本文主要是介绍每秒最高1w+使用量,「AI绘画」成抖音年度爆款,背后技术秘籍现已公开,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
允中 发自 凹非寺
量子位 | 公众号 QbitAI
「AI绘画」是2022年抖音上最火的一款特效玩法,用户只要输入一张图片,AI就会根据图片生成一张动漫风格的图片。
由于生成的图片效果带有一定的“盲盒”属性 ,画风精致唯美中又带着些许的蠢萌和无厘头,一经上线就激发了广大用户的参与热情,抖音单日投稿量最高达724w,还衍生了“如何驯服AI”、“谁来为我发声”等讨论分享。

据抖音「AI绘画」特效主页显示,已经有2758.3万用户使用过这款特效。
作为抖音SSS级的大爆款特效,「AI绘画」的峰值QPS(每秒请求量)也高达1.4w的惊人水平,如何保证用户的实时体验,对技术链路提出了极高的挑战,抖音又是怎样做到的呢?
带着这样的疑问,我们和「AI绘画」背后的项目团队——抖音特效、字节跳动智能创作团队聊了聊。
经过特别训练的动漫风模型
抖音特效对AI技术有过很多应用实践,2021年的「漫画脸」特效也是一款上线3天千万投稿的爆款,使用的是GAN技术。
这一次,抖音的「AI绘画」使用了时下最火的多模态生成技术。
这是由文本生成图片/视频/3D等跨模态的生成技术,具体地说,是通过大规模数据的训练,仅通过文字或少量其他低成本的信息引导,可控地生成任意场景的图片/视频/3D等内容,在AIGC等方向有极大的潜在应用价值。
据了解,随着DALL·E的问世,2021年初字节跳动智能创作团队就开始了相关技术的跟进和规划,今年8月底Stable Diffusion发布后,抖音特效团队很快启动了「AI绘画」这个项目。
Stable Diffusion是一个文本生成图像的多模态生成模型,相比于GAN,Stable Diffusion的多样性和风格化会更强,变化的形式也更丰富,同一个模型可以做很多不同的风格。同时,后者对性能和计算资源要求大幅下降,其自身开源的属性,还可以进行各种fine tune,调用和修改。
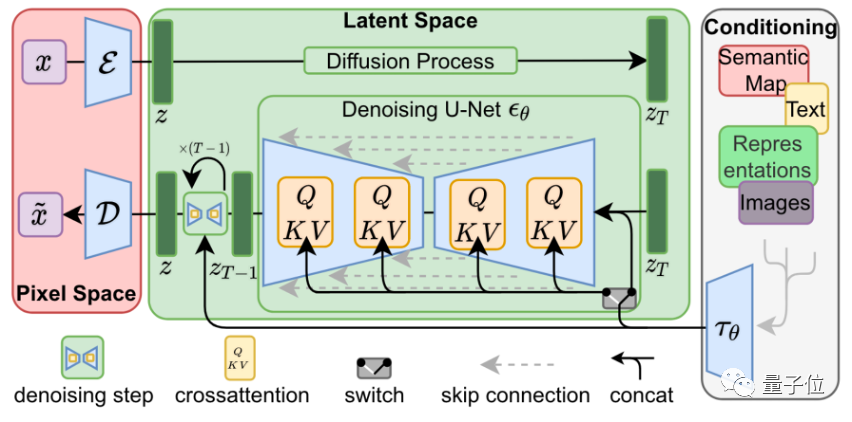
△基础模型架构
Stable Diffusion的逻辑是,用一个图像对应一个文本标注的形式去训练模型,一个“文本+图像”组成一个数据对,先对其中的图像通过高斯分布进行加噪,加完噪声之后,再训练一个网络去对它进行去噪,让模型可以根据噪声再还原出一个新的图像。
为了能够使用文字控制模型生成的内容,Stable Diffusion使用了预训练的CLIP模型来引导生成结果。
CLIP模型使用了大量的文字和图片对训练,能够衡量任意图片和文本之间的相关性。在前向生成图片的过程中,模型除了要去噪以外,还需要让图片在CLIP的文本特征引导下去生成。这样在不断生成过程中,输出结果就会越来越接近给定的文字描述。
抖音「AI绘画」是采用图片生成图片的策略,首先对图片进行加噪,然后再用训练好的文生图模型在文本的引导下去噪。
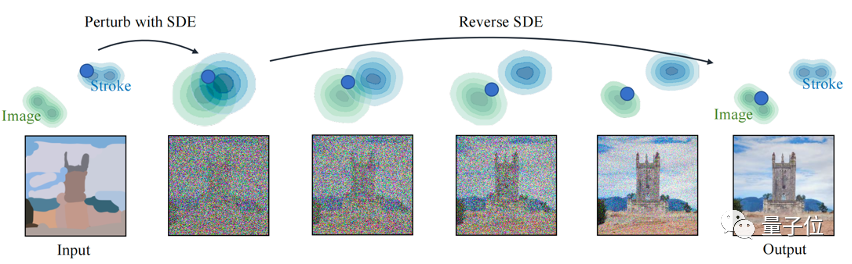
△图片生成图片的逻辑过程
作为技术支持方,字节跳动智能创作团队在Stable Diffusion开源模型的基础上,构建了数据量达十亿规模的数据集,训练出两个模型,一个是通用型的模型Diffusion Model,可以生成如油画、水墨画风格的图片;另外一个是动漫风格的Diffusion Model模型。

△通用模型Diffusion Model生成的图像风格

△动漫风格的Diffusion Model模型生成的图像风格
漫画风格模型是采用“漫画图像+文本”的数据对进行训练。为了让动漫风格模型生成的效果更好更丰富,字节跳动智能创作团队在动漫风格模型优化训练的数据集里特别加入了赛博朋克和像素风等不同风格的数据。
抖音特效在动漫风格上有过比较丰富的探索,观测了此前用户对不同风格的反馈,抖音「AI绘画」此次选用的就是精致漫画风的动漫风格。
在算法侧调优的同时,字节跳动智能创作团队为抖音特效产品侧提供了文本的接口prompt,方便产品侧对效果进行进一步的微调,通过输入文字,让生成的图片效果更加贴近于期望中的样子——风格化程度“不会特别萌、跟原图有一定相似度,但又不会特别写实”。
此外,模型还同时采用正向、负向文本引导生成的策略。除了描述生成图像内容、风格的正向条件外,还通过负向引导词(negative prompt)优化模型生成结果。通过在生成效果、生成内容等方面进行约束,可有效提升模型在图像细节上的生成质量, 并大大降低生成图像涵盖暴力、色情等敏感内容的风险。
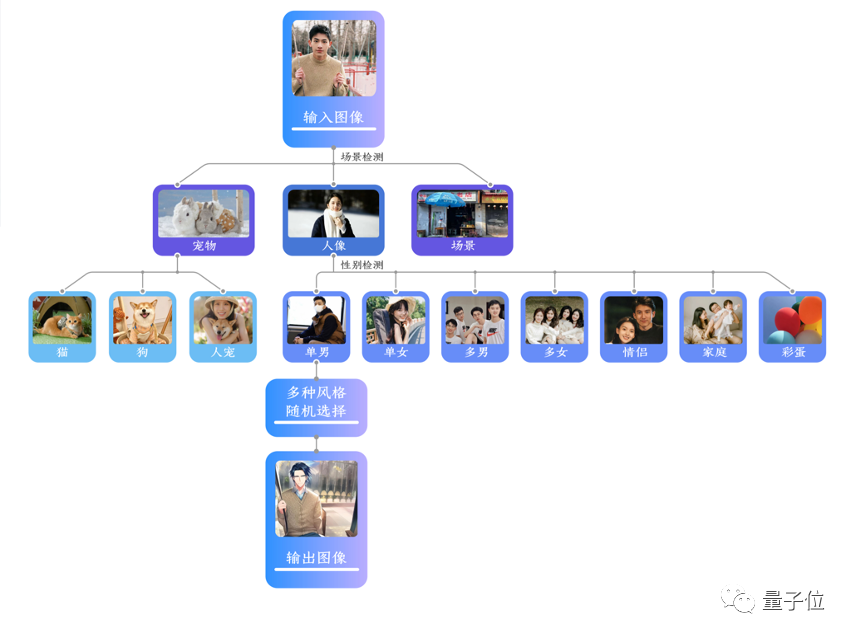
抖音「AI绘画」还针对不同场景对风格效果进行了优化。
首先,基于图像理解基础能力,对用户图像进行场景分类,如人像、宠物、后置场景等,对包含人像的场景,进一步对性别、人数、年龄等属性进行检测。对于不同的细分场景,均有多组优化的风格效果作为候选。在模型选择上,90%的人像及50%的后置场景使用漫画模型,其他则使用包含艺术风格的通常模型。此外,部分场景还以一定概率出现彩蛋效果,如人像性别反转等效果。
研发Diffusion Model加速算法,节约上万块推理GPU消耗
相比于传统的生成模型(GAN),扩散模型(Stable Diffusion)的模型体积和计算量更为庞大,AI绘画需要一个耗时繁重的推理过程。
上线到抖音这样一个亿级DAU的平台,对技术服务侧而言,无论是显存的占用,还是从GPU的推理耗时都较高,且面临峰值过万的 QPS 。
如何支持巨大的调用量和复杂的推理,是很大的挑战。
为缓解线上GPU资源消耗,字节跳动智能创作团队研发了Diffusion Model加速算法、采样步数减少算法、高效模型图融合技术、服务端推理部署框架等,并与NVIDIA技术团队协同合作,优化高性能神经网络推理库,对AI绘画模型进行了多个维度上的推理优化。
上述一系列优化方案显著降低推理耗时、显存占用以及加大服务端部署框架的数据吞吐,相对于基准模型QPS提升4倍以上,节约数万块推理GPU消耗,保障道具在抖音平台高峰期的高效稳定运转。
无分类器引导扩散模型最近已被证明在高分辨率图像生成方面非常有效,然而这种模型存在一个缺陷是它们在进行单步图像生成时需要进行两次模型推理,使得图像生成的成本非常昂贵。
为了解决这个问题,字节跳动智能创作团队提出了一种针对无分类器引导扩散模型的蒸馏算法AutoML-GFD(AutoML Guidance-Fusion Distillation),通过知识蒸馏的方式将条件引导信息和无条件信息进行知识融合,减少了模型在进行单步图像生成时的推理次数和资源需求。
同时,在蒸馏过程中把negative prompt, scale guidance信息蒸馏到模型中,在不改变模型推理输入的情况下达到更佳的效果;在Diffusion Model的训练和采样过程中,利用time-aware采样针对性地优化了重要时间步的效果,相对于基准模型可以进一步降低推理步数;蒸馏算法整体压测提升200%。
在服务端侧,通过模型图融合、 高效CUDA算子、OFFload PreCompute、前后处理算子融合、多线程并发等手段,协同字节跳动自研Lighten推理引擎和Ivory视觉服务框架,解决了多段模型Convert Failed和显存溢出等问题,提升模型推理效率。

△经过算法加速后生成的风格化图片效果
火山引擎机器学习平台将推理速度提升3.47倍,抖音同款智能绘图产品已toB
当前,伴随AIGC的应用日益多元和广泛,用户的痛点也随之浮上水面。
以Stable Diffusion为例,一次完整的预训练大约需要在 128 张 A100 计算卡上运行 25 天,用户付费上百万,高额的研发费用是用户最大的痛点之一。
同时,AIGC 产品演进快速,对性能和资源提出更高要求。
字节跳动旗下的云服务平台火山引擎为此类问题提供了解决方案,推动 AIGC 产业的发展。
火山引擎机器学习平台打造同时支持训练加速与推理加速的自主研发高性能算子库,在全面提升 AI 计算性能的基础上,不断追求节省显存、简单适配,同时支持多款 GPU 卡,为客户带来更多低成本、便捷的部署方案。
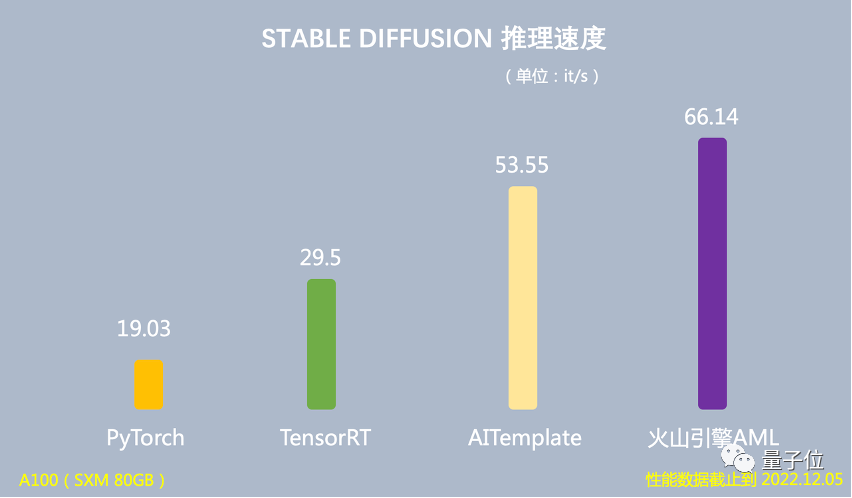
在推理场景下,基于 Stable Diffusion 模型的端到端推理速度达到 66.14 it/s,是 PyTorch 推理速度的 3.47 倍,运行时 GPU 显存占用量降低 60%。
在客户 AI 视频创作的 AIGC 推理业务实践中,火山引擎高性能算子库搭载客户的推理模型帮助其推理性能提升一倍,GPU 资源使用量减少一半,可为客户节省 50% 成本。
在训练场景下,使用该高性能算子库可将上文 Stable Diffusion 模型在 128 张 A100 的训练时间从 25 天减少到 15 天,训练性能提升 40%。
同时,由于 AIGC 模型在训练时占用 GPU 显存容量非常大,未经优化时的模型只能运行在最高端的 A100 80GB GPU 卡上。火山引擎高性能算子库通过大量消减中间操作,将运行时 GPU 显存占用量降低 50%,使得大多数模型可从 A100 迁移到成本更低的 V100 或 A30 等 GPU 卡上运行,摆脱特定计算卡的限制,而且不需要做额外的模型转换工作。
以此,以 AIGC 场景为代表,无论是迭代速度,还是单次的训练成本,都有了显著的性能提升和成本节省。
另外,火山引擎还面向企业客户推出了智能绘图产品,省去企业采集数据、训练模型和优化性能的时间和成本,可以快速接入业务,让企业拥有开箱即用、抖音同款的AI绘画能力。
这篇关于每秒最高1w+使用量,「AI绘画」成抖音年度爆款,背后技术秘籍现已公开的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







