本文主要是介绍ThinkPHP5 使用迅搜 (XunSearch) 实现全文检索实例指导,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前期准备
入坑了一天,折腾的无语,个人观点:【文档太差,适合学习思路,小心入坑】
-
背景
最近在整理全文检索解决方案
注意到PHP环境中对xunsearch的评价很高,在此记录一番
【Xunsearch 是一个高性能、全功能的全文检索解决方案】
-
场景描述
此处作为对
xunsearch的初次使用,
以一个简单的商品SKU信息搜索场景进行描述
我已有一张tp5_xsku表,用来存储商品SKU信息
主键为"sku_id",需要进行匹配的字段为:"spec_name"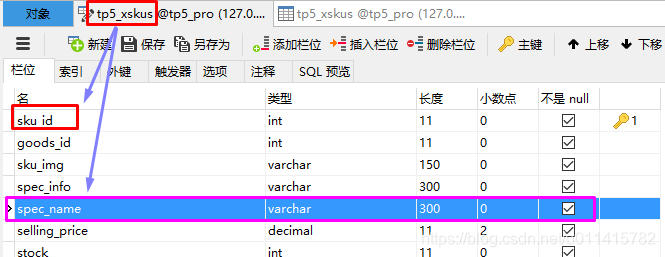
-
环境
PHP: php7.2.9
Linux: CentOS7.9
MySQL: mysql5.7.32
☞ XunSearch 服务端搭建
- 此处,我将网站应用部署在本地
windows环境
然后,使用一台虚拟机【192.168.80.224】作为xunsearch服务器的部署环境
官方指导文档 ——
【安装、升级 Xunsearch】
1). 运行下面指令下载、解压安装包
- 此处,我选择的是一台
CentOS7的虚拟机 [ip:192.168.80.224],作为服务端
wget http://www.xunsearch.com/download/xunsearch-full-latest.tar.bz2
tar -xjf xunsearch-full-latest.tar.bz2
2). 执行安装脚本
- 首先,建议将解压后的文件夹移动到
"usr/local/"目录下
此处,我做了文件夹重命名、拷贝操作
mv xunsearch-full-1.4.15/ xunsearch
cp -r xunsearch /usr/local/xunsearch
- 然后执行安装脚本命令
选择默认即可(第一次安装的话,过程可能会稍显漫长)
cd /usr/local/xunsearch/
sh setup.sh
- 一般没啥问题,最终成功提示信息如下:
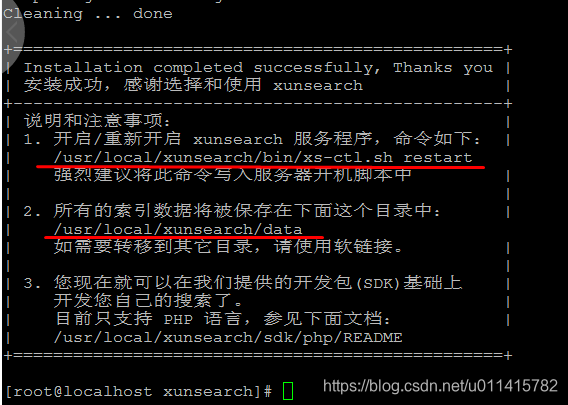
因为我的
SDK调用和xunsearch 服务端不在同一服务器,所以使用"-b inet"方式启动脚
/usr/local/xunsearch/bin/xs-ctl.sh -b inet start
【提示】:
- 注意官方建议的
不同启动方式,不然坑死你
其次,测试发现,如果我直接删掉了"/usr/local/xunsearch/data"文件夹,后续直接没反应
需要重启xunsearch服务方可!(也没见官网提示)
不过,只是删除"/usr/local/xunsearch/data/"内的文件夹,是无需重启的!
3). 设置端口号
- 通过对
xunsearch的启动命令操作发现,需要有端口号"8383、8384"的支持
注意借助类似iptables的防火墙,
来控制xunsearch的8383/8384两个端口的访问权限

- 启动完成后,可以输入命令查看服务的运行状态:
"ps -ef | grep xs-searchd"
[root@localhost ~]# ps -ef | grep xs-searchd
root 2431 1 0 13:25 ? 00:00:00 xs-searchd: master
root 2432 2431 0 13:25 ? 00:00:00 xs-searchd: worker[1]
root 2433 2431 0 13:25 ? 00:00:00 xs-searchd: worker[2]
root 2434 2431 0 13:25 ? 00:00:00 xs-searchd: worker[3]
root 2487 2397 0 13:29 pts/0 00:00:00 grep --color=auto xs-searchd
4). 设置开机启动
建议将
xunsearch添加到开机启动脚本中,以便每次服务器重启后能自动启动搜索服务程序
- 在
Linux系统中,
可以将脚本指令"/usr/local/xunsearch/bin/xs-ctl.sh -b inet start"
写进"/etc/rc.local"文件,然后保存退出即可
vi /etc/rc.local
提示:本机测试,开机重启不成功,这就尴尬了!!!

☞ ThinkPHP5 应用框架的配置
此处,注意,应用框架跟前面的
"XunSearch"服务端不在一个ip地址
1). composer 安装 sdk
官方指导文档 ——
【通过Composer 使用 Xunsearch SDK】
- 进入项目根目录,执行
composer指令如下:
composer require --prefer-dist hightman/xunsearch "*@beta"
- 此时,会在
"vendor"目录下,生成两个相关文件夹
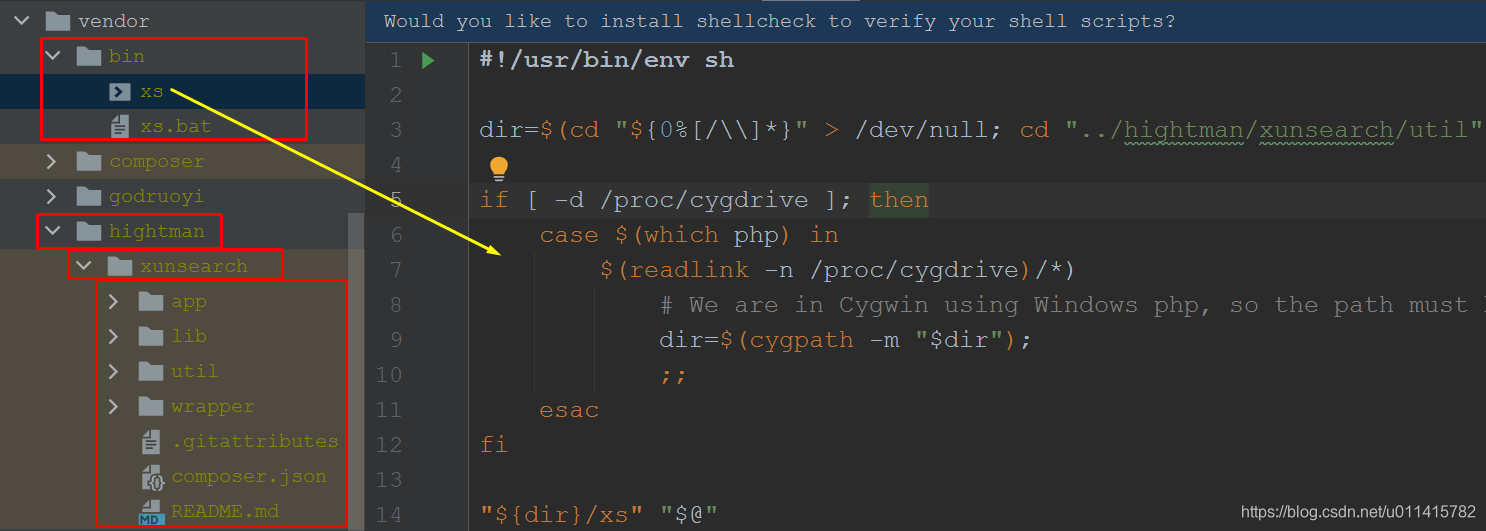
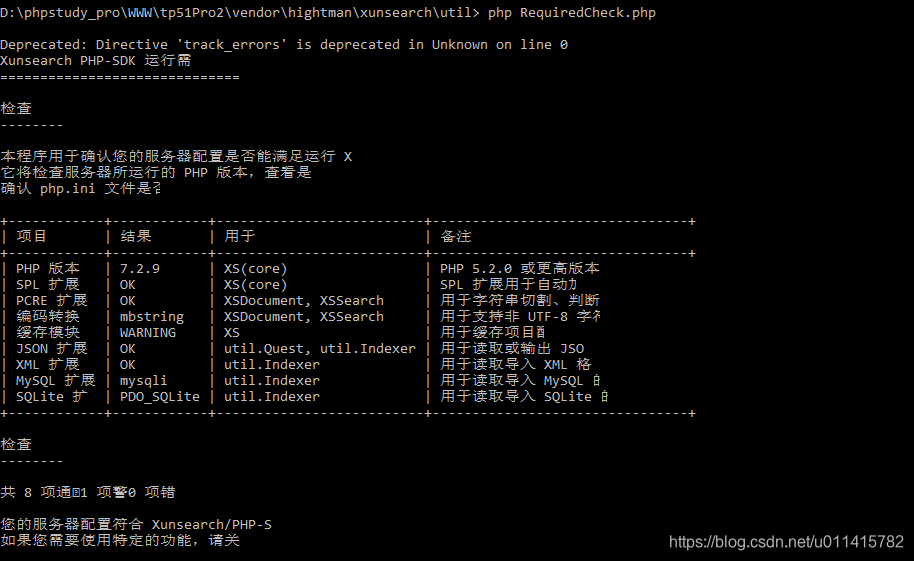
- 检测
PHP-SDK的运行条件
此时,可以在"vendor\hightman\xunsearch\util"目录中
运行 php 指令:php RequiredCheck.php
2). 配置文件的修改
对于配置文件的详细解释,建议阅读文档 ——
【xunsearch 项目配置文件详解】
每个搜索项目必须有且仅有一个
type=id字段,确保每条数据具备唯一值,是索引更新和删除的凭据
- 可以参考
"vendor/hightman/xunsearch/app/demo.ini"文件
创建属于自己业务的配置文件
我新建了一个"goods_sku.ini"文件,配置参考如下:
project.name = goods_sku
project.default_charset = utf-8
server.index = 192.168.80.224:8383
server.search = 192.168.80.224:8384[sku_id]
type = id[spec_name]
type = string
index = both
3). 集成方法类 "XunseachService" 的使用
根据网上的一些经验,建议,创建一个集成方法类
- 此处,提供
"XunsearchService.php"的源码,方便参考使用
<?phpnamespace app\common\lib;
/*** xunsearch 集成使用类* Class XunsearchService* @package app\common\lib*/
class XunsearchService
{/*** 中文分词搜索* @param string $keywords 关键词* @param string $file ini文件名* @param bool $is_scws 是否开启中文分词(例如:口袋新世代,拆分成:口袋、新、世代)* @param int $limit 搜索结果条数* @return array 返回结果* @throws \XSException*/public static function search($keywords,$file = 'demo',$is_scws = false,$limit = 100){$xs = new \XS($file);if($is_scws === true) {//中文分词$tokenizer = new \XSTokenizerScws;//词语拆分$words = $tokenizer->getTokens($keywords);$where = '';//拼接成查询条件(OR)foreach ($words as $key => $val) {if ($key == 0) {$where = $val;} else {$where .= ' OR ' . $val;}}}else {$where = $keywords;}$search = $xs->search;$result = $xs->search->setQuery($where)//->setSort('sku_id','asc') #按索引排序->setDocOrder(true) #按添加索引排序(升序)->setLimit($limit)->search();$search->close();return $result;}/*** 新增/更新/删除 xunsearch 数据库* @param array $data* @param string $file ini文件名* @param string $tag 'add':新增;'update':更新;'[主键ID]':删除* @return bool*/public function save($data,$file = 'demo',$tag = 'add'){try {$xs = new \XS($file);#创建文档对象$doc = new \XSDocument;$doc->setFields($data);#更新(新增)数据$index = $xs->index;if ($tag == 'add'){$index->add($doc);}elseif ($tag == 'update'){$index->update($doc);}else{// 此处,传来的是作为主键的值$index->del($tag);}#强制刷新当前索引列表数据return $index->flushIndex();}catch (\Exception $e){return false;}}
}
新建类名可自定义,基本没啥疑问
4). 增加索引的操作
- 在商品
SKU数据操作变化的业务逻辑位置,添加如下代码:
(注意传参的不同,此处只是演示了增加的操作)
$xs_data = ['sku_id' => $sku_ID,'spec_name' => $spec_name];
$xsService = new XunsearchService();
$xsService::save($xs_data,'goods_sku');
提示
- 如果操作成功,你会在
xunsearch服务端的"data"目录下发现一个"goods_sku"的文件夹
5). 索引查询操作
- 在需要进行查询操作的位置,补充如下代码:
(后续便是根据返回的数组,然后匹配业务数据表的sku_id,进行商品信息的展示了 …)
$xsService = new XunsearchService();
try {$message = $xsService::search('我找原味的瓜子和爆款蓝牙', 'goods_sku', true);} catch (\XSException $e) {$message = $e->getMessage();}var_dump($message);
☞ 附录
①. 代码检索测试
- 首先,我触发
"$xsService->save()"事件,得到了六个数据
然后,在查询操作时,置空"$xsService::search()"的第一个参数可得到如下数据:

- 在此,我设置查询的文字为:
"我找原味的瓜子和爆款蓝牙"
代码处理,得到的查询语句为:"我找 OR 找 OR 原味 OR 的 OR 瓜子 OR 和 OR 和爆 OR 爆款 OR 款 OR 蓝牙"
运行匹配得到的结果集如下:
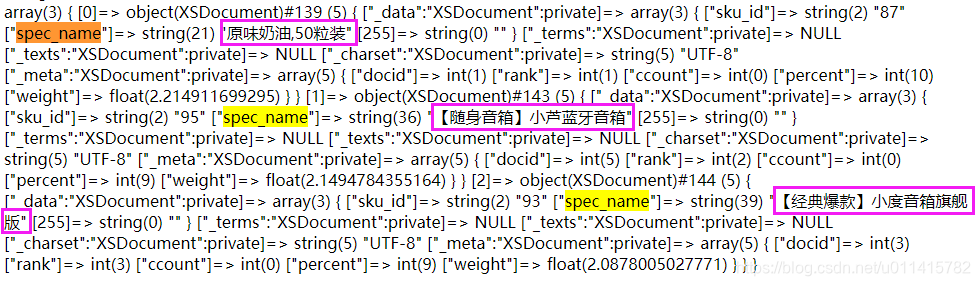
从结果上来看,还是可以接受的
不过,此处可以注意到拆分的名词还是差点意思,可对比参考下 ——
【HanLP 在线演示】
②. 全文检索应用场景
- 首先,再次明确一下 “全文检索” 概念
创建索引,然后查询索引的过程我们称之为全文检索,索引一次创建可以多次使用,这样就不用了每一次都进行文件数据查分,比较快
- 其次便是 “全文检索” 的应用场景
1. 搜索引擎:百度,360,谷歌等等2. 站内搜索:论坛搜索评论,微博搜索热点,新闻网站搜索新闻3. 电商搜索:淘宝,京东
有搜索的地方都可以用到全文检索
- 举一个我们电商项目中的场景
小程序首页提供商品搜索功能设计时,需要满足:有足够商品时就显示商品不够时,也可以展示相关文章那么设计思路如下:1. 在商品添加时,就将 goods_id,goods_name,type=1(标记为商品) 添加到 xunsearch 索引文档中2. 同时,在添加文章时,将 article_id,title,type=2(标记为文章) 也添加到 xunsearch 索引文档中3. 用户在首页输入信息时,触发 search 查询事件4. 在 search 查询事件中,定义按照 type 升序获取前 20 条记录然后,根据数据匹配数据库中的 商品及文章(图片/标题/主键ID)最终,在前端的搜索列表中展示出来满足用户点击后,直接进入对应的详情页面
补充:
- 可以参考百度搜索的结果:将得到的信息,使用正则表达式 高亮显示匹配的词汇
- 注意,对存在索引的更新、删除操作,避免冗余数据的产生
后期根据自己的业务需求进行拓展 …
③. 一点点拙见
提示: 目测官方没有好的精力去升级优化,论坛也没法访问,好多问题找不到探讨 ...
-
忍不住吐槽
学习过程中
网上的例子比较少,遇到问题不好解答
比较失望的是,官方文档说的不清楚,需要多次测试,碰运气的感觉
好歹给个参考实例,演示代码实现过程吧!! -
再给个赞赏
话又说回来
作为开源项目为大家提供便利
本身就是值得赞赏的,太过吹毛求疵就不好了!
希望,同道中人少踩几个坑,共同进步,谢谢 ...
这篇关于ThinkPHP5 使用迅搜 (XunSearch) 实现全文检索实例指导的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




