进行分类,并赋予不同的颜色标签(图5C)。蓝色模块(4,591个基因)与Cluster1(R = -0.89)和Cluster2(R = -0.89)之间的连接最强(图5D)。作者观察到蓝色模块与模块相关基因之间存在显著的相关性(cor = 0.91)(图5E)。随后,作者使用adj. P-Value < 0.05和|log2fold change (FC)| ≥ 1作为截断值,确定了铁死亡亚群的差异表达基因(DEGs)。总共发现了1,376个DEGs,其中265个上调,1,111个下调(图5F-H)。

与糖尿病骨质疏松症相关的铁死亡亚群的FRG的综合分析
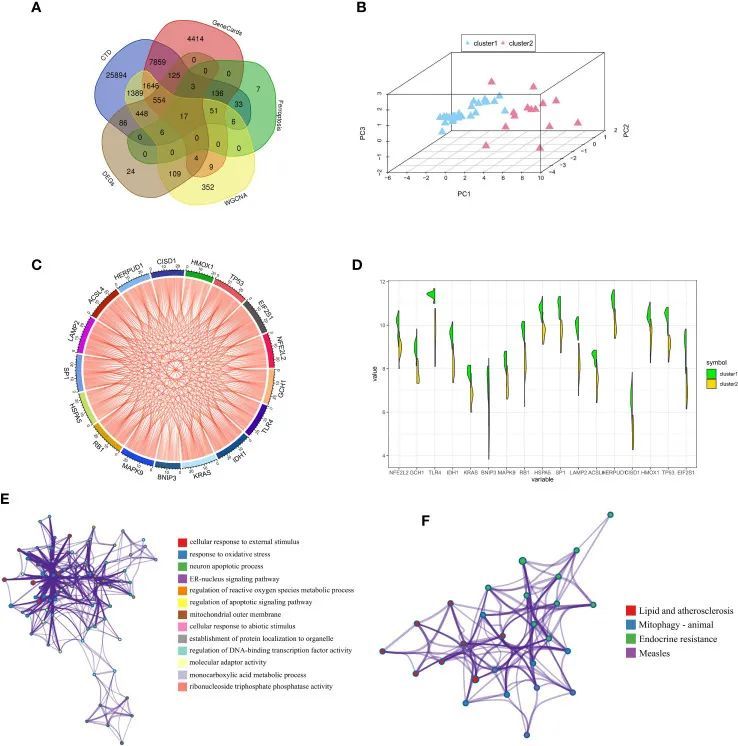
作者通过将数据库和数据集中的基因相结合,获得了与糖尿病骨质疏松相关的17个铁死亡亚群的FRGs(图6A)。PCA结果显示,与糖尿病骨质疏松相关的17个FRGs能够有效区分两个铁死亡亚群(图6B)。此外,与糖尿病骨质疏松相关的17个FRGs之间的关系网络图显示它们之间存在显著的正相关,有助于对基因之间相互关系的综合分析(图6C)。同时,除了BNIP3之外,所有基因在cluster1中高表达,如图6D所示。进行GO和KEGG富集分析,进一步研究与糖尿病骨质疏松相关的17个FRGs的可能生物功能和通路活性。GO富集分析的显著结果显示,17个FRGs主要与细胞对外部刺激的反应、对氧化应激的反应和神经元凋亡过程相关(图6E)。此外,根据KEGG富集分析,还有17个FRG主要参与了各种经典信号通路,包括脂质和动脉粥样硬化、线粒体自噬-动物以及内分泌耐药性(图6F)。
构建预测模型和关键基因的鉴定
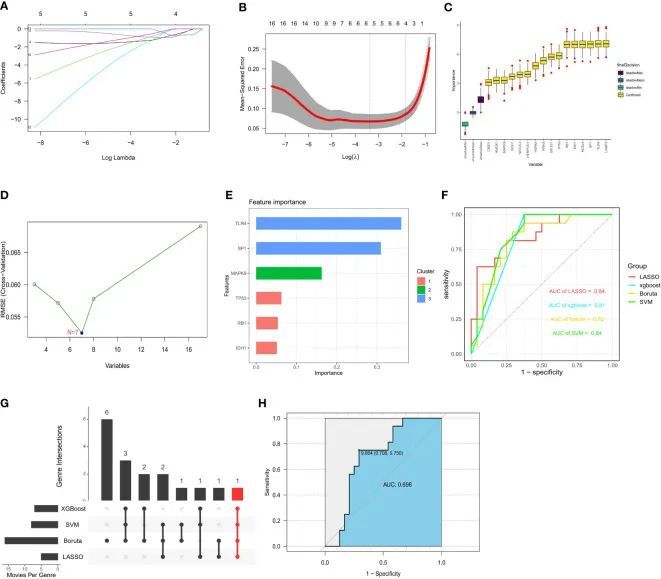
基于整个数据集,作者使用四种已建立的机器学习方法(LASSO、SVM RFE、Boruta和XGBoost)从17个与糖尿病骨质疏松症相关的FRG中寻找重要基因。这些算法分别产生了4个、7个、16个和6个基因(图 7A–E)。然后,作者利用GSE56815作为外部数据集,通过ROC曲线验证了四种机器学习算法的效率。所有四种算法都具有超过0.8的高曲线下面积(AUC)值,作者认为预测模型的结果是可靠的(图 7F)。IDH1是属于所有四种算法的常见基因(图 7G)。考虑到已鉴定基因的准确性,作者用外部数据集GSE56815绘制了ROC曲线,显示出较高的预测效率(图 7H)。最终,作者通过四个高效的预测模型,将17个FRG中的IDH1确定为糖尿病骨质疏松亚型的前瞻性指标。
总结
总之,作者在糖尿病性骨质疏松症中发现了两组脱铁性贫血,并证实了每一组的独特特征。基于17个脱铁蛋白基因的四个不同的机器学习预测模型(LASSO、XGBoost、Boruta和SVM)发现了能够区分糖尿病骨质疏松亚型的脱铁蛋白调节因子。最终,作为一种经外部数据集验证的脱铁调节因子,IDH1有能力精确区分糖尿病骨质疏松症的分子亚型,这可能为糖尿病骨质疏松的临床症状的病理生理学和预后异质性提供新的见解。
这篇关于5+铁死亡+分型+多组机器学习,铁死亡到现在还是大热的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









