本文主要是介绍Redis Bitmaps 数据结构模型位操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Bitmaps 数据结构模型
Bitmap 本身不是一种数据结构,实际上它就是字符串,但是它可以对字符串的位进行操作。 比如 “abc” 对应的 ASCII 码分别是 97、98、99。对应的二进制分别是 01100010、01100010、01100011, 如下所示:
a b c
+--------+--------+--------+
|01100001|01100010|01100011|
+--------+--------+--------+
位图的最大优点之一是它们在存储信息时通常可以极大地节省空间。
例如,在一个用增量用户 ID 表示不同用户的系统中,仅使用 512 MB 内存就可以记住 40 亿个用户的单个比特信息。
1bit * 4,000,000,000 = 500,000,000 B = 488,281.25 KB = 476.8 MB
GETBIT 仅返回指定索引处的位的值。超出范围的位(寻址超出目标密钥中存储的字符串长度的位)始终被视为零。
root@ubuntu-x64_01:~# redis-cli --no-auth-warning -h 192.168.88.11 -p 6380 -a "******" get k1
"a"root@ubuntu-x64_01:~# redis-cli --no-auth-warning -h 192.168.88.11 -p 6380 -a "******" --eval getbit.lua k1
"01100001"
setbit
设置健的第offset个位的值(从0算起),如有8个用户 userid = 0, 1, 2, 3, 4, 5, 6,7 , 其中用户 1, 3, 5 对网站进行了访问 , 那么Bitmaps初始化如下:
setbit key offset value
192.168.88.11:6380> setbit users:2023-12-09 1 1
(integer) 0
192.168.88.11:6380> setbit users:2023-12-09 3 1
(integer) 0
192.168.88.11:6380> setbit users:2023-12-09 5 1
(integer) 0# 获取当前哪些用户访问了 , 其中 1 表示访问过的用户
root@ubuntu-x64_01:~# /redis-cli --no-auth-warning -h 192.168.88.11 -p 6380 -a "******" --eval getbit.lua users:2023-12-09
"01010100"
getbit
获取健的第offset位的值(从0算起), 如下获取 user 5 是否在 2023-12-09 访问过, 1表示访问,0表示没有访问,如果offset不存在,返回结果也是0, 超出范围的位始终被视为零。
192.168.88.11:6380> getbit users:2023-12-09 5
(integer) 1
bitcount
获取Bitmaps指定范围值为1的个数,如统计 2023-12-09 这天访问的用户数量
192.168.88.11:6380> bitcount users:2023-12-09
(integer) 3
bitop
bitmaps之前的运算,它可以做and(交集)、or(并集)、not(非)、xor(异或),并将结果保存在 destkey ,如计算 2023-12-09、2023-12-10 两天都访问过的用户数量
root@ubuntu-x64_01:~# redis-cli --no-auth-warning -h 192.168.88.11 -p 6380 -a "******" --eval getbit.lua users:2023-12-09
"01010100"
root@ubuntu-x64_01:~# redis-cli --no-auth-warning -h 192.168.88.11 -p 6380 -a "******" --evalgetbit.lua users:2023-12-10
"01100110"192.168.88.11:6380> bitop and users:2023-12-09_10 users:2023-12-09 users:2023-12-10
(integer) 1192.168.88.11:6380> bitcount users:2023-12-09_10
(integer) 2root@ubuntu-x64_01:~# redis-cli --no-auth-warning -h 192.168.88.11 -p 6380 -a "******" --eval getbit.lua users:2023-12-09_10
"01000100"
小结
将位图拆分为多个键很简单,例如为了对数据集进行分片,并且通常最好避免使用巨大的键。要将位图拆分到不同的键上,而不是将所有位设置为一个键,一个简单的策略就是为每个键存储 M 位,并使用 获取键名称和bit-number/M在键(bit-number MOD M)内寻址的第 N 位。
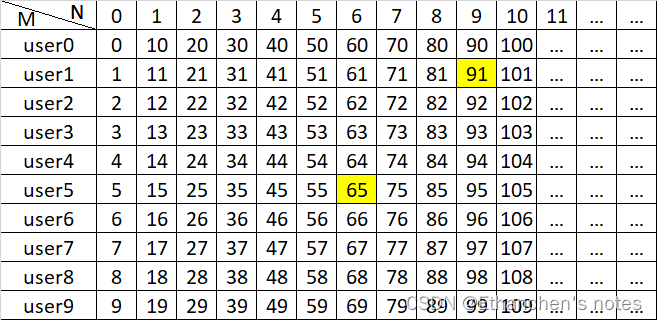
假设 M=10 , 约100个用户(有点少,仅用作举例):
则 第91个用户寻址如下:健名称: 91 MOD 10 = 1 即 key = user1 , N = 91/10 = 9
则 第65个用户寻址如下:健名称: 65 MOD 10 = 5 即 key = user5 , N = 65/10 = 6
SETBIT 、 GETBIT 、BITFIELD 均为 O(1)。
BITCOUNT、BITOP、BITPOS 是 O(n),其中n是比较中最长字符串的长度。
这篇关于Redis Bitmaps 数据结构模型位操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





