本文主要是介绍上位机与PLC:ModbusTCP通讯之数据类型转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前请提要:
从PLC读取的数值,不管是读正负整数还是正负浮点数,读取过来后都会变成UInt16,也就是Ushort类型
一、ushort(UInt16)转成 Int32
源代码方法:
//ushort类型转Int32类型的方法private int ushortToInt32(ushort[] date, int start){//先进行判断,长度是否正确if (start < 0 || start + 1 >= dat.Length){throw new Exception($"ushortToInt32索引超范围{start}");}//这里是将数组拆分成4段,然后重新编成一个数组byte[] tmp = new byte[4];byte[] byteH = BitConverter.GetBytes(dat[start + 1]);byte[] byteL = BitConverter.GetBytes(dat[start + 0]);tmp[0] = byteL[0];tmp[1] = byteL[1];tmp[2] = byteH[0];tmp[3] = byteH[1];//这是里byte转成Int32return BitConverter.ToInt32(tmp, 0);}前请提要:Int32是32位,ushort是16位,byte是8位
(1)使用原因
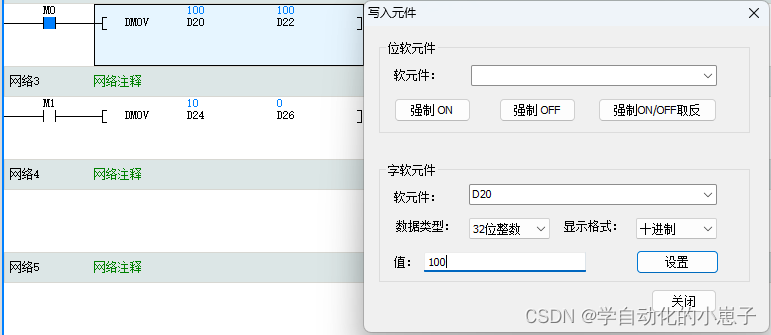
向PLC的地址读取数据,PLC向地址写入32位整数,数值为100,但Modbus传输走的是16位,因此无法直接把数值展示到页面上,所以需要转成32为整数
(2)为何是 ushort 转 Int32
用ReadHoldingRegisters方法接收的值为ushort类型
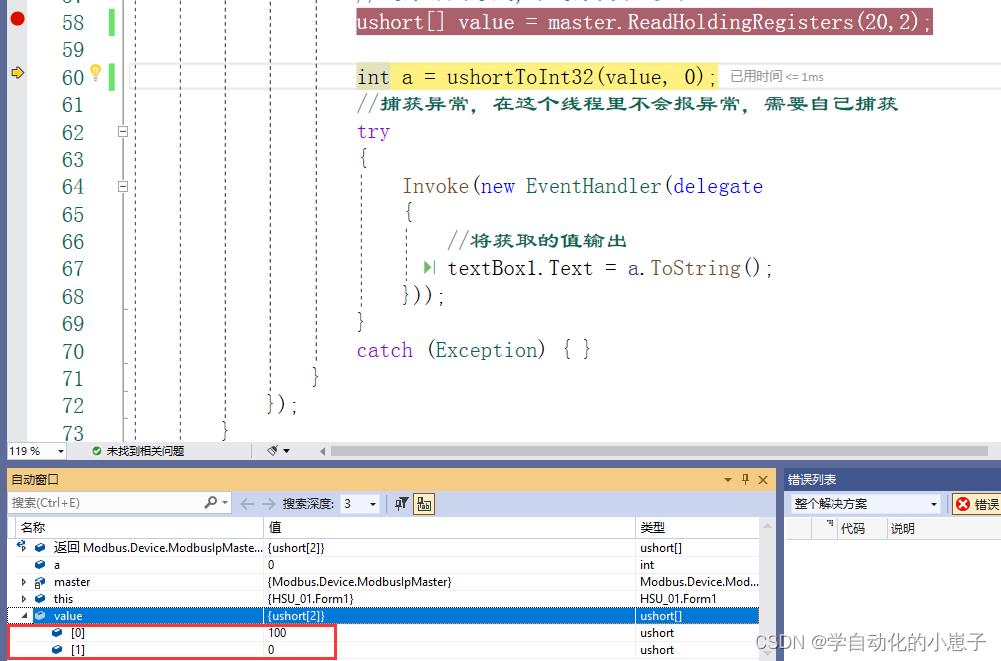
(3)转换方法的思路
先将ushort类型转成byte类型,再将byte类型转成Int32类型
(4)输入参数
前者是所要转换的ushort类型数组,后者是ushort类型数组从第几个数组开始转化(需要注意的是,一次只能转化一个;无法说调用一次方法,将ushort数组转成好几个Int32类型值)
(5)检查所要转换的数组长度
何为所要转换的数组长度,比如ushort数组里只有两个,因此我们只能转 ushort[0] 和 ushort[1],但是int start 写成 1 ,那就是转化 ushort[1] 和 ushort[2] ,而 ushort[2] 根本不存在,因此抛出异常;同理当 ushort 的数组只有一位,根本不满足转化条件,因此也会抛出异常
(6)ushort 数组拆分成 byte 成啥样
| Int32 | 100 | |||
| ushort | ushort[0] = 100 | ushort[1] = 0 | ||
| byte | byte[0] = 100 | |||
这篇关于上位机与PLC:ModbusTCP通讯之数据类型转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







