全文检索专题

SQL Server 2000中全文检索的使用
微软的SQL Server数据库是一个在中低端企业应用中占有广泛市场的关系型数据库系统, 它以简单、方便、易用等特性深得众多软件开发人员和数据库管理人员的钟爱。但SQL Server 7.0以前的数据库系统由于没有全文检索功能,致使无法提供像文本内容查找此类的服 务,成为一个小小的遗憾。从SQL Server 7.0起,到如今的SQL Server 2000终于具备了全文

Django 2.1.7 全文检索
全文检索 全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理。 haystack:全文检索的框架,支持whoosh、solr、Xapian、Elasticsearc四种全文检索引擎,点击查看官方网站。whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃,对

Elasticsearch全文检索学习
ElasticSearch官方网址:https://www.elastic.co ElasticSearch官方网址(中文):https://www.elastic.co/cn/ Elasticsearch 权威指南(中文版文档,在线观看):https://es.xiaoleilu.com/ 1、ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文

Lucene的全文检索学习
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/ 1、什么是Lucene? Lucene 是 apache 软件基金会的一个子项目,由 Doug Cutting 开发,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的库,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为

Elasticsearch 6.x版本全文检索学习之数据建模
1、什么是数据建模。 答:数据建模,英文为Data Modeling,为创建数据模型的过程。数据模型Data Mdel,对现实世界进行抽象描述的一种工具和方法,通过抽象的实体及实体之间联系的形式去描述业务规则,从而实现对现实世界的映射。 2、数据建模的过程。 答:第一步、概念模型,确定系统的核心需求和范围边界,设计实体和实体间的关系。 第二步、逻辑模型,进一步梳理业务需求,确定每个
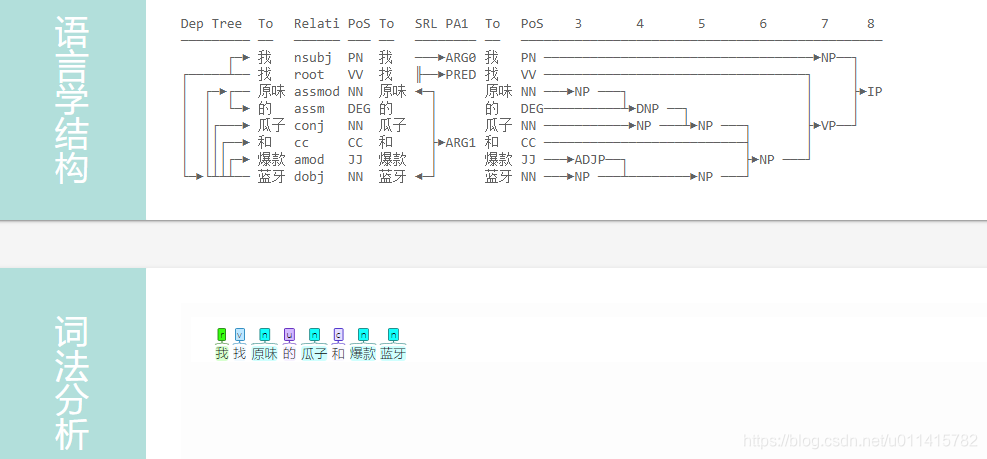
ThinkPHP5 使用迅搜 (XunSearch) 实现全文检索实例指导
前期准备 入坑了一天,折腾的无语,个人观点:【文档太差,适合学习思路,小心入坑】 背景 最近在整理全文检索解决方案 注意到 PHP 环境中对 xunsearch 的评价很高,在此记录一番 【Xunsearch 是一个高性能、全功能的全文检索解决方案】 场景描述 此处作为对 xunsearch 的初次使用, 以一个简单的商品 SKU 信息搜索场景进行描述 我已有一张 tp5

MongoDB全文检索: 助力快速精准的文本搜索
MongoDB 全文检索是一种强大的功能,允许用户在文档中进行高效的文本搜索。它提供了对文本数据的复杂查询和索引支持,使得在大规模数据库中进行搜索变得更加快速和精确。本文将详细介绍 MongoDB 全文检索的基本语法、命令、示例、应用场景、注意事项,并进行总结。 全文检索详解 MongoDB 的全文检索通过创建文本索引来实现,允许在集合中对一个或多个字符串字段进行搜索。文本索引支持多种语言和复

全文检索:倒排索引的理解
一.定义:是基于单词-文档矩阵的一种存储形式,它描述了一个term词项集合和文档集合之间具有映射关系的数据结构。 1. term词项集合列表:定义要搜索的一些词。 2. 词项文档映射集合列表:定义单词id,单词,单词在文档中的位置,单词出现的频率,文档出现的频率等信息。 文档列表: 词项集合 :

分布式全文检索引擎Elasticsearch简单介绍
1、Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。 但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。 Elasticse

全文检索ElasticSearch简介
1 全文检索 1.1 什么是全文检索 全文检索是一种通过对文本内容进行全面索引和搜索的技术。它可以快速地在大量文本数据中查找包含特定关键词或短语的文档,并返回相关的搜索结果。全文检索广泛应用于各种信息管理系统和应用中,如搜索引擎、文档管理系统、电子邮件客户端、新闻聚合网站等。它可以帮助用户快速定位所需信息,提高检索效率和准确性。 1.1.1 查询与检索 查询:有明确的搜索条
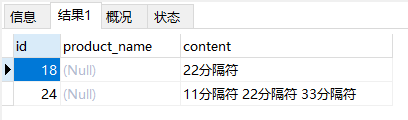
使用mysql实现全文检索功能
查看系统默认分片规则 默认INNODB下 最小分片为3位 空格切分 show variables like '%ft%'; -- 查看默认分配规则 建表 -- 创建表create table test (id int(11) unsigned not null auto_increment,product_name varchar(255),content text not null
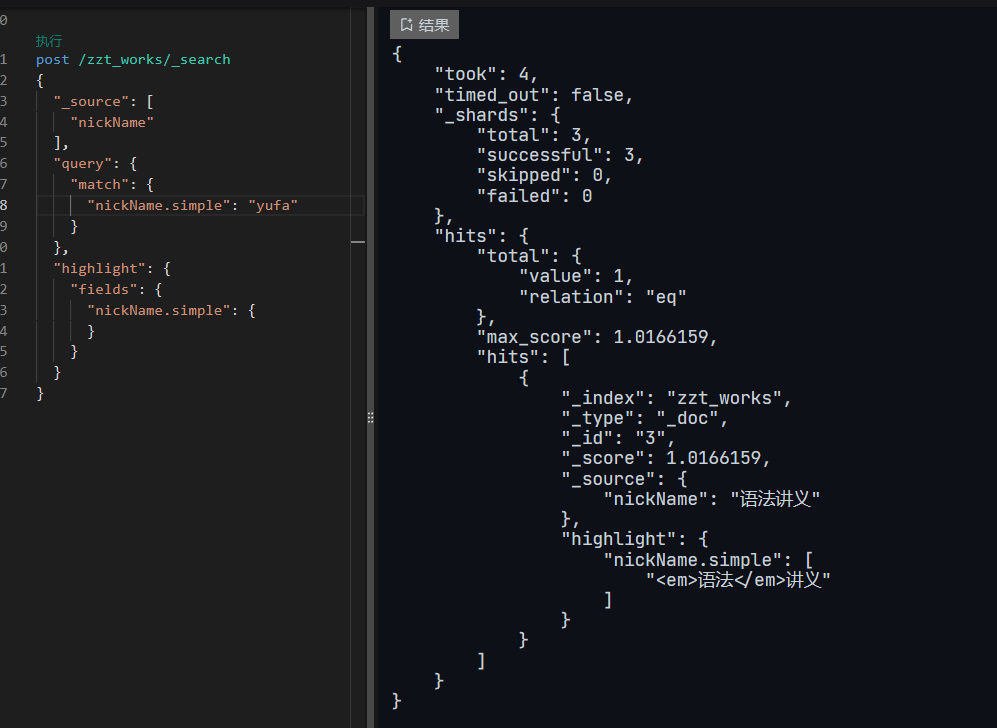
ES全文检索支持拼音和繁简检索
ES全文检索支持拼音和繁简检索 1. 实现目标2. 引入pinyin插件2.1 编译 elasticsearch-analysis-pinyin 插件2.2 安装拼音插件 3. 引入ik分词器插件3.1 已有作者编译后的包文件3.2 只有源代码的版本3.3 安装ik分词插件 4. 建立es索引5.测试检索6. 繁简转换 1. 实现目标 ES检索时无论输入简体还是繁体都要能够被检索
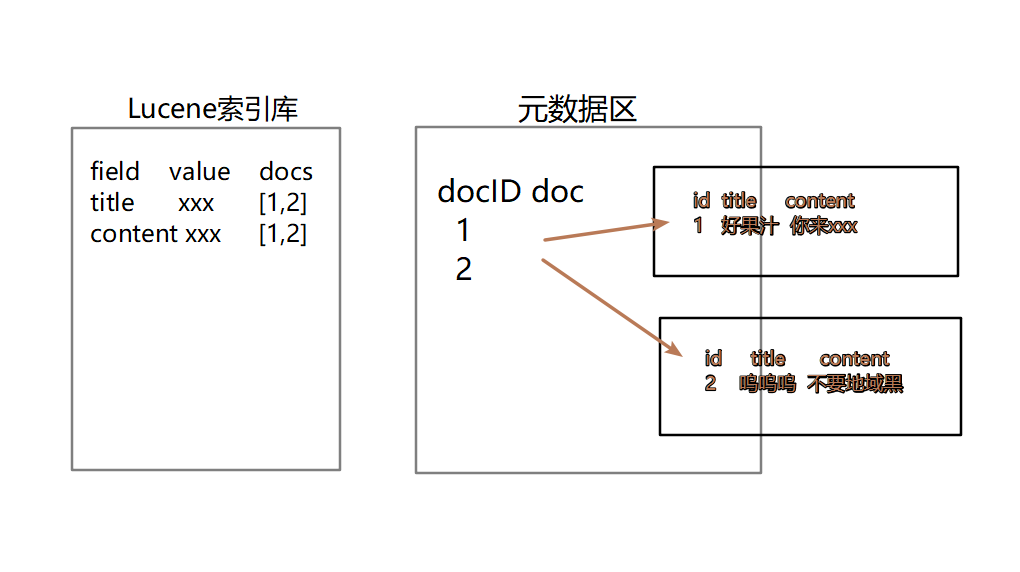
Lucene全文检索入门使用
一、 什么是全文检索 全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程 全文检索(Full-Text Retrieval)以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。 关于全文检索,我们要知道: 1、只处理文本。 2,不处理语义。
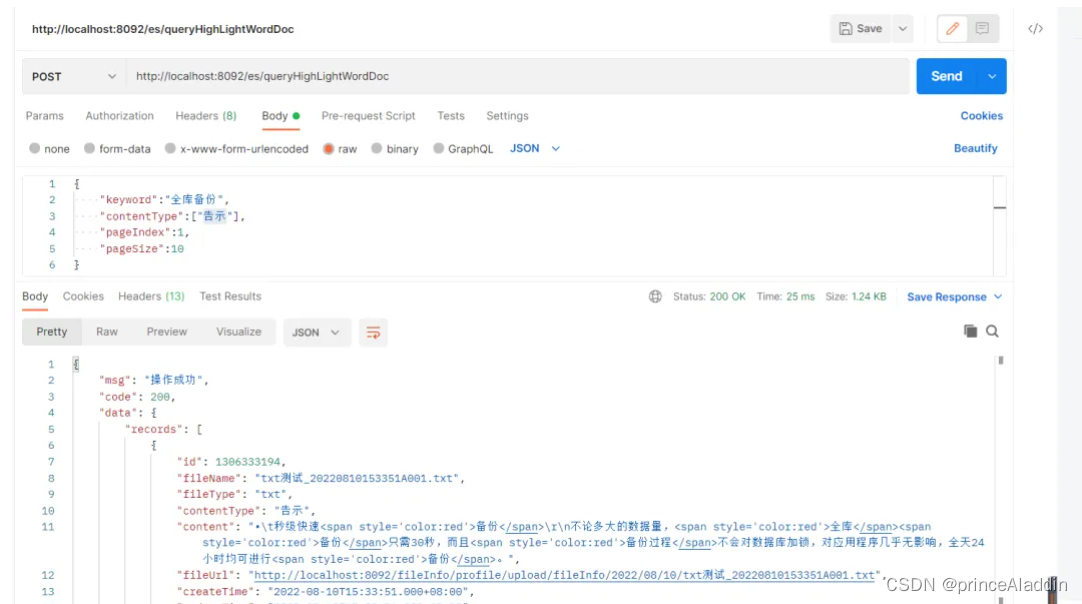
SpringBoot+ElasticSearch实现文档内容抽取、高亮分词、全文检索
需求 产品希望我们这边能够实现用户上传PDF、WORD、TXT之内得文本内容,然后用户可以根据附件名称或文件内容模糊查询文件信息,并可以在线查看文件内容。 一、环境 项目开发环境: 后台管理系统springboot+mybatis_plus+mysql+es 搜索引擎:elasticsearch7.9.3 +kibana图形化界面 二、功能实现 1.搭建环境 es+kibana的搭建这里就不
关于mongodb的全文检索
1.在fulltextserach 需要用到切词,切词和语言有关,所以需要设置语言,目前不支持中文,只支持如下的: http://blog.csdn.net/terry_water/article/details/43671749 2.在使用前,在mongodb需要用命令行设置text索引 设置单个字段索引: db.catalog_product.ensureIndex({descri
HDU 1277 全文检索 (Trie树应用 好题)
全文检索 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission(s): 1304 Accepted Submission(s): 416 Problem Description 我们大家经常用google检索信息,但是检索信息的

全文检索ElasticSearch与Spring boot集成实例
全文检索1.全文搜索概念:(1)数据结构:·结构化:只具有固定格式或者有限长度的数据,如数据库,元数据等·非结构化:指不定长或者无固定格式的数据,如邮件,word文档等(2)非结构化数据的检索:·顺序扫描法:适合小数据量文件·全文搜索:将非结构化的数据转为结构化的数据,然后创建索引,在进行搜索(3)概念:全文搜索是一种将文件中所有文本域搜索项匹配的文件资料检索方式2.全文搜索实现原理3.全文搜索
SQL Server 2000 全文检索
使用 CONTAINSTABLE 和 FREETEXTTABLE 赋值行集函数 CONTAINSTABLE 和 FREETEXTTABLE 函数用来指定返回每行的相对排名的全文查询。这两个函数与全文谓词 CONTAINS 和 FREETEXT 很相似,但是用法不同。 区分全文谓词与函数 虽然全文谓词和全文赋值行集函数都用于全文查询,而且二者用来指定全文检索条件的 Transact-SQL 语

使用卓正PageOffice--Word文档全文检索
2019独角兽企业重金招聘Python工程师标准>>> 一、 背景介绍 Word文档与日常办公密不可分,在实际应用中,当某一文档服务器中有很多Word文档,假如有成千上万个文档时,用户查找打开包含某些指定关键字的文档就变得很困难,目前网络上能找到的解决方案多是使用服务器端的Apache POI技术将所有文档的文本获取后存储到数据库,然后打开文档时利用sql语句检索文档是否包含关键字来判
MySQL全文检索fulltext日语解析插件MeCab学习笔记
MySQL原始内置的全文检索(Full-Text Search)只适用于像英文这些词语之间有天然分隔符(如空格)的自然语言,MySQL5.7.6开始引入ngram full-text parser plugin,采用手动设置词语长度的方式进行人工分词,这可以作为CJK(Chinese、Japanese、Korean)语系全文检索的手段,具体可以参考之前的使用笔记:https://blog.csdn
NEO4J全文检索架构
NEO4J全文检索架构 一、有大量存量数据(亿级以上)(并长期有增量数据进入)二、无大量存量数据或者少量存量数据(或全部为增量数据)三、架构方案选择优先级 以下方案,是根据实践总结的基于NEO4J的全文检索解决方案,各有优缺点,仅供参考。以下总结全部基于neo4j-3.4.9版本,至于升级到3.5.x之后的版本索引有了大幅提升,还未做测试。 一、有大量存量数据(亿级以上)(

基于Bboss快速构建高效、可靠、安全的Elasticserach全文检索以及统计分析应用
一、简介 Bboss后端基于Gradle模块化构建,灵活便捷。框架模块丰富,涵盖数据同步ETL工具、J2ee开发框架、微服务、数据库、中间件、安全、配置、缓存、国际化、elasticsearch client、web session共享、redis、kafka、mongodb工具包等常用模块,最大程度满足开发需要。同时,严格遵守WEB安全规范,从根本上避免SQL注入、XSS攻击、CSRF攻击等常
04、全文检索 -- Solr -- 管理 Solr 的 core(使用命令和图形界面创建、删除 core,以及对core 目录下的各文件进行详细介绍)
目录 管理 Solr 的 core创建 Core方式1:solr 命令创建演示:使用 solr 命令创建 Core:演示:命令删除 Core(彻底删除) 方式2:图形界面创建Web控制台创建CoreWeb控制台删除 Core(未彻底删除)重新加回刚刚删除的core Core 目录下的文件介绍:创建的 core 对应的目录下的文件:Core 目录的 conf 子目录下的文件:managed
02、全文检索 ------ Solr(企业级的开源的搜索引擎) 的下载、安装、Solr的Web图形界面介绍
目录 Solr 的下载和安装Solr的优势:Lucene与Solr 安装 Solr1、下载解压2、添加环境变量3、启动 Solr Solr 所支持的子命令:Solr 的 Core 和 Collection 介绍Solr 的Web控制台DashBoard(仪表盘)Logging(日志)Core Admin(Core管理)Java Properties(Java属性)Thread Dump(线程