本文主要是介绍【阅读笔记】《Learning to Segment Object Candidates》(DeepMask),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文记录了博主阅读论文《Learning to Segment Object Candidates》的笔记,代码,更新于2019.05.31。
文章目录
- Abstract
- Introduction
- Related Work
- DeepMask Proposals
- Network Architecture
- Joint Learning
- Full Scene Inference
- Implementation Details
- Experimental Results
- Conclusion
Abstract
目前的目标检测系统主要包括两步:(1)尽量高效地提出一组可能目标的候选;(2)将这些候选送入一个分类器。本文中提出了一种生成目标候选的新方法,包括基于判别卷积网络(discriminative convolutional network)的一个方法。网络的训练同时在两个共同的目的下进行:给定图块,系统的第一部分输出一个不区分类别的分割mask,第二部分则输出这个图块处于一个完整目标中间的概率。在测试过程中,模型可以高效地应用在整个测试图上,并且生成一系列分割mask,每个都分配了对应的目标可能性score。模型也可以范化到未见过的类别。与之前的生成目标mask的方法不同,本文的方法不需要依赖于边界、超像素或其他底层分割(low-level segmentation)。
Introduction
Related Work
DeepMask Proposals
给定一个输入图块,本文所提网络能够估计一个分割mask,并给每个图块分配一个其包含目标的可能性。
mask和score估计是同时用一个卷积网络实现的,只有网络的最后几层有不同。具体如下图所示:

在训练过程中,两个任务同时训练。相比较用两个模型完成两个任务的网络,这个结构能够减小网络规模并提升测试时的速度。
每个样本训练集中的 k k k都需要包含三样东西:(1)RGB图块 x k x_k xk;(2)对应输入图块的二进制mask m k m_k mk(其中 m k i j ∈ { ± 1 } m_k^{ij}\in\{\pm1\} mkij∈{±1}, ( i , j ) (i,j) (i,j)对应于每个像素在输入图块中的位置);(3)标注 y ∈ { ± 1 } y\in\{\pm1\} y∈{±1},声明图块中是否包含目标。具体而言,一个图块 x k x_k xk在给定了标签 y k = 1 y_k=1 yk=1时,需要满足下面的限制:
- 图块包含一个目标且目标在图块中心附近;
- 目标在指定尺度范围内完全存在于图块中。
否则, y k = − 1 y_k=-1 yk=−1,即使目标部分出现。实验中用的位置和尺度的容忍度稍后给出。假设 y k = 1 y_k=1 yk=1,真值mask m k m_k mk只有对存在于图块中间的单个物体给正值。如果该mask没有被使用,则 y k = − 1 y_k=-1 yk=−1。Figure1的最下面给出了训练triplets的示例。
Figure1的上面显示了模型的概况,这里成为DeepMask。上面的分支对应于实现高精度的目标分割mask估计,下面的分支给出目标存在并满足上述两个约束的概率。接下来会介绍网络结构各部分的细节、训练过程和快速推理过程。
Network Architecture
网络初始化参数来源于在ImageNet数据集下预训练的分类网络。这个模型随后fine-tuned用于生成目标候选。选择了VGG-A结构,其中包括八个3x3的卷积层(带ReLU)和五个2x2的最大池化层,表现很好。
由于关注分割mask,因此卷积特征图中的空间信息就很重要。因此溢出了最后的全连接层,并且抛弃了最后的最大池化层。共享网络层的输出用采样率16进行下采样(由于剩下的4个2x2的最大池化层);给定一个输入图像尺寸为 3 × h × w 3\times h\times w 3×h×w,输出特征图的尺寸为 512 × h 16 × w 16 512\times\frac{h}{16}\times\frac{w}{16} 512×16h×16w。
分割: 网络用一个1x1的卷积层结合ReLU,后面加一个分类层,实现分割。分类层包括 h × w h\times w h×w像素的分类器,每个都代表这个像素是否属于图块中心的目标。主义输出平面中的每个像素分类器都必须能够利用到整个特征图中的信息,因此对目标有一个完整的理解。这点很重要,因为与语义分割不同,这个网络必须能够输出一个对单个目标的mask,即使有多个目标都存在。(比如Fig1中的大象)
对于分类层,既可以用全局的也可以用全连接像素分类器。这两种方法都有缺陷:前者每个分类器只能看到目标的一部分,而后者则存在大量的冗余参数。相反,这里讲分类层分解成两个中间不带非线性的线性层。这样一来,能够降低网络的参数个数,却允许每个像素分类器都能够利用到整个特征图的信息。实验证明了这种方式的有效性。最后,为了进一步降低模型容量,这里将输出层设为 h o × w o h^o\times w^o ho×wo,其中 h o < h h^o\lt h ho<h, w o < w w^o\lt w wo<w,再用上采样层将结果采样回原始尺寸。
scoring: 网络的第二个分支致力于估计一个图块的中心是否包含1和2:即目标是否在图块中新且尺度合适。这个由两个2x2的最大池化层,加上两层全连接层(带ReLU)组成。最后的输出是一个目标score,显示图块中新是否显示了目标(合适尺度下)。
Joint Learning
给定一个输入图块 x k ∈ I x_k\in \mathcal I xk∈I,模型联合训练像素级分割mask和目标score。损失函数是binary logistic regression losses之和,一个对应分割,一个对应目标score,整体训练triples ( x k , m k , y k ) (x_k,m_k,y_k) (xk,mk,yk)的损失函数如下:
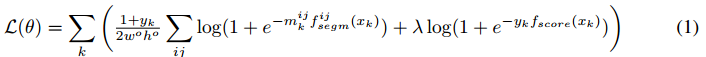

注意,如果 y k = 1 y_k=1 yk=1,反向传播值传播分割分支的error。当然也可以用复数训练(在 y k = 0 y_k=0 yk=0时设定 m k i j = 0 m_k^{ij}=0 mkij=0),但是作者发现只用整数训练对于生成更高recall的结果更有利。这样做会使得网络尝试对每个图块都生成分割mask,即使中间没有目标。
Full Scene Inference
在整图推理时,这里应用了在多个位置和尺度下的稠密模型。这点是必要的,因为对于图像中的每个目标我们都至少测试了一个图块完整包含了这个目标(中心、尺度合适)。这个过程给出了图像每个位置的分割mask和目标score。下图展示了模型应用与一个尺度下的图片的分割输出。

注意,网络的scoring分支有一个比粉各分支大两倍的下采样率,因为额外的最大池化层。给定一个测试图像尺寸为 h t × w t h^t\times w^t ht×wt,分割和目标网络生成输出石村分别为 h t 16 × w t 16 \frac{h^t}{16}\times\frac{w^t}{16} 16ht×16wt和 h t 32 × w t 32 \frac{h^t}{32}\times\frac{w^t}{32} 32ht×32wt。为了在分割和score分支之间实现一对一的映射,作者在最后的最大池化层之前应用了interleaving trick(交叉存储技巧),从而使得scoring分支的分辨率翻倍。
Implementation Details
在训练过程中,如果目标在图块的正中间且最大维度精确等于128像素,则一个图块 x k x_k xk被认为包括一个canonical正样本。然而,容忍度非常重要。因此在训练过程中,给了一点片质量,范围为正负16个像素,尺度为 2 ± 1 / 4 2^{\pm1/4} 2±1/4,同时也考虑了水平翻转。在所有情况下,我们都应用相同的变换对图块 x k x_k xk和真值mask m k m_k mk,并给正样本分配标注 y k = 1 y_k=1 yk=1。负样本 y k = − 1 y_k=-1 yk=−1是那些图块至少距离标准正样本 ± 32 \pm32 ±32个像素或尺度上 2 ± 1 2^{\pm 1} 2±1。
在整图推理时,我们在多个位置(步长16个像素)和尺度(从 2 − 2 2^{-2} 2−2到 2 1 2^1 21,步长 2 1 / 2 2^{1/2} 21/2)应用了稠密模型,这保证了至少一个测试图块包含图像中的整个目标(在训练中带容忍度的)。
如在原始VGG-A网络中,我们的模型输入也是RGB图块,维度为 3 × 224 × 224 3\times 224\times224 3×224×224。因为溢出了第五个池化层,共同分支输出的特征图维度为 512 × 14 × 14 512\times 14\times14 512×14×14。网络的score分支有一个 2 × 2 2\times 2 2×2最大池化层厚街两个全连接层(512和1024个hidden units)组成。这些曾都跟着ReLU和dropout(比率0.5)。最后一层生成目标score。
分割网络有一个1x1的卷积层(512个单元)组成。特征图随后全连接到低维(512),再进一步全连接到每个像素的分类器以生成输出维度 56 × 56 56\times56 56×56。如前文讨论的,在这两层之间没有非线性。总体而言,我们的模型包括大约75M的参数。
最后的一个双线性上采样层加载56x56的输出后面用来生成完整的224x224分辨率的估计(如果直接估计原始分辨率会非常慢)。我们用了一个不学习的层,因为发现即使学习,其也是简单地学了一个双线性上采样。替代的是用下采样真值而非上采样网络输出,但是这种做法稍微影响了精度。
在MS COCO数据及下选择的超参数,学习率0.01,batch size 32,动量0.9,weight decay 0.00005.除了预训练的VGG特征,权重随机初始化(平均分布)模型训练大概需要5天,设备为Nvidia Tesla K40m。
Experimental Results
Conclusion
更多内容,欢迎加入星球讨论。

这篇关于【阅读笔记】《Learning to Segment Object Candidates》(DeepMask)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







