本文主要是介绍Flink1.12-之JobManagerTaskManager内存管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink1.12-之内存管理
1、前言
flink为了让用户更好的调整内存分配,达到资源的合理分配,在Fllink1.10引入了TaskManager的内存管理,后续在Flink1.11版本引入了JobManager的内存管理,用户可以通过配置的方式合理的分配资源。
不管是TaskManager还是JobManager都是单独的JVM进程,他们共用一套内存模型抽象(TaskManager的内存模型更加复杂),如下。

该模型由heap和off-heap内存组成,这里有以下3种调整内存的方式,3种方式必须选一种,不然会启动失败,最好不要同时指定2种方式,否则有可能会产生配置冲突。
| for TaskManager: | for JobManager: |
|---|---|
taskmanager.memory.flink.size | jobmanager.memory.flink.size |
taskmanager.memory.process.size | jobmanager.memory.process.size |
taskmanager.memory.task.heap.size and taskmanager.memory.managed.size | jobmanager.memory.heap.size |
-
直接调整
jobmanager.memory.process.size或者taskmanager.memory.process.size的方式- 该方式是最简单的方式,该配置下的所有的组件的内存分配都会有默认值,或者通过推导得到,通常在yarn或者k8s、mesos的时候这样指定,container部署通过该参数的配置来申请容器的大小。
-
直接调整
jobmanager.memory.flink.size或者taskmanager.memory.flink.size的方式- 这种方式通常在standalone的时候使用的比较多,其它组件的
-
第三种是直接配置heap和off-heap组件的大小,达到更细粒度的控制,或者配合前2种方式中的其中之一使用也是可以的。
以上三种方式任选一种~!!
2、JobManager内存分配
JobManager的内存模型如下.

以上total process size的模型图可以分为以下的4个内存组件,如果在分配内存的时候,显示的指定了组件其中的1个或者多个,那么JVM overhead的值就是在其它组件确定的情况下,用total process size - 其它 获取的值,必须在min~max之间,如果没有指定组件的值,那么就按照0.1的fraction进行计算得到,如果计算出的值小于min取min,如果大于max取max,如果min、max指定的相等,那么这个JVM overhead就是一个确定的值!
| 内存组件 | 配置选项 | 内存组件的功能 |
|---|---|---|
| JVM Heap | jobmanager.memory.heap.size | 这个大小取决于提交的作业个数和作业的结构以及用户代码的要求。=>>>> 主要用来运行flink框架,执行作业提交时的用户代码以及checkpoint的回调代码 |
| Off-heap Memory | jobmanager.memory.off-heap.size(默认128M) | JM的对外内存的大小. 涵盖了所有direct和native的内存分配。=>>>>用来执行akka等外部依赖,同时也负责运行checkpoint回调及作业提交时的用户代码 |
| JVM metaspace | jobmanager.memory.jvm-metaspace.size(默认256M) | JM的元空间大小,有默认值jobmanager.memory.jvm-metaspace.size = 256M, 属于native memory |
| JVM Overhead | jobmanager.memory.jvm-overhead.min (192M)jobmanager.memory.jvm-overhead.max (1G)jobmanager.memory.jvm-overhead.fraction(0.1) | 为thread stacks, code cache, garbage collection space预留的native memory,有默认的faction of total process size,但是必须在其min & max之间 |
2.1、分配 total process size
jobmanager.memory.process.size

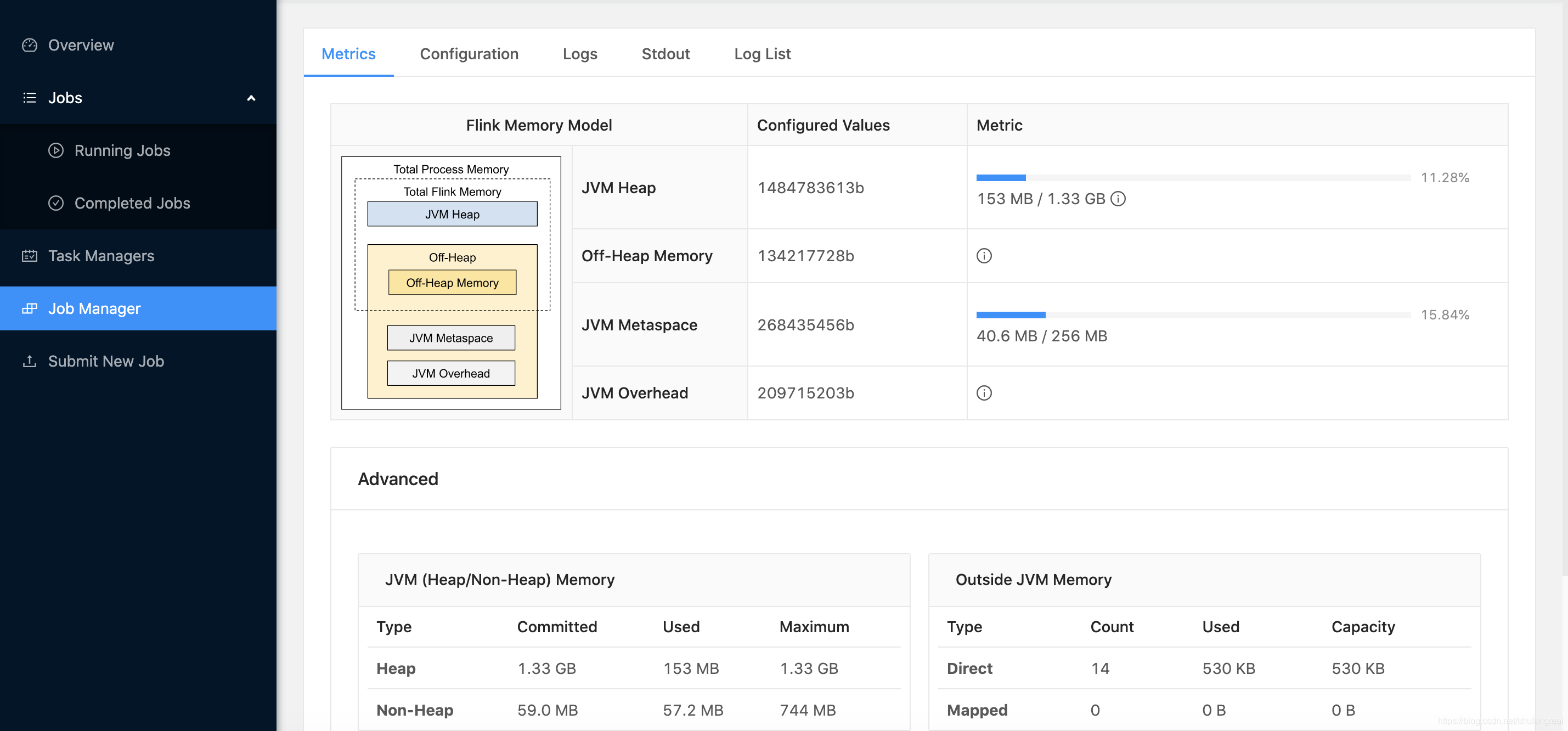
# 此时我们只显示指定了 jobmanager.memory.process.size 的值,没有指定其它组件,此时整个JobManager的JVM进程能占用的内存为2000M
0、total process size = 2000M(这是分配的基准值)
1、JVM overhead 因为没有指定其它组件内存,所以被按照0.1的fraction推断成 => 2000M * 0.1 * 1024 * 1024 = 209715203B(200M)
2、JVM Metaspace 默认值为 256M
3、Off-Heap Memeory 默认为 128M
4、JVM Heap最终被推断为 2000M - 200M - 256M - 128M = 1.38G(?????????????)
√ 为啥JVM Heap只有1.33GB而不是1.38GB呢?

其实这个取决于你使用的GC算法会占用其中很小一部分固定内存作为Non-heap,该占用部分大小为:1.38-1.33 = 0.05GB。
2.2、分配 total flink size
jobmanager.memory.flink.size



# 此时我们只显示指定了 jobmanager.memory.flink.size 的值,也没有指定其它组件如heap size,此时整个JobManager的JVM进程除了JVM Overhead及JVM Metaspace之外能占用的内存为2000M
0、total flink size = 2000M = 1.95G(这属于total process size的组件之一,overhead只能最后按剩余的内存来被推断)
1、JVM Metaspace 默认值为 256M(固定默认值)
2、Off-Heap Memeory 默认值为 128M(固定默认值)
3、JVM heap = 2000M - 128M = 1.828GB - 80MB(GC算法占用) = 1.75GB
4、根据JVM overhead = (JVM overhead + 256M(Metaspace) + 2000(flink size)) * 0.1
=> total process size = 2.448GB
=> JVM overhead = 2.448GB * 0.1 = 262843055B = 250.667MB(在192M~1GB),为有效
5、最终资源的分配如以上日志所示~~
2.3、单独分配 heap size



# 此时我们只显示指定了 jobmanager.memory.heap.size 的值,相当于显示配置了组件的值,此时整个JobManager的JVM Heap被指定为最大内存为1000M
0、Jvm heap被指定为 1000M,但是得从GC算法中扣除 41MB(GC算法占用) => JVM heap(实际) = 959MB
1、JVM Metaspace 默认值为 256M
2、Off-Heap Memeory 默认值为 128M
3、flink total size = 1128MB = 1.102GB
4、(1128MB + 256M + JVM overhead)* 0.1 = JVM overhead => JVM = 153.778 < 192MB(默认的min) => JVM overhead = 192MB
5、total process size = 1128MB + 256M + JVM overhead = 1576MB = 1.5390625GB = 1.539GB
2.4、分配process size和 heap size



# 由于指定了heap.size内存组件的的大小,那么JVM overhead就是取剩余的total process size的内存空间
0、total process size = 2000MB && JVM heap = 1000MB,实际只有959MB,因为减去了41MB的GC算法占用空间
1、JVM Metaspace 默认值为 256M
2、Off-Heap Memeory 默认值为 128M
3、total flink size = 1000MB + 128MB = 1128MB
4、JVM overhead = 2000MB - 1128MB - 256MB = 616MB
2.5、分配flink size和 heap size



# 由于指定了head.size组件的大小,那么overhead就按照剩余total process size的内存空间分配
0、total flink size = 2000MB && JVM heap = 1000MB,实际959MB,减去了GC算法的占用空间
1、JVM off-heap = 2000MB - 1000MB = 1000MB
2、JVM Metaspace = 256MB
3、首先根据JVM overhead = (JVM overhead + 256M(Metaspace) + 2000(flink size)) * 0.1
=> total process size = 2.448GB
=> JVM overhead = 2.448GB * 0.1 = 262843055B = 250.667MB(在192M~1GB),为有效
4、最终确定 total process size = 2.448GB && JVM overhead = 250.667MB
3、TaskManager的内存分配
TaskManager是计算用户任务的节点,他比JobManager的模型更加复杂和精细,合理的分配内存可以使应用更加稳定,TaskManager的细粒度内存模型如下。

其中包含的组件如下表
| 组件 | 配置选项 | 描述 |
|---|---|---|
| Framework Heap Memory | taskmanager.memory.framework.heap.size(默认128M) | 专用于运行Flink框架,通常不用修改该值,它可能与特定的部署环境或作业结构有关,例如高并行度. |
| Task Heap Memory | taskmanager.memory.task.heap.size | 专用于用户提交作业划分的Tasks |
| Managed memory | taskmanager.memory.managed.size taskmanager.memory.managed.fraction(默认0.4) | 这是一块被Flink管理的堆外内存,属于Native Memory, 用于批处理作业的排序,hash运算,缓存中间结果,以及RocksDB状态后端的元数据 |
| Framework Off-heap Memory | taskmanager.memory.framework.off-heap.size(默认128M) | 专用于运行Flink框架,通常不用修改该值,它可能与特定的部署环境或作业结构有关,例如高并行度. |
| Task Off-heap Memory | taskmanager.memory.task.off-heap.size(默认0Byte) | 专用于用户提交作业划分的Tasks,不受GC的影响 |
| Network Memory | taskmanager.memory.network.min (默认64MB)taskmanager.memory.network.max (默认1GB)taskmanager.memory.network.fraction(默认0.1) | 为Task之间的数据交换预留的内存,比如说网络缓冲区,默认是total flink size的0.1,通常不需要去调整这个值 |
| JVM metaspace | taskmanager.memory.jvm-metaspace.size(默认256M) | JM的元空间大小,有默认值256M, 属于native memory |
| JVM Overhead | taskmanager.memory.jvm-overhead.min (192MB)taskmanager.memory.jvm-overhead.max (1GB)taskmanager.memory.jvm-overhead.fraction(0.1) | 为thread stacks, code cache, garbage collection space预留的native memory,有默认的faction of total process size,但是必须在其min & max之间 |
3.1、单独分配total process size
# 单独分配total process size,其它的组件都会自动分配
taskmanager.memory.process.size: 2000m


# 内存分配步骤如下
# 1
1、首先 total process size = 2000M
# 2 native memory = 【456M】
2、因为没有显示分配组件中的任何参数,所以 JVM overhead = 200M
3、JVM MetaSpace = 默认256M
# 3
4、total flink size = 2000M - 200M - 256M = 1544MB = 1.508GB# 4 total direct memory = 154.4M + 0 + 128M = 【282.4M】
5、network memory = 1544 * 0.1 = 154.4M
6、Task offheap = 默认0MB
7、FrameWork Off-heap = 默认128M# 5 managed memeory = 【617.6M】
8、Managed Memory = 1544MB * 0.4 = 617.6M# 6 total JVM heap memory = 1544M - 282.4M - 617.6M = 644MB
9、FrameWork Heap = 128M
10、Task Heap = 644M - 128M = 516M# 7 与以上的日志进行对比,完全能对上,okay!!
3.2、单独分配total flink size
# 单独分配 total flink size
taskmanager.memory.flink.size: 2000m

# 假如直接只分配 taskmanager.memory.flink.size: 2000m,没有设计以上表格中的组件# 1 total flink size = 【2000M】
total flink size = 2000M# 2 managed memory
Managed Memory = 2000M * 0.4 = 800M
# 3 total direct memory = 200M + 128M = 328M
NetWork Memory = 2000M * 0.1 = 200M
FrameWork Off-Heap = 128M
Task Off-Heap = 0Byte = 0M
# 4 total off heap = 800M + 328M = 【1128M】# 5 total JVM heap = 【872M】
total jvm heap = 2000M - 800M - 328M = 872M
FrameWork heap = 128M
Task Heap = 872M - 128M = 744M# 6 native memory
JVM MetaSpace = 默认 256M
JVM overhead = (JVM overhead + 256M(Metaspace)+ 2000M(total flink size))* 0.1=> JVM overhead = 250.667M 在[192MB~1GB],生效# 7 total process size
total process size = 2000M + 256 + 250.667 = 2506.667M = 2.448GB
3.3、单独分配 heap size && managed memory
# 单独分配组件JVM heap 和 mamaged memory
taskmanager.memory.task.heap.size: 1000m
taskmanager.memory.managed.size: 1000m

# total JVM heap = 【1128M】 = 【1.102 GB】
FrameWork heap = 128M(默认)
Task Heap = 1000M# total off-heap = 【1378.667M】
# managed memory
Managed Memory = 1000M
# total direct memory = 378.667M
FrameWork off-heap = 128M
Task off-heap = 0M
NetWork = (NetWork + 1128M + 1000M + 128M + 0M ) * 0.1 => NetWork = 250.667MB 处于[64MB ~ 1GB]
=> total direct memory = 128M + 250.667M = 378.667M# total flink size = 【2506.667M】
total flink size = 1128M + 1378.667M = 2506.667M = 2.448GB# native memory
JVM Metaspace = 256M
JVM overhead = (JVM overhead + 1128M + 1000M + 378.667M + 256M)* 0.1 = 306.963M 处于[192M ~ 1GB],生效# total process size = 【3069.63M】= 【2.998G】
total process size = 2506.667M + 256M + 306.963M = 3069.63M = 2.998G
3.4、分配 total process size 和 heap size && managed memory
# 指定total process size,同时显式分配组件JVM heap 和 mamaged memory
taskmanager.memory.process.size: 3000m
taskmanager.memory.task.heap.size: 1000m
taskmanager.memory.managed.size: 1000m
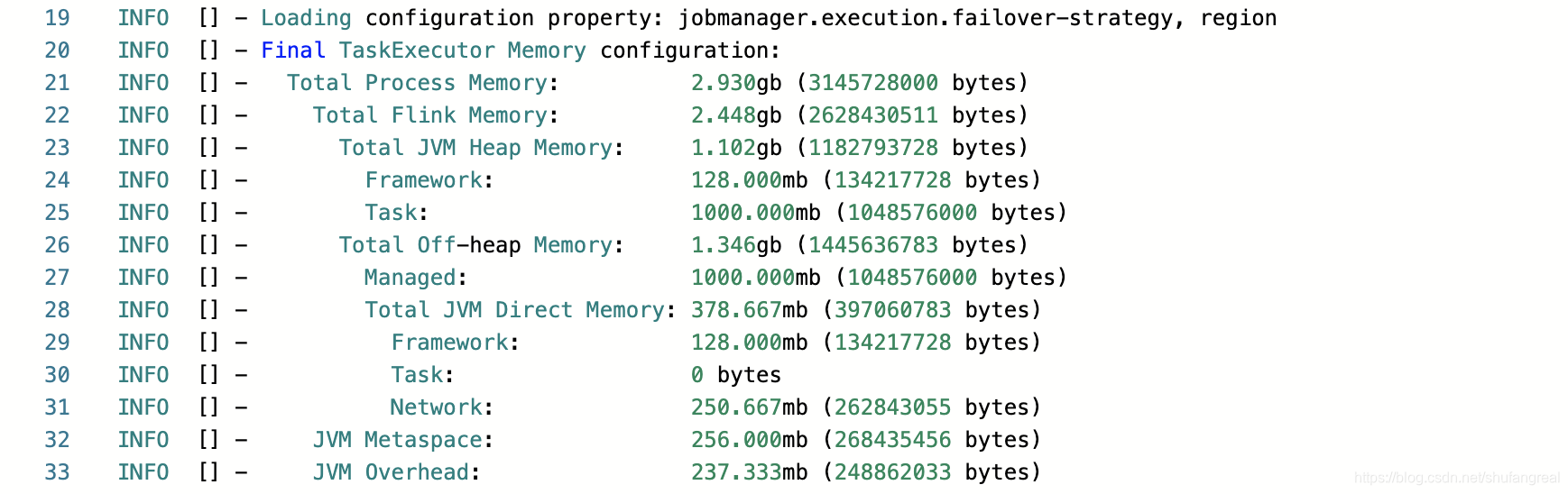
# 1 total process size = 【3000M】# 2 total flink size = 【1128M + 1378.667M】=【2506.667M】=【2.448GB】# 3 total JVM heap = 【1128M】= 【1.102M】
FrameWork heap = 128M
Task heap = 1000M # 4 total off-heap = 【1000M + 128M + 250.667M】= 【1378.667M】 = 【1.346GB】
# managed memory
managed memory = 1000M
# direct memory
FrameWork off-heap = 128M
Task off-heap = 0M
NetWork memory = (NetWork memory + 1128M + 1128M) * 0.1 = 250.667M 在[64M ~ 1GB]之间,满足要求# native memory
JVM Metaspace = 256M
JVM overhead = 3000M - 2506.667M - 256M = 237.333M 在[192M ~ 1GB]之间,满足要求
3.5、分配 total flink size 和 heap size && managed memory
# 指定total flink size,同时显式分配组件JVM heap 和 mamaged memory
taskmanager.memory.flink.size: 3000m
taskmanager.memory.task.heap.size: 1000m
taskmanager.memory.managed.size: 1000m

# 1 已知
total flink size = 3000M = 2.93GB
managed memory = 1000M
Task heap = 1000M# total JVM heap = 【1128M】
Task heap = 1000M
Frame heap = 128M# total off-heap = 【3000M - 1128M】 = 【1872M】 = 【1.828GB】
# managed memory = 1000M
# direct memory = 1872M - 1000M = 872M
Task off-heap = 0M
Frame off-heap = 128M
network memory = 872M - 128M = 744M # native memory
JVM Metaspace = 256M
JVM overhead = (JVM overhead + 3000M + 256M) * 0.1 = 361.778M 处于[min192M ~ max1G]之间 符合条件# total process size = 【3617.778M】= 【3.533GB】
3000M + 256M + 361.778M. = 3617.778M = 3.533GB
4、内存分配汇总
在Flink的集群内存分配的过程中,我们大致可以通过3种方式进行分配
-
指定 total process size || total flink size 取决于你用什么方式部署
-
单独指定某个组件比如Task-heap的大小,其它的组件都会被推导出来
-
指定 total size && heap or off-heap其中之一,其它的组件通过默认值进行填充或者进推导
-
如total flink size = total heap size + total off-heap size
-
total heap size = task heap + frame heap
-
total off-heap = task off-heap + frame off-heap + network memory
-
network = 0.1* total flink size(没有指定其它组件情况下)
-
JVM overhead = 0.1 * total process size (没有指定其它组件情况下)
-
…其它
-
这篇关于Flink1.12-之JobManagerTaskManager内存管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








