本文主要是介绍《python每天一小段》--12 数据可视化《1》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎阅读《Python每天一小段》系列!在本篇中,将使用Python Matplotlib实现数据可视化的简单图形。
文章目录
- 一、概念
- (1)安装matplotlib
- (2)数据可视化实现步骤
- 二、绘制简单的折线图
- (1)简单的图表
- (2)修改标签文字和线条粗细
- (3)校正图形
- (4)绘制单个点
- (5)绘制一系列点
- (6)自动计算
- (7)删除数据点的轮廓
- (8)修改颜色
- (9)自定义颜色
- (10)颜色映射
- (11)自动保存
- (12)绘制前 5 个整数的立方值
一、概念
Matplotlib是一个流行的Python数据可视化库,它提供了丰富的绘图功能,可以创建各种类型的图表,包括折线图、散点图、柱状图、饼图等。
要查看使用matplotlib可制作的各种图表,可访问http://matplotlib.org/
(1)安装matplotlib
pip install matplotlib
(2)数据可视化实现步骤
下面是对Matplotlib的详细解释以及如何实现数据可视化的一般步骤:
-
导入Matplotlib库:
在Python脚本中,首先需要导入Matplotlib库。通常使用以下语句导入Matplotlib的pyplot模块:import matplotlib.pyplot as plt -
创建图表:
在开始绘图之前,需要创建一个图表对象。可以使用plt.figure()函数创建一个新的图表。plt.figure() -
绘制图表:
使用Matplotlib的各种绘图函数来绘制所需的图表。例如,使用plt.plot()函数绘制折线图,使用plt.scatter()函数绘制散点图,使用plt.bar()函数绘制柱状图等。x = [1, 2, 3, 4, 5] y = [10, 8, 6, 4, 2] plt.plot(x, y) -
添加标签和标题:
可以使用plt.xlabel()、plt.ylabel()和plt.title()函数为图表添加轴标签和标题。plt.xlabel('X轴') plt.ylabel('Y轴') plt.title('折线图') -
自定义图表样式:
可以使用各种Matplotlib函数来自定义图表的样式,如设置线条颜色、线型、标记样式、图例等。plt.plot(x, y, color='red', linestyle='--', marker='o', label='数据') plt.legend() -
显示图表:
使用plt.show()函数显示图表。plt.show()
以上是一个简单的数据可视化的流程。当然,Matplotlib还提供了许多其他功能,如子图、网格、颜色映射等,可以根据需要进行使用和定制。
除了Matplotlib,还有其他一些数据可视化工具可以使用,如Seaborn、Plotly、Bokeh等。每个工具都有其特点和适用场景,可以根据具体需求选择合适的工具来实现数据可视化。
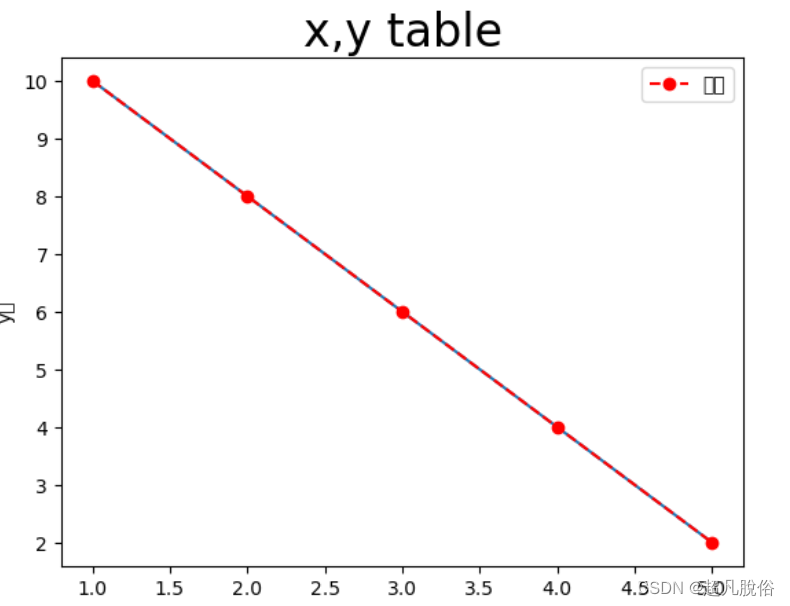
python代码:
import matplotlib.pyplot as pltplt.figure()
x = [1,2,3,4,5]
y = [10,8,6,4,2]
plt.plot(x,y)
#plt.scatter(x,y)
#plt.bar(x,y)plt.title("x,y table",fontsize=24)
plt.xlabel('x轴')
plt.ylabel('y轴')plt.plot(x,y,color='red',linestyle='--',marker='o',label='数据')
plt.legend()plt.show()
生成图表:
二、绘制简单的折线图
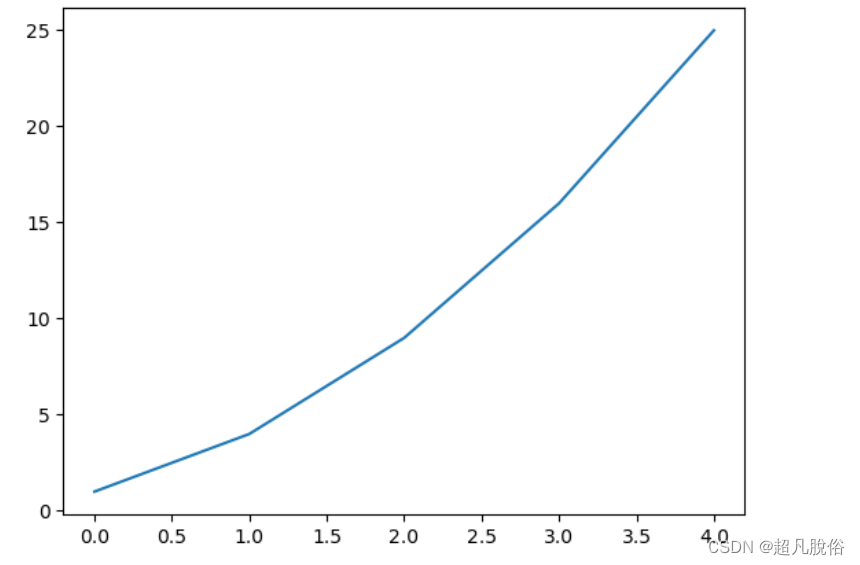
(1)简单的图表
1、首先导入了模块pyplot,并给它指定了别名plt,以免反复输入pyplot
2、创建了一个列表,在其中存储了前述平方数,再将这个列表传递给函数plot(),这个函数尝试根据这些数字绘制出有意义的图形。
3、plt.show()打开matplotlib查看器,并显示绘制的图形
import matplotlib.pyplot as pltsquares = [1,4,9,16,25]
plt.plot(squares)
plt.show()
图表:
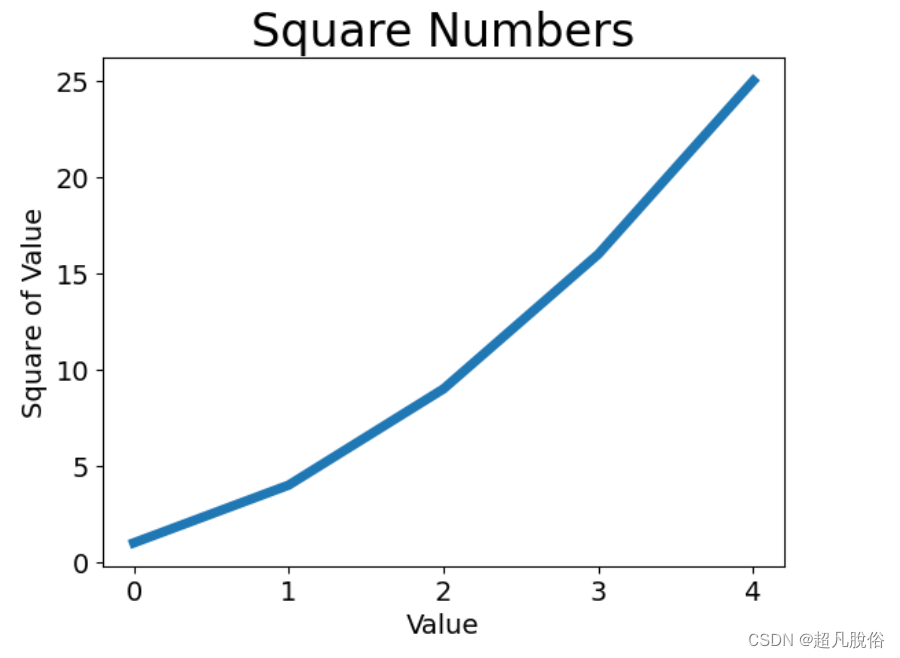
(2)修改标签文字和线条粗细
import matplotlib.pyplot as pltsquares = [1,4,9,16,25]
plt.plot(squares,linewidth=5)#设置图标标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value",fontsize=14)
plt.ylabel("Square of Value",fontsize=14)#设置刻度标记的大小
plt.tick_params(axis='both',labelsize=14)
plt.show()
图标:
(3)校正图形
import matplotlib.pyplot as pltinput_values = [1,2,3,4,5]
squares = [1,4,9,16,25]
plt.plot(input_values,squares,linewidth=5)#设置图标标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value",fontsize=14)
plt.ylabel("Square of Value",fontsize=14)#设置刻度标记的大小
plt.tick_params(axis='both',labelsize=14)
plt.show()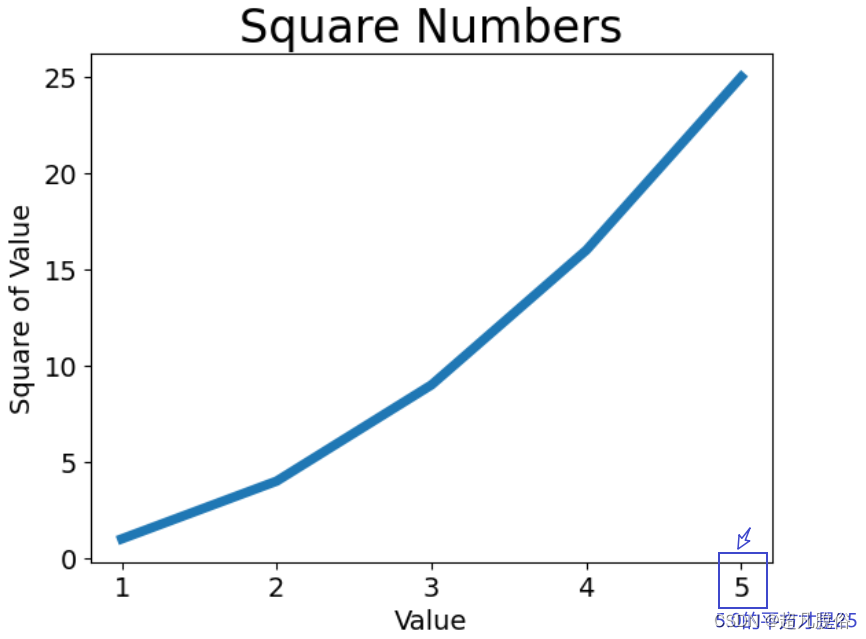
(4)绘制单个点
使用scatter()绘制散点图并设置其样式
import matplotlib.pyplot as pltplt.scatter(2,4)
plt.show()

添加标题,给轴加标签
import matplotlib.pyplot as pltplt.scatter(2,4)plt.scatter(2,4,s=200)plt.title("Square Number",fontsize=24)
plt.xlabel("Value",fontsize=14)
plt.ylabel("Square of Value" ,fontsize=14)#设置刻度标记的大小
plt.tick_params(axis='both',which='major',labelsize=14)plt.show
图表:
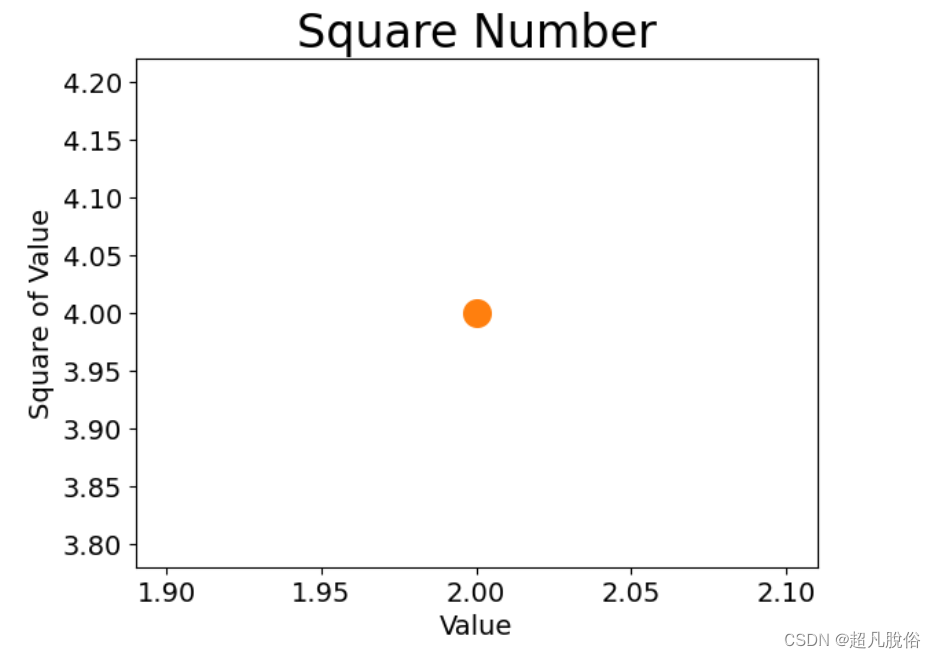
(5)绘制一系列点
要绘制一系列的点,可向scatter()传递两个分别包含x值和y值的列表:
import matplotlib.pyplot as pltx_values = [1,2,3,4,5]
y_values = [1,4,9,16,25]plt.scatter(x_values,y_values,s=100)#设置图标标题及坐标轴指定标签plt.title("Square Number",fontsize=24)
plt.title("Value",fontsize=14)
plt.title("Square of Value",fontsize=14)#设置刻度标记大小
plt.tick_params(axis='both',which='major',labelsize=14)
plt.show()
图表:
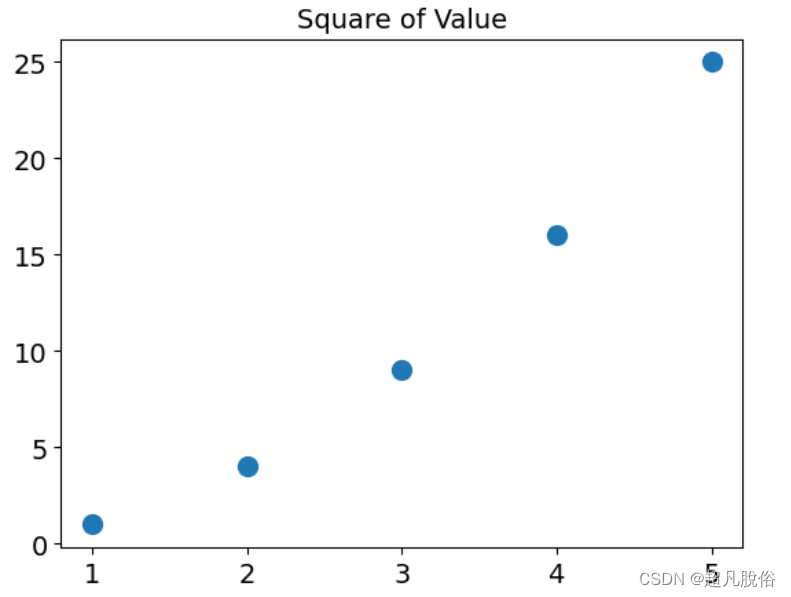
(6)自动计算
手工计算列表要包含的值可能效率低下,需要绘制的点很多时尤其如此。可以不必手工计算
包含点坐标的列表,而让Python循环来替我们完成这种计算。下面是绘制1000个点的代码:
import matplotlib.pyplot as pltx_values = list(range(1,1001))
y_values = [x**2 for x in x_values]plt.scatter(x_values,y_values,s=40)#设置图标并给坐标轴加上标签
plt.title("Square Number",fontsize=24)
plt.title("Value",fontsize=14)
plt.title("Square of Value",fontsize=14)#设置刻度标记大小
plt.tick_params(axis='both',which='major',labelsize=14)#设置每个坐标轴的取值范围
plt.axis([0,1100,0,1100000])plt.show()
图表:

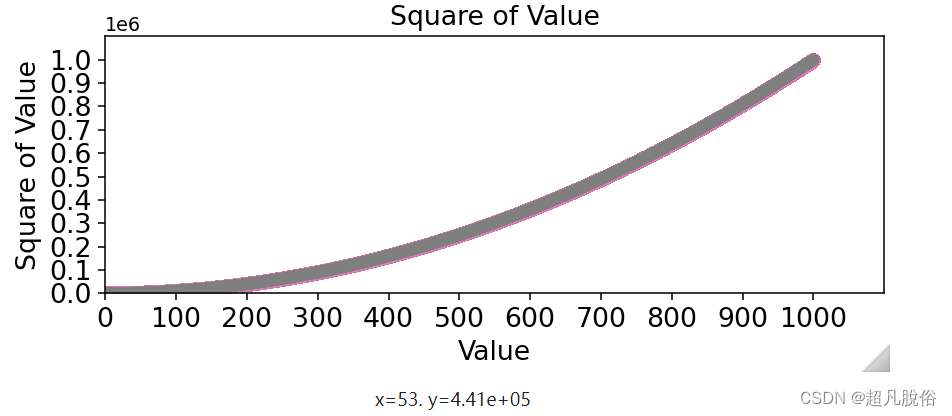
(7)删除数据点的轮廓
matplotlib允许你给散点图中的各个点指定颜色。默认为蓝色点和黑色轮廓,在散点图包含的数据点不多时效果很好。但绘制很多点时,黑色轮廓可能会粘连在一起。
要删除数据点的轮廓,可在调用scatter()时传递实参:edgecolor='none'
plt.scatter(x_values,y_values,edgecolor='none',s=40)
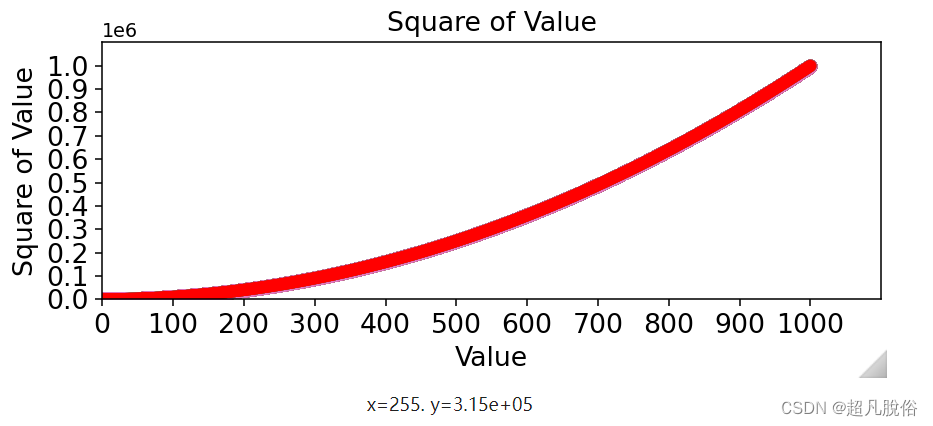
(8)修改颜色
修改数据点的颜色,可向scatter()传递参数c,并将其设置为要使用的颜色的名称
plt.scatter(x_values,y_values,c='red',edgecolor='none',s=40)
图表:
(9)自定义颜色
使用RGB颜色模式自定义颜色。要指定自定义颜色,可传递参数c,并将其设置为一个元组,其中包含三个0~1之间的小数值,它们分别表示红色、绿色和蓝色分量。
plt.scatter(x_values,y_values,c=(0,0,0.8),edgecolor='none',s=40)
图表:
创建一个由淡蓝色点组成的散点图:

值越接近0,指定的颜色越深,值越接近1,指定的颜色越浅
(10)颜色映射
颜色映射(colormap)是一系列颜色,它们从起始颜色渐变到结束颜色。在可视化中,颜色映射用于突出数据的规律,例如,你可能用较浅的颜色来显示较小的值,并使用较深的颜色来显示较大的值。
模块pyplot内置了一组颜色映射。要使用这些颜色映射,你需要告诉pyplot该如何设置数据集中每个点的颜色。下面演示了如何根据每个点的y值来设置其颜色:
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,edgecolor='none',s=40)
图表:
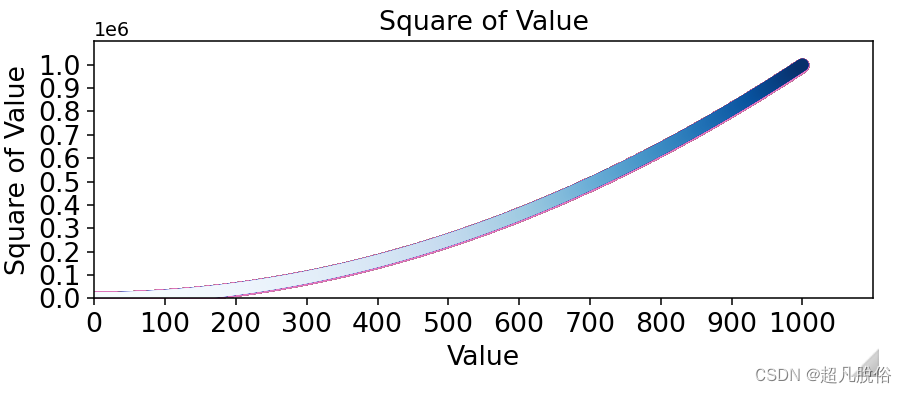
将参数c设置成了一个y值列表,并使用参数cmap告诉pyplot使用哪个颜色映射,代码将y值较小的点显示为浅蓝色,并将y值较大的点显示为深蓝色。
要了解pyplot中所有的颜色映射,请访问http://matplotlib.org/,单击Examples,向下滚动到Color Examples,再单击colormaps_reference。
(11)自动保存
要让程序自动将图表保存到文件中,可将对plt.show()的调用替换为对plt.savefig()的调用
plt.savefig("squares.plot.png",bbox_inches='tight')
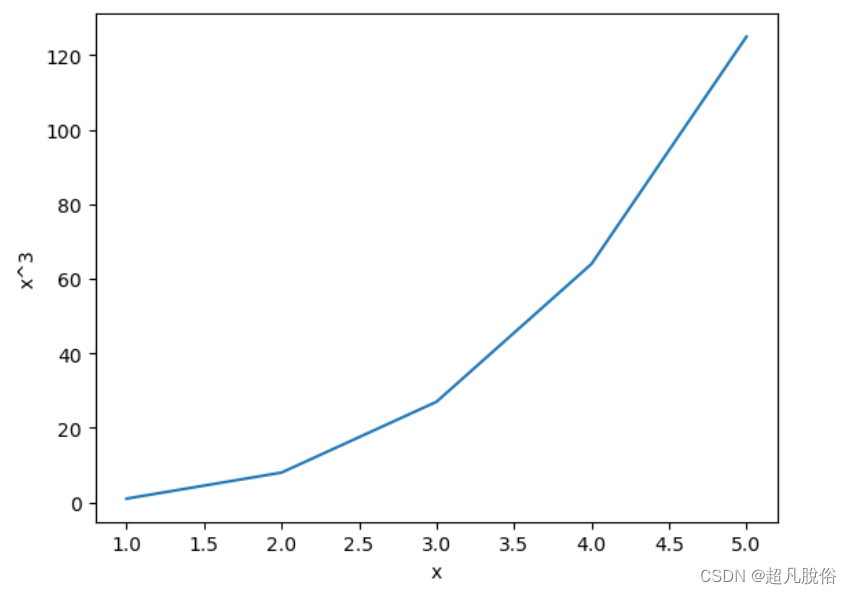
(12)绘制前 5 个整数的立方值
import matplotlib.pyplot as plt#绘制前5个整数的立方值
x = [1,2,3,4,5]
y = [x[i] ** 3 for i in range(len(x))]plt.plot(x,y)
plt.xlabel("x")
plt.ylabel("x^3")
plt.show()
参考引用《Python从入门到实践》
这篇关于《python每天一小段》--12 数据可视化《1》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




