本文主要是介绍Redis探秘:AOF日志与数据持久性之旅,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


第1章:引言
大家好,我是小黑,咱们今天来聊聊Redis。你知道吗,Redis作为一个超高效的内存数据库,真的是超级给力。它可以秒速处理数据,让咱们的应用运行得飞快。但是,小黑得告诉你,虽然Redis用内存存数据快到飞起,一旦服务器宕机了,咱们的宝贵数据可就泡汤了。想想看,如果你的购物车或者聊天记录,一不小心就全都消失了,那得多伤心啊!
但别担心,Redis早有准备。它用了一种叫做AOF(Append Only File)的日志机制来保护咱们的数据。简单来说,这个机制就像是一个不停记录你每个操作的小秘书,确保就算服务器翻车了,数据可以大部分不丢。咱们下面就详细探讨一下AOF是怎么做到的。
第2章:AOF日志机制的概述
AOF日志,全称是“Append Only File”,就像它的名字那样,它是一个只增不删的文件。每当有新的命令执行,比如你往数据库里加了一条数据,AOF就会把这个命令写进日志文件里。这样,就算Redis崩了,重启后它可以通过这个日志文件,重放那些命令,把数据恢复到宕机前的状态。
这听起来是不是有点像玩游戏时的存档点?没错,AOF就是Redis的存档点,但它更实时、更持久。这样,就算服务器意外关机,咱们的数据也能安然无恐地从最后的操作恢复过来。(但并不是可以完全不丢失数据)
第3章:AOF日志的工作原理
AOF日志,是一种只追加不删除的文件。这个机制会把所有修改数据库状态的命令,一条接一条地写入到一个文件里。想象一下,就好像你在用笔记本记日记,每发生一件事,你就在日记本上写下一行。
这种机制的好处是什么呢?主要是可靠性。即使Redis突然宕机,或者服务器断电,这个AOF文件还在。Redis重启后,它会读这个文件,按照文件里的命令一条一条地执行,这样就把数据恢复到最新的状态了。这个过程就像是在回放一部录像,把所有发生过的事情重新演绎一遍。

现在,小黑用Java和Jedis来展示一下AOF日志是怎么工作的。假设我们有一个简单的任务,比如记录网站的访问次数。看下面的代码:
import redis.clients.jedis.Jedis;public class RedisAOFExample {public static void main(String[] args) {// 连接Redis服务器Jedis jedis = new Jedis("localhost", 6379);// 初始化访问次数为0jedis.set("visitCount", "0");// 模拟网站被访问,增加访问次数for(int i = 0; i < 10; i++) {jedis.incr("visitCount");try {Thread.sleep(1000); // 模拟每秒一次访问} catch (InterruptedException e) {e.printStackTrace();}}// 获取并打印最终的访问次数System.out.println("Total visits: " + jedis.get("visitCount"));// 关闭连接jedis.close();}
}
这段代码模拟了网站的访问,每次访问就把"visitCount"这个键的值加1。如果Redis服务器在这个过程中宕机了,不用担心,因为AOF会记录下每一次对"visitCount"的增加。
在上面的例子中,AOF日志会记录与Redis交互的每一条命令。以小黑的代码为例,AOF日志中的每条记录会是这样的:
- 当设置初始访问次数为0时:
SET visitCount 0 - 在循环中,每一次增加访问次数时:
INCR visitCount
所以,如果咱们的循环运行了10次,AOF日志将包含以下命令:
SET visitCount 0INCR visitCountINCR visitCountINCR visitCountINCR visitCountINCR visitCountINCR visitCountINCR visitCountINCR visitCountINCR visitCountINCR visitCount
每一条命令都代表了一个操作步骤,确保在Redis重启后,可以通过重放这些命令来恢复数据到正确的状态。这就是AOF日志的核心作用,它确保数据的持久性和一致性,即使在面对突发的系统宕机时也不例外。
第4章:AOF日志的写回策略
这些策略决定了Redis是如何把操作命令写入AOF日志的,每种策略都有自己的优缺点,适用于不同的场景。
-
Always策略:
- 这个策略下,每执行一个命令,Redis都会立即将其写入AOF文件,并确保数据写入硬盘。这样做的好处是数据安全性最高,但缺点是因为频繁的磁盘IO操作,可能会影响性能。
-
Everysec策略(默认选项):
- 在这个策略下,Redis会每秒钟把新的操作命令批量写入AOF文件一次。它是一种平衡方案,既保证了数据的相对安全性,又避免了频繁的磁盘写入,性能比Always策略要好。
-
No策略:
- 这个策略下,操作命令的写入取决于操作系统的IO策略。也就是说,Redis不保证立即将命令写入磁盘,这样做提高了性能,但在发生系统故障时,最近的数据可能会丢失。
接下来,小黑用Java代码来展示如何在Jedis中设置这些策略。注意,这里的设置通常是在Redis服务器配置文件中进行,而不是在客户端代码中。但为了演示,小黑这里用一些模拟代码。
import redis.clients.jedis.Jedis;public class RedisAOFConfig {public static void main(String[] args) {// 连接Redis服务器Jedis jedis = new Jedis("localhost", 6379);// 设置AOF策略为alwaysjedis.configSet("appendfsync", "always");// 设置AOF策略为everysecjedis.configSet("appendfsync", "everysec");// 设置AOF策略为nojedis.configSet("appendfsync", "no");// 关闭连接jedis.close();}
}
这段代码展示了如何用Jedis库来设置Redis的AOF策略。当然,这只是一个示例,实际上,你需要根据你的应用需求和服务器性能来选择合适的策略。每个策略都有其适用的场景,没有绝对的好坏,关键在于找到平衡点。
通过不同的策略,咱们可以在数据安全性和系统性能之间找到一个合适的平衡。这就是Redis作为一个高效且可靠的内存数据库的魅力所在。
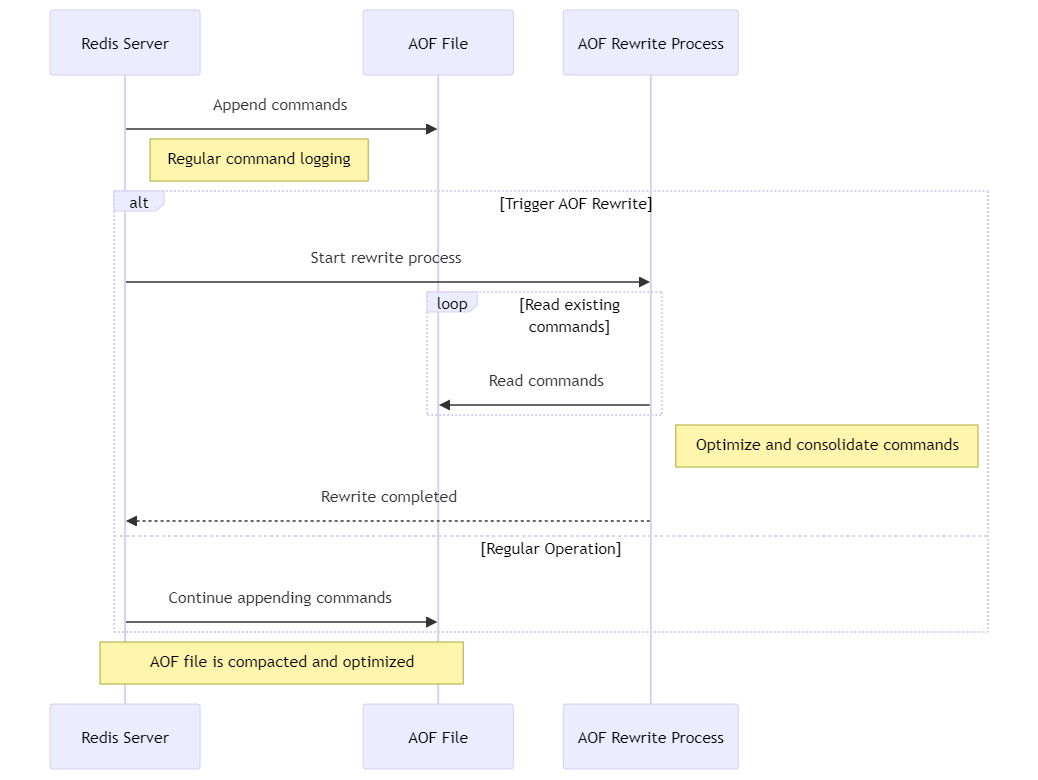
第5章:AOF重写机制
这个机制非常关键,它可以帮助减少AOF日志的大小,优化Redis的性能。
随着时间的推移,AOF文件可能会变得非常大,因为它记录了所有的写操作。但很多旧的记录可能已经不再必要了,比如一个变量被反复修改多次,我们只关心最终的值。这时候,AOF重写就派上用场了。它会创建一个新的AOF文件,只包含当前数据库状态所必需的最少命令集。这样就大大减少了文件的大小,提高了Redis的效率。
这个过程是怎样的呢?Redis会启动一个子进程来进行AOF重写。子进程会读取当前数据库的快照,然后根据这个快照生成新的、更紧凑的AOF文件。这个过程是非阻塞的,不会干扰主进程的正常工作,所以不会影响Redis的性能。
第6章:总结
经过之前的章节,咱们对Redis中的AOF日志机制有了深入的了解。从AOF的基本概念、工作原理,到不同的写回策略,再到AOF重写机制,小黑希望这些内容能帮助大家更好地理解AOF日志在Redis中的重要性。
AOF日志是Redis数据持久化的关键组件,它通过记录每一个修改数据库状态的操作,确保了数据的安全和一致性。不同的写回策略(Always、Everysec和No)让我们可以在数据安全性和性能之间找到平衡。同时,AOF重写机制帮助减小日志文件的大小,进一步提升了Redis的性能。
AOF日志是Redis作为一个高效、可靠的内存数据库系统的重要特性。它不仅保证了数据的基础安全性,也提高了系统的整体性能,尤其是重启后快速恢复缓存数据。通过合理地配置和使用AOF日志,我们可以确保即使在面对不可预测的系统宕机时,数据也能得到基本有效的保护。
这篇关于Redis探秘:AOF日志与数据持久性之旅的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



