flink1.12专题

Flink1.12集成Hive打造自己的批流一体数仓
简介 小编在去年之前分享过参与的实时数据平台的建设,关于实时数仓也进行过分享。客观的说,我们当时做不到批流一体,小编当时的方案是将实时消息数据每隔15分钟文件同步到离线数据平台,然后用同一套SQL代码进行离线入库操作。 但是随着 Flink1.12版本的发布,Flink使用HiveCatalog可以通过批或者流的方式来处理Hive中的表。这就意味着Flink既可以作为Hive的一个批处
正面超越Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用(下)
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 我们书接上文,我们在之前的文章《正面超越Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用(上)》详细描述了Flink的生产级别Flink on K8s高可用方案和DataStream API 对批执行模式的支持。 接下来是另外的几个特性增强。 第三个,Flink对SQL操作的全面支持 再很早之前,我在浏览社

尝鲜!Flink1.12.2+Hudi0.9.0集成开发
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 Hudi社区最近发生了一些有趣的变化,Hudi集成Flink的方案也已经发布,我个人在官网根据文档试验了一把,整体感觉还不错。我们目前并没有在生产环境中使用,但是随着社区发展和功能越来越完善,相信会有更多的业务开始尝试使用Hudi。本文在此做一个Flink和Hudi集成的分享,作者明喆sama。 一、组件下载 1.1、Flink1.
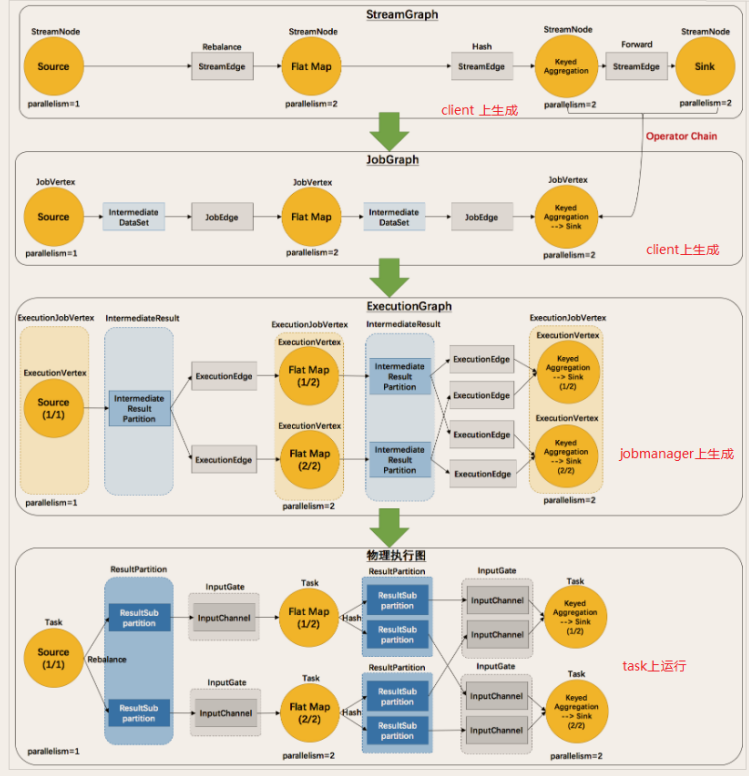
flink1.12.0学习笔记(一)-部署与入门
flink1.12.0学习笔记(1)-部署与入门 1-1-Flink概述 Flink诞生 Flink 诞生于欧洲的一个大数据研究项目 StratoSphere。该项目是柏林工业大学的一个研究性项目。早期, Flink 是做 Batch 计算的,但在 2014 年, StratoSphere 里面的核心成员孵化出 Flink,同年将 Flink 捐赠 Apache,并在后来成为 Apache
Flink1.12 native kubernetes 演进之路
点击上方 "zhisheng"关注, 星标或置顶一起成长 Flink 从入门到精通 系列文章 Flink 1.10 Flink 1.10 开始支持将 native kubernetes 作为其资源管理器。在该版本中,你可以使用以下命令在你的 kubernetes 集群中创建一个flink session。 ./bin/kubernetes-session.sh \-Dkubernetes.clu

Flink1.12-之JobManagerTaskManager内存管理
Flink1.12-之内存管理 1、前言 flink为了让用户更好的调整内存分配,达到资源的合理分配,在Fllink1.10引入了TaskManager的内存管理,后续在Flink1.11版本引入了JobManager的内存管理,用户可以通过配置的方式合理的分配资源。 不管是TaskManager还是JobManager都是单独的JVM进程,他们共用一套内存模型抽象(TaskManag

阿里云安装CDH6.3.2并集成flink1.12
1.购买阿里云服务器,修改配置信息 如果有服务器可以跳过前面购买流程,如果没有服务器只是作为测试练习的话可使用抢占实例的服务器,一天几块钱(按小时使用时长收费)但是服务器有百分之0-3的回收率 选择4核16GB的服务器,通用型g5最便宜所以选择这个 选择无确定使用时长。三台实例,镜像选择centos7.5,硬盘40GB 选择交换机所在地址,宽带峰值可自由调配,毕竟按流量收费 下一

Flink1.12-2021黑马 1-6原理+算子+窗口+容错
课程课件和源码 链接:https://pan.baidu.com/s/1ZzBpgR21XGaBZHPMvF0_GQ 提取码:o0wm 复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V5的分享 代码示例pom <?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/