本文主要是介绍文献阅读:基于改进ConvNext的玉米叶片病害分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文献阅读:基于改进ConvNext的玉米叶片病害分类
CBAM注意力机制模块:
1:通道注意力模块,对输入进来的特征层分别进行全局平均池化(AvgPool)和全局最大池化(MaxPool)(两个池化都针对于输入特征层的高宽),再将平均池化和最大池化的结果利用共享的全连接层(Shared MLP)进行处理,然后将共享的全连接层所得到的结果进行相加再使用Sigmoid激活函数,进而获得通道注意图即获得输入特征层每一个通道的权重(0~1之间)。最后,将权重逐通道加权到特征层上。
2:与通道注意模块不同的是,空间注意模块关注的是输入图像的哪部分信息是更重要的,是通道注意模块的补充。为了计算空间注意力,首先沿着每一个特征点的通道方向应用平均池化和最大池化(两个池化都针对于输入特征层的通道)并将其堆叠起来生成一个有效的特征描述符(使用两个池化聚合一个Feature Map的通道信息,生成两个2D Map,分别为通道的平均池化特性和最大池化特性),即生成两个有效地二维特征图,再利用一个标准的卷积层(通道数为1的卷积)进行连接和卷积(调整了通道数),然后使用Sigmoid激活函数,进而得到二维空间注意力图即获得输入特征图每个特征点的权重值(0~1间),最后,将权重逐通道加权到特征层上。
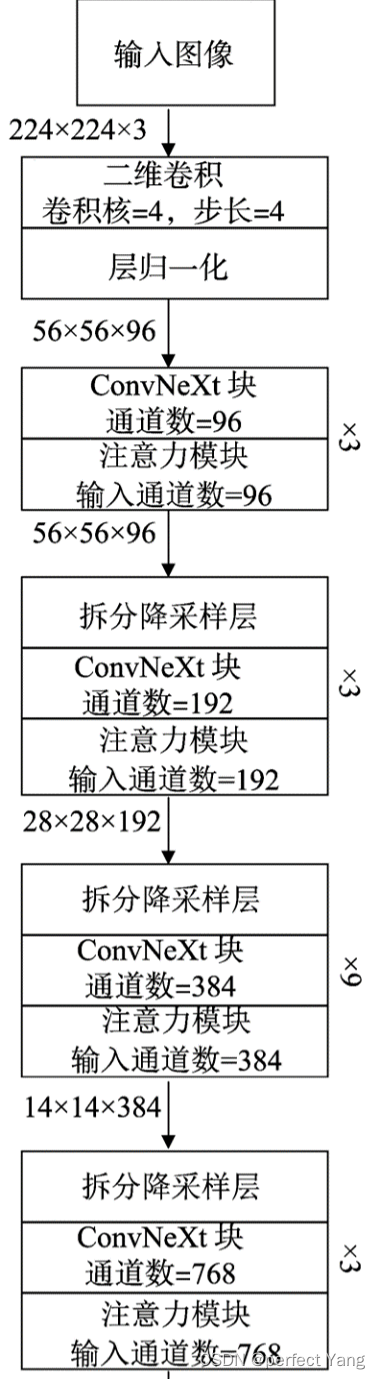
ConvNext网络结构
首先输入一张224*224的图像,然后通过大小4×4,步长为4的卷积核,然后通过一个归一化层,接着进行下采样和ConvNext块,最后通过全局最大池化,归一化(减少不同样本之间的差异,提高模型对于输入的泛化能力),全连接输出最终的图像。
ConvNext块的构成:首先经过一个大小为7×7步长为1填充为3的Depthwise卷积层,(Depthwise 卷积的一个卷积核只负责一个通道,一个卷积核只与一个通道卷积。那么卷积核数需要与输入的通道数相等,输出的通道数也不变,等于输入的通道数,等于卷积核数。所以depthwise卷积只改变特征图的大小,不改变通道数。但这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。)然后再卷积与激活(GELU激活函数:GELU (Gaussian Error Linear Units) 是一种基于高斯误差函数的激活函数,相较于 ReLU 等激活函数,GELU 更加平滑,有助于提高训练过程的收敛速度和性能),经过两次卷积之后特征图由1维变成了4维,之后通过1×1的卷积(相当于全连接层)和Layer Scale大小缩放,最后通过一个Drop Path正则化输出结果。
ConvNext原框架:

改进框架:
ConvNeXt Block模块代码:
class Block(nn.Module): # ConvNeXt Block模块
def __init__(self, dim, drop_rate=0., layer_scale_init_value=1e-6): # 初始化函数super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # 构建卷积depthwise convself.norm = LayerNorm(dim, eps=1e-6, data_format="channels_last")self.pwconv1 = nn.Linear(dim, 4 * dim) # 1x1的卷积层和全连接层的作用是一样的 pointwise/1x1 convs, implemented with linear layersself.act = nn.GELU() # GELU激活函数self.pwconv2 = nn.Linear(4 * dim, dim) # 注意pwconv1和pwconv2的输入输出channel是不同的self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)), # layer_scale层requires_grad=True) if layer_scale_init_value > 0 else Noneself.drop_path = DropPath(drop_rate) if drop_rate > 0. else nn.Identity() # 构建DropPath层def forward(self, x: torch.Tensor) -> torch.Tensor: # 正向传播过程shortcut = xx = self.dwconv(x) # 通过DW卷积x = x.permute(0, 2, 3, 1) # 通过permute方法调整通道顺序 [N, C, H, W] -> [N, H, W, C]x = self.norm(x) # LayerNorm层x = self.pwconv1(x) # 1x1的卷积层x = self.act(x) # GELU激活函数x = self.pwconv2(x) # 1x1的卷积层if self.gamma is not None:x = self.gamma * x # 对每个通道的数据进行缩放x = x.permute(0, 3, 1, 2) # 还原通道顺序 [N, H, W, C] -> [N, C, H, W]x = shortcut + self.drop_path(x) # 通过drop_path层并融合shortcutreturn x`
激活函数:Relu与LeakyRelu
由于 ReLU 在负半轴上的输出都为零,因此可以使得神经网络中的一些神经元变得不活跃,从而提高模型的稀疏性。但是负半轴为零使得输入数据为负值时会出现神经元不学习的情况。因此选用了LeakyRelu激活函数来处理这个问题。


通道数增多与卷积之后得到的图像特征数量有关
卷积层的作用本来就是把输入中的特征分离出来变成新的 feature map,每一个输出通道就是一个卷积操作提取出来的一种特征。在此过程中ReLU激活起到过滤的作用,把负相关的特征点去掉,把正相关的留下。输出的通道数越多就代表分理出来的特征就越多,但也可能存在重复的特征,毕竟是一个概率问题。
数据增强
数据集介绍
本研究采用的数据集进行了数据增强。通过采用旋转、高斯模糊、添加随机噪声、添加随机 位置的遮挡以及亮度调节等数据增强方法分别模 拟在图像采集中不同角度、其他背景叶片的遮挡以 及不同天气等外界因素的干扰,从而防止模型过拟合,同时提升模型的鲁棒性和泛化能力。对原数据集按照 6:2:2 的比例划分训练集、验证集与测试集。 本试验针对玉米种植中 3 种常见病害玉米灰斑病、玉米锈病以及玉米大斑病和健康叶片进行试验研究。 以 PlantVillagedataset公开数据集和吉林农业科技学院 “智慧农业”平台数据集作为试验对象,进行数据增强处理。

实验过程
本试验采用 PaddlePaddle2.3.2深度学习框架编程语言为python3.7,并采用4核CPU以及TaslaV100的GPU加速训练 。
网络采用交叉熵损失函数结合自适应矩估计(Adam)作为优化器进行训练,该优化器可以根据训练参数对学习率进行自适应调整训练迭代 100 次,批量大小设置为 64,学习率设置为0.000001。
实验结果


这篇关于文献阅读:基于改进ConvNext的玉米叶片病害分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







