本文主要是介绍Java项目(二)--Springboot + ElasticSearch 构建博客检索系统(2)- 博客网站全文检索实现思路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
博客网站全文检索实现思路
基于MySQL实现
在MySQL创建表为t_blog,然后增加测试数据。
CREATE TABLE `t_blog` (`id` int(11) PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',`title` varchar(60) DEFAULT NULL COMMENT '博客标题',`author` varchar(60) DEFAULT NULL COMMENT '博客作者',`content` mediumtext COMMENT '博客内容',`create_time` datetime DEFAULT NULL COMMENT '创建时间',`update_time` datetime DEFAULT NULL COMMENT '更新时间') ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4;
如果使用MySQL实现全文检查,查询语句为:
SELECT * FROM t_blog WHERE title LIKE '%spring%' OR content LIKE '%spring%';
在数据量很少的时候这种查询还能应付应用,但是数据量变大之后就会变得很慢,并且查询的时候占用资源无法释放。
优化这种查询,人们就想到了添加索引。
数值型或者字符串类型的全文比较的话,索引是有效果的。但是如果使用like去查询建了索引的字段,索引效果就会失效,不仅如此,他还会做全表的扫描。
虽然说MySQL已经支持了fulltext的索引的类型,它依然不是很适合全文检索的场景。因为当我们数据量越来越多的时候,我们不可避免的面临分布式架构,相应的我们数据也需要拆分,也就是分库分表。分库分表如果对应的是ID或者其他数值类型的字段,我们可以使用哈希或者其他数据分片的规则,从而让分布式数据库中间件,如MyCat或者sharding-jdbc,帮我们能映射到具体的数据的节点。但是搜索的业务场景是一种模糊匹配,且并不知道用户会输入什么样的字符,没办法对用户输入的数据做哈希或者其他数据分片的算法,从而也就无法实现单库节点的准确映射,从而对后端的所有节点全部做一次全表扫描,再由中间件处理返回结果,这个时候结果过滤的阶段,查询效率就会更加的低。由此MySQL不太适合全文检索的业务场景。
基于ES实现
ES的索引是使用了倒排索引,如图所示。
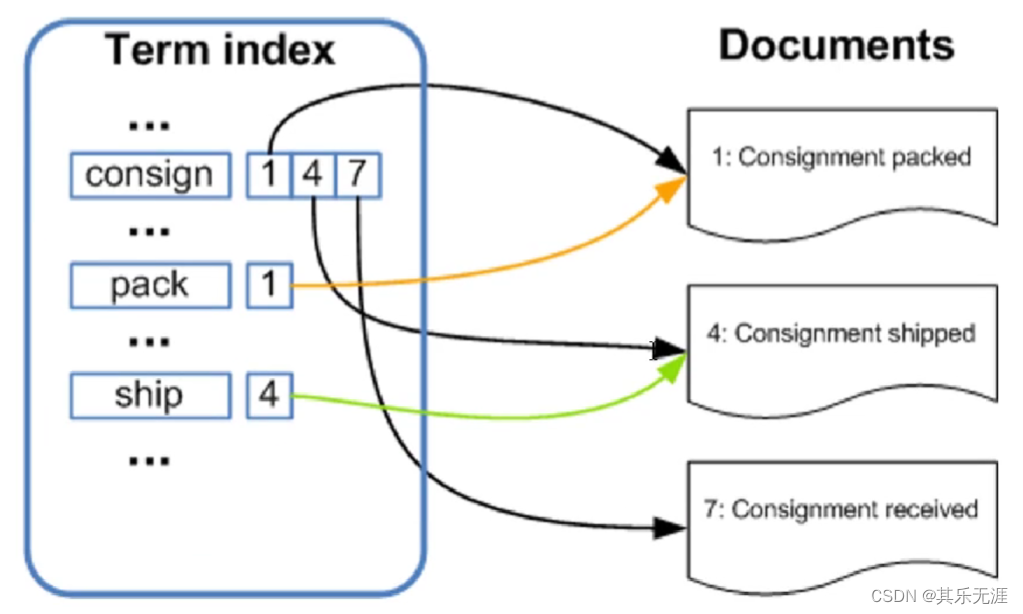
首先ES对我们新增的数据会分词,分词的规则可以是原生的内部支持的分词规则,也可以使用特别的分词来实现。分词以后ES会维护最小词源到文档的映射。得到用户输入的词后进行拆分,形成最小的词源找到对应的文档,最后把结果整合以下返回给用户。
ES相较于MySQL,拥有更好的分布式或者水平扩展的能力。一个运行中的ES实例,我们称之为节点,整个集群由一个或者多个相同cluster.name配置的节点组成的,他们共同承担着数据以及负载的压力。当有节点加入集群,或者从集群当中移除某个节点的时候,整个集群会重新平均分布所有的数据。

比如上图,ES的CLUSTER最初只有两个节点NODE1、NODE2,后面新加入了节点叫NODE3。当这个节点一进来,集群之前选举出来的主节点就会感知到,并且做后续的管理及负载编排的工作。首先,主节点负责管理集群范围内的所有变更,比如说增加索引、删除索引,或者增加节点、删除节点等。而主节点并不涉及到文档级别的变更和搜索等一系列操作。所以集群当只有一个主节点的情况下,即使用户流量非常大、非常高,它也不可能成为瓶颈。与此同时,任何节点都可以成为主节点。
我们的实例集群虽然只有一个节点,即这个节点即是主节点,也是从节点。用户把请求发送到集群当中任意节点,当然也包括主节点,哪个节点都知道任意文档存储的位置,并且能够将请求直接转发到存储所需文档的具体节点。所以无论将请求发送到哪个节点,他都能负责从各个包含所需文档目标节点当中收回数据,并且最终把结果展示给客户端。
MySQL、ES数据同步
数据同步中间件
全量:第一次建立完ES索引之后,把MySQL的数据一次性全部打包同步过去。
增量:全量同步之后,MySQL产生新的数据,包括新插入的数据、以前的老数据得到Update、以前的老数据得到Delete,这三种情况同样的需要同步到ES的Index里面去,然后让他对应的去做新增、更新、删除。
那怎么样把MySQL数据同步到ES呢?
全量同步的话,单独写个脚本,如select * from t_blog,得到数据之后再程序里面再循环,然后得到数据插入到ES。
但是正好执行的时候,又有新的数据进来了,怎么办?
可以记录一个maxCreateTime,每一次全表扫描的时候记录当前扫描到的数据里面的最大的创建时间,然后扫描的时候小于等于这个创建时间。等到这批同步到ES之后,后续还会有更多的定时任务去大于上次记录的最大时间,然后同样的过程反复进行下去。这样就保证第一次全量同步,后续的定时任务不断的进行增量的同步数据。
还有种思路是,针对增量同步数据,在代码里配置一个切面就可以了,对于每个方法写一个ES的CRUD的切面,就可以实现数据的同步了。切面乍一听很高大上,但是它使代码、业务、数据这三者耦合度太高了,不利于业务和数据的隔离。
其实对数据同步问题,开源社区或ES官方早就给出了一些解决方案了。
开源中间件
首先,第一个基于MySQL的binlog订阅。
binlog可以说是一种日志,它用来实时记录MySQL数据产生的一些变化,然后通过MySQL的主从复制协议,自己实现一个客户端,然后和MySQL的一个主节点进行连接。其实就是把自己伪装成一个从节点。接下来,主节点只要发生了数据变更,他就会把这个变更的事件传递给客户端。
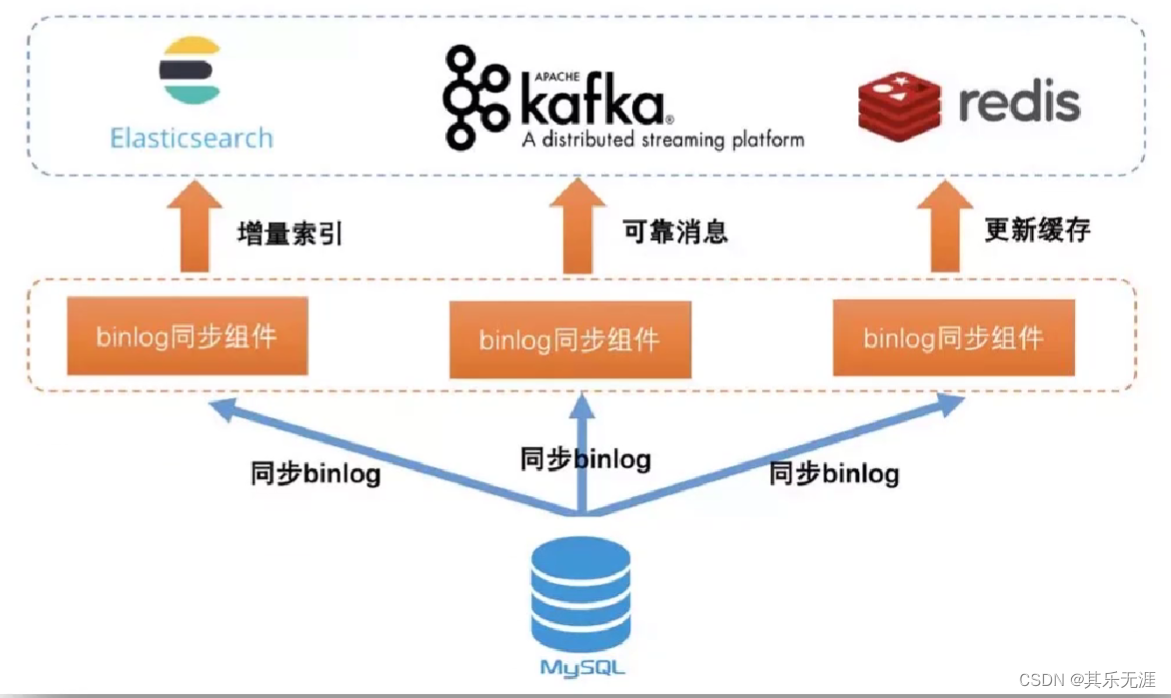
binlog同步组件,国内已经有做的很好的,如阿里巴巴的canal。还有go语言实现的go-mysql-elasticshearch(还不支持ES 6.x以上版本,也不支持MySQL 8版本),目前中间件还处于开发阶段,还不够成熟。
ES官方数据收集及同步组件,它叫logstash。

logstash的输入源可以有很多,比如说log4j。
logstash-JDBC设计于用于对接MySQL等数据源。实现方式有点像上面提到的思路(每次记录时间增量同步),具体的要求有以下几点:
首先,id对应的Elasticsearch里面_id,id设置必须来着MySQL中的id字段,它提供了MySQL和Elasticsearche之间,就是文档数据之间映射关系。如果一条记录在MySQL更新,那么Elasticsearch所有关联文档都应该被重写(先把之前的文档删除,再新增一个新的文档,因为他没有Update操作)。
另外一个,MySQL表里必须有一个标识创建时间或更新时间的字段。Logstash可以实现每次请求只获取上次轮询后,更新或插入的数据。其实给他标识了一个maxTime最大时间,下次通过和这个最大时间的比较,能够完成增量的同步。
logstash全量、增量同步解决方案
首先,安装logstash,下载路径如下,选好版本下载解压即可。(logstash版本尽量和ES版本保持一致)
https://www.elastic.co/cn/downloads/past-releases#logstash
因为需要和MySQL进行jdbc的连接,需要下载mysql-connector-java.jar包(注意版本跟mysql版本要一致),下载地址如下,下载完把jar包放到logstash解压路径下。
https://search.maven.org/artifact/mysql/mysql-connector-java/8.0.29/jar
然后在config目录下新建文件为mysql.conf
input{jdbc{# jdbc驱动包位置jdbc_driver_library => "D:\\elastic\\logstash-6.8.23\\mysql-connector-java-8.0.29.jar"# 要使用的驱动包类jdbc_driver_class => "com.mysql.cj.jdbc.Driver"# mysql数据库的连接信息jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/es-db"# mysql用户jdbc_user => "root"# mysql密码jdbc_password => "root"# 定时任务,多久执行一次查询,默认一分钟,如果想要没有延迟,可以使用 schedule => "* * * * * *"schedule => "* * * * *"# 清空上传的sql_last_value记录clean_run => true# 你要执行的语句statement => "select * FROM t_blog WHERE update_time > :sql_last_value AND update_time < NOW() ORDER BY update_time desc"}
}output {elasticsearch{# es host : porthosts => ["127.0.0.1:9200"]# 索引index => "blog"# _iddocument_id => "%{id}"}
}
然后执行logstash,cmd窗口切换到D:\elastic\logstash-6.8.23\bin目录,然后执行logstash -f …/config/mysql.conf(执行之前得保证ES已经启动)
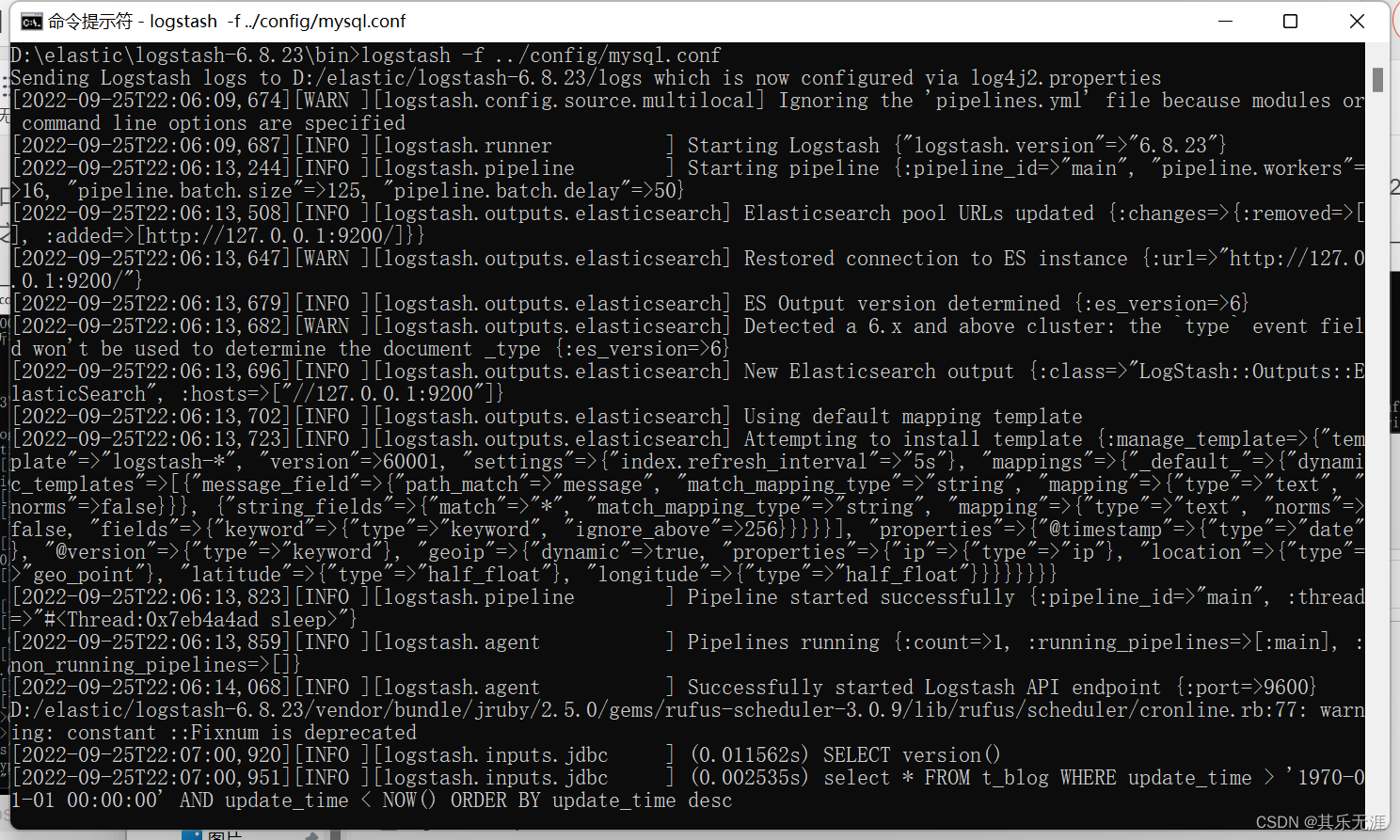
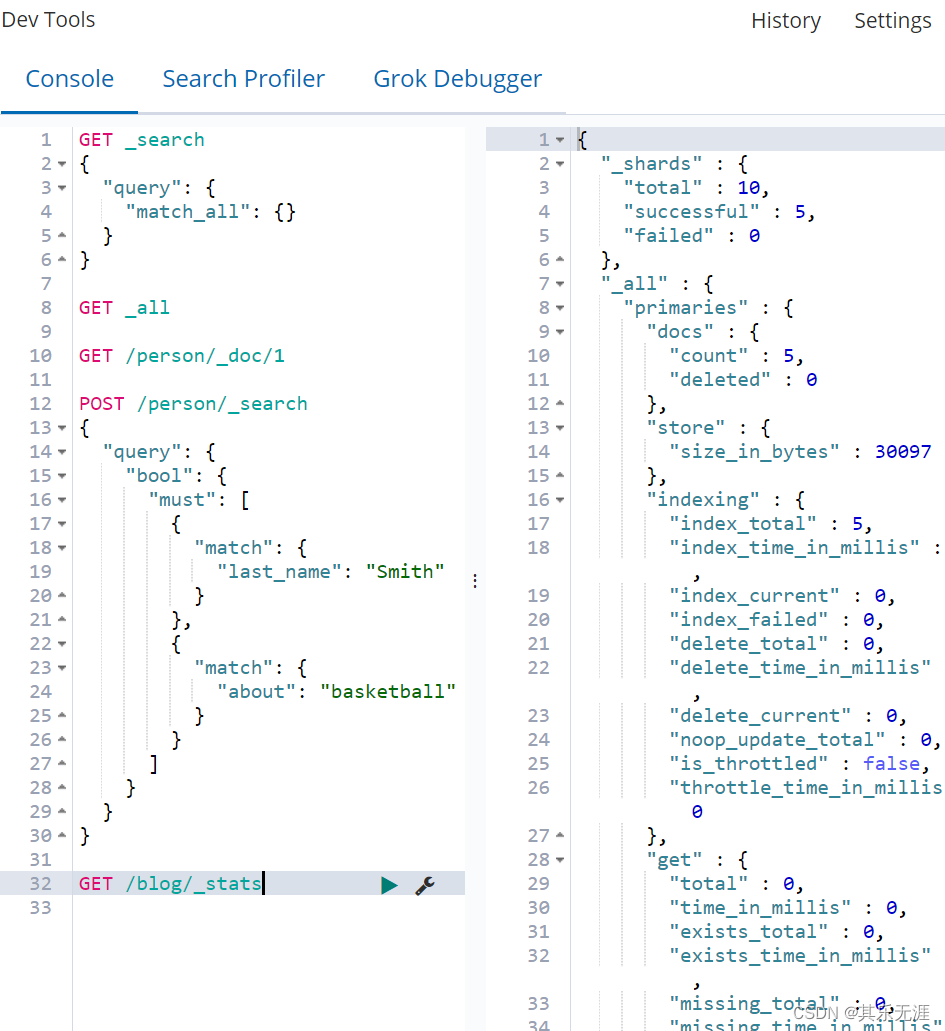
然后Kibana界面执行GET /blog/_stats
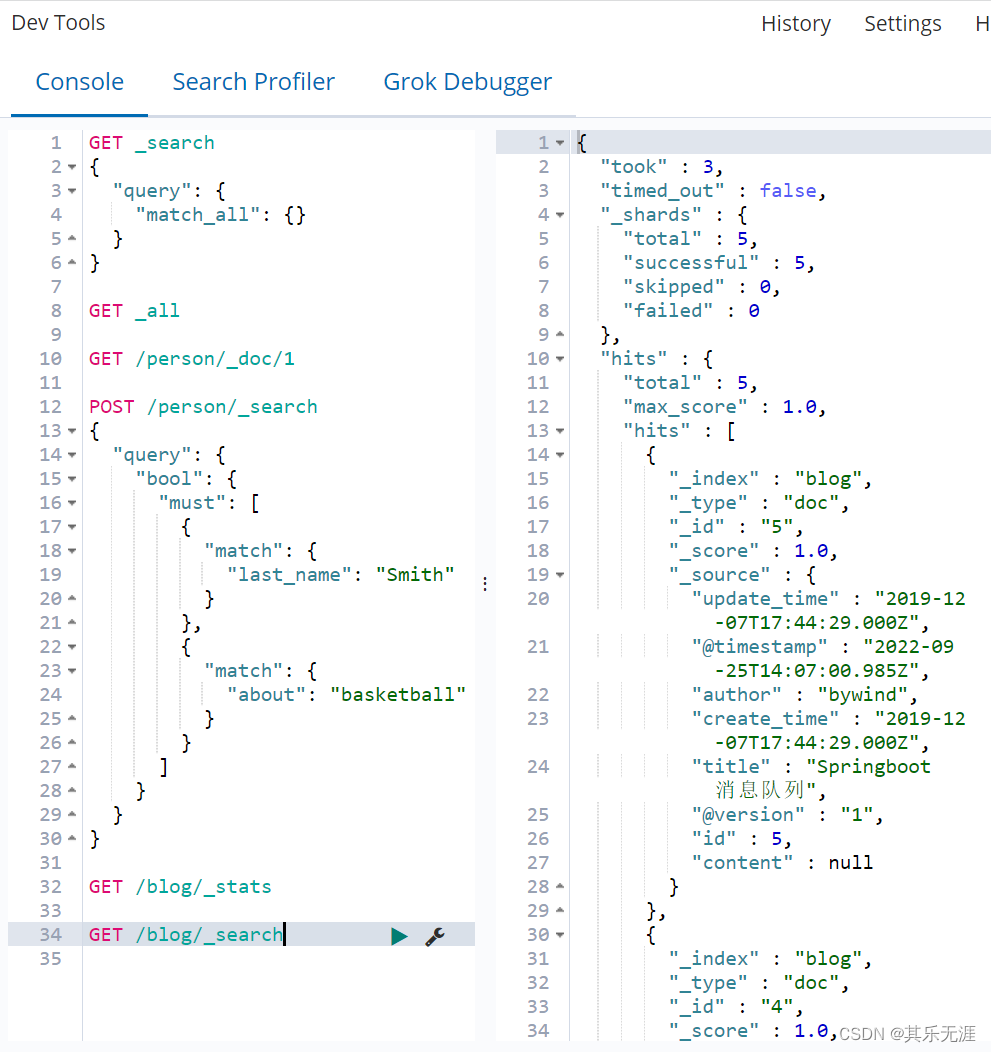
在Kibana界面执行GET /blog/_search也能查到数据
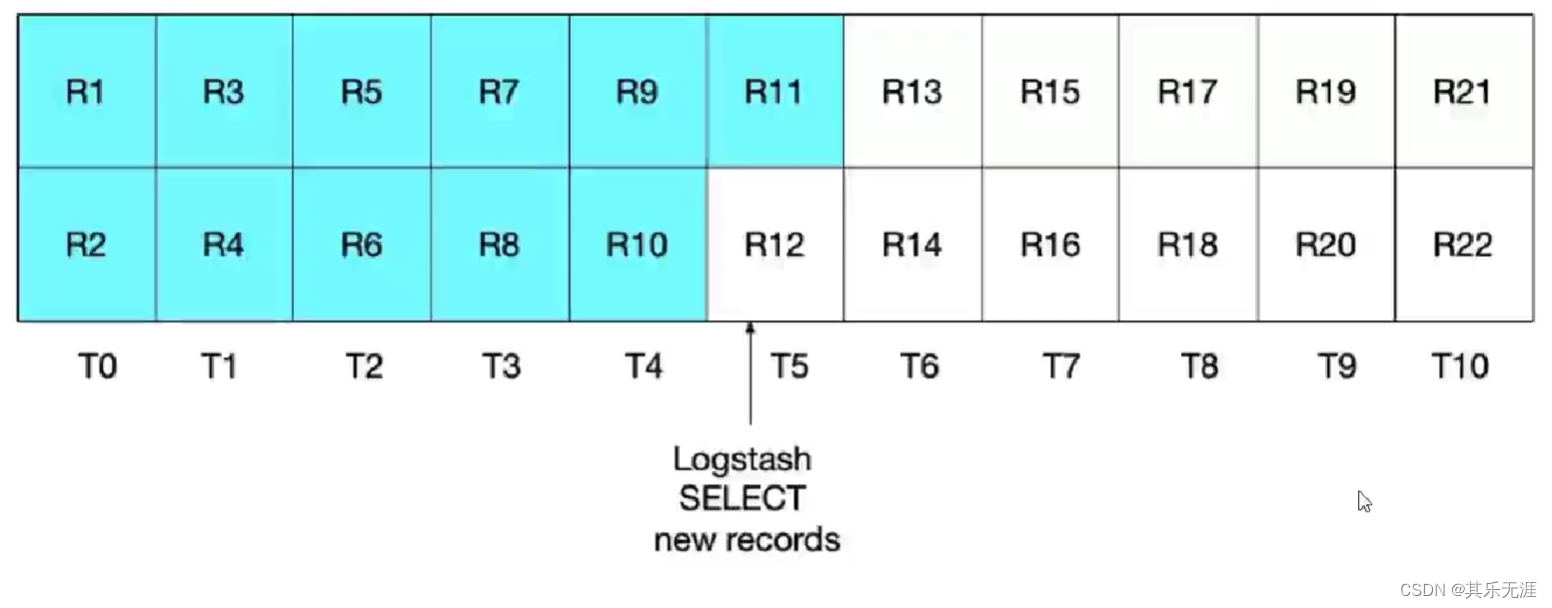
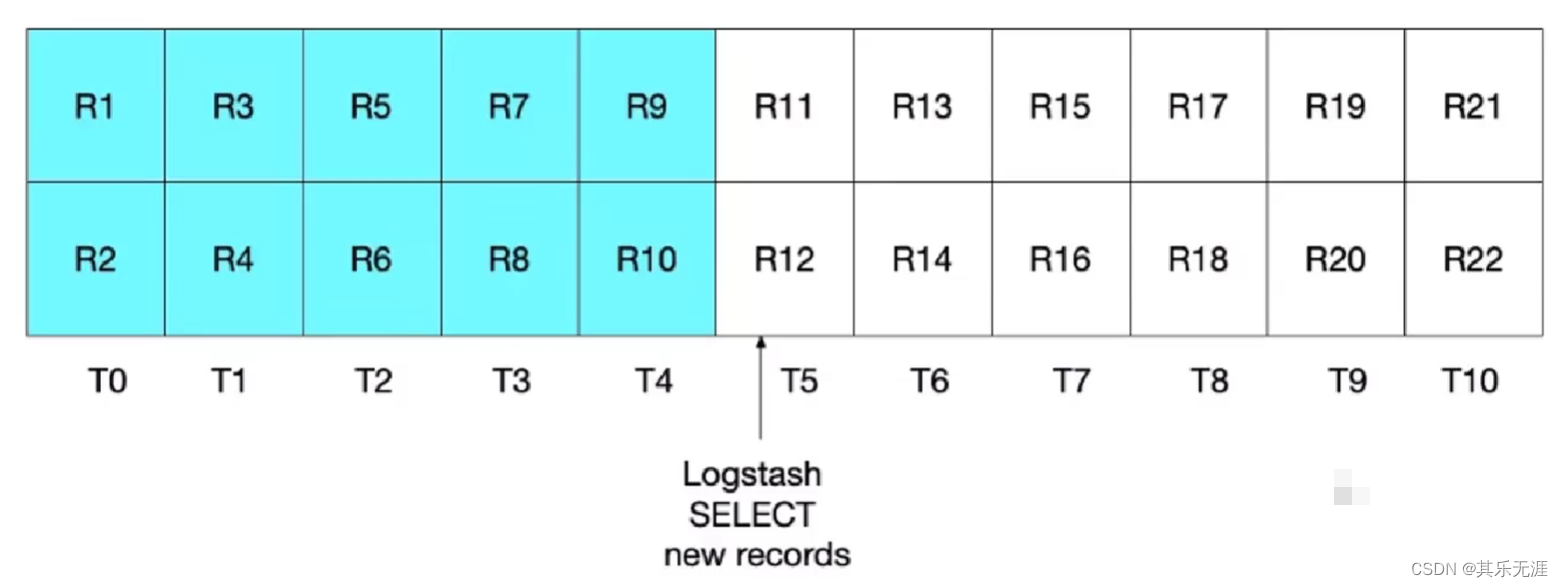
最后谈谈,需要执行的sql语句的演变由来,它其实经过三次迭代,最初版本为:
select * FROM t_blog WHERE update_time > :sql_last_value ORDER BY update_time desc
这个sql会产生如图所示,记录时间临界点的数据可能不会被扫描到。
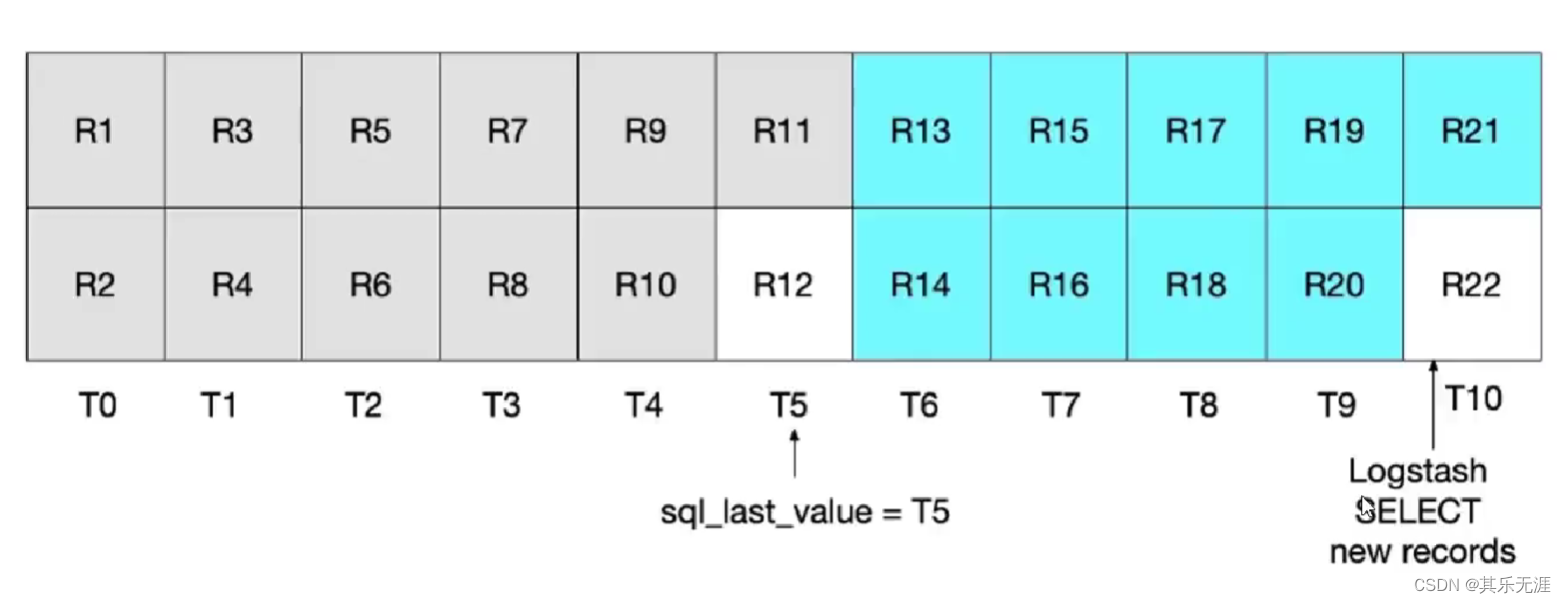
为了扫描到临界点的数据,把sql进行了升级为:(把条件改为update_time >= :sql_last_value)
select * FROM t_blog WHERE update_time >= :sql_last_value ORDER BY update_time desc
这个sql执行的结果就是,会把上次最后一个临界点的数据也会重复扫描上,数据量大了之后会产生额外的性能开销。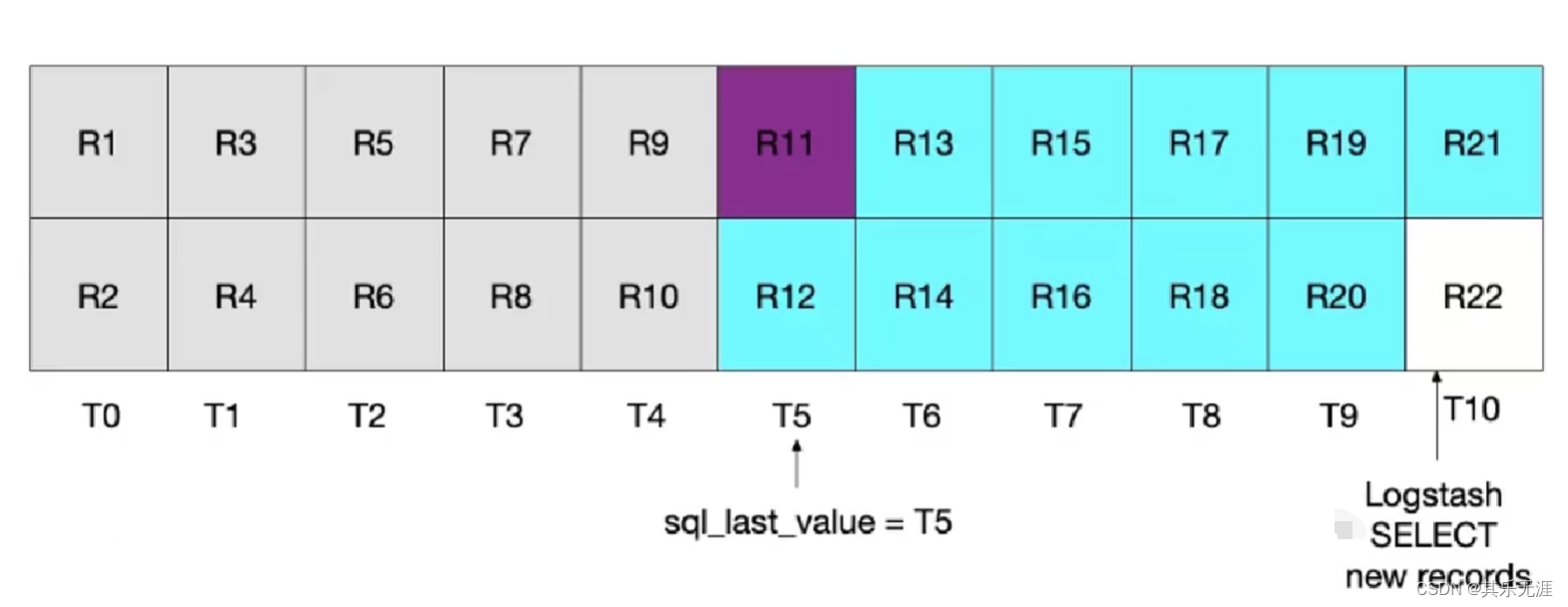
最后sql升级为当前版本:
select * FROM t_blog WHERE update_time > :sql_last_value AND update_time < NOW() ORDER BY update_time desc
两个条件同时满足的情况下很好的解决临界点数据的扫描问题。
这篇关于Java项目(二)--Springboot + ElasticSearch 构建博客检索系统(2)- 博客网站全文检索实现思路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





