本文主要是介绍计算机网络——数据链路层-可靠传输的基本概念(可靠传输服务、不可靠传输服务,分组丢失、分组失序、分组重复),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过上一篇的学习,我们已经知道使用差错检测技术,例如循环冗余校验CRC,接收方的数据链路层就可以检测出帧在传输过程中是否产生了误码,也就是出现比特错误。
如下图所示:

帧在传输过程中受到干扰,产生了误码。接收方的数据链路层通过帧尾中的帧检验序列FCS字段的值,也就是检错码可以检测出帧中出现了比特差错。
那么接下来该如何处理呢?
这取决于数据链路层向其上层提供的服务类型。
- 如果提供的是不可靠传输服务,则仅仅丢弃有误码的帧,其他什么也不做;
- 如果提供的是可靠传输服务,那就还要想办法实现:发送端发送什么,接收端就收到什么。
例如:接收方可以给发送方发送一个通知帧,告诉他之前发送的帧产生了误码,请重发;发送方收到通知后,重发之前产生了误码的那个帧即可。

实际上可靠传输的实现并没有我们想象的这么简单。
试想一下,这个通知帧如果也出现了误码,又会怎么样呢 ?
 本篇不会深入讨论实现可靠传输的具体方法,而是介绍可靠传输的基本概念,在后面会再详细介绍3种实现可靠传输的方法。
本篇不会深入讨论实现可靠传输的具体方法,而是介绍可靠传输的基本概念,在后面会再详细介绍3种实现可靠传输的方法。
一般情况下,有线链路的误码率比较低,为了减小开销,并不要求数据链路层向上提供可靠传输服务,即使出现了误码,可靠传输的问题由其上层处理;
然而对于无线链路,由于其容易受到干扰,误码率比较高,因此要求数据链路层必须向上层提供可靠传输服务。
需要说明的是,比特差错只是传输差错中的一种,从整个计算机网络体系结构来看,传输差错还包括分组丢失、分组失序以及分组重复。
此处我们将帧的称呼改为了分组,这意味着传输差错不仅仅局限于数据链路层的比特差错。
我们来举例说明:
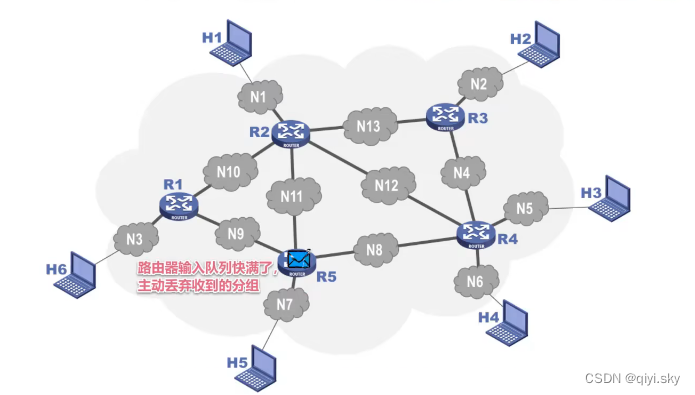
主机H6给主机H2发送的分组到达了路由器R5,由于此时R5的输入队列快满了,R5根据自己的分组丢弃策略,将该分组丢弃,这是一种分组丢失的情况;.
再来看分组失序:
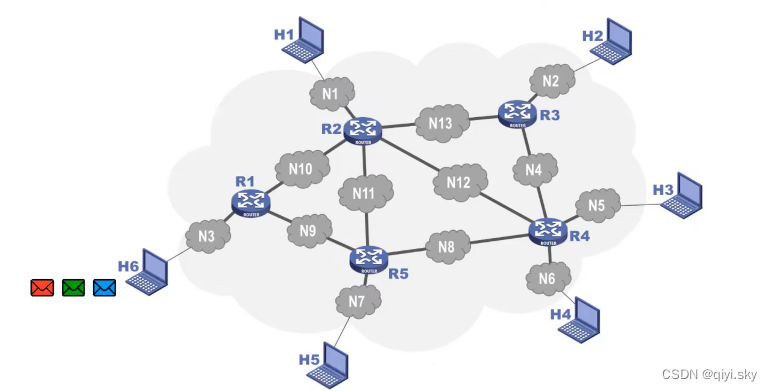

主机H6依次给主机H2发送了三个分组,但它们并未按照发送顺序依次到达H2,也就是说,最先发送的分组未必最先到达。
再来看分组重复的例子:

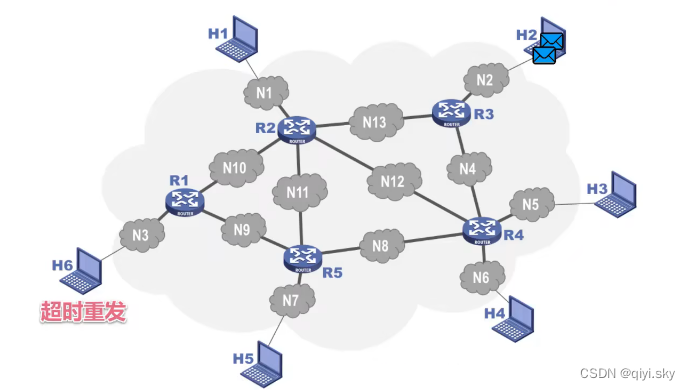
主机H6给主机H2发送的分组由于某些原因在网络中滞留了,没有及时到达H2;这可能造成H6对该分组的超时重发,重发的分组到达H2一段时间后,滞留在网络中的那个分组又到达了H2,这就会造成分组重复的传输差错。
分组丢失、分组失序以及分组重复这些传输差错一般不会出现在数据链路层,而会出现在其上层。
因此可靠传输服务并不仅局限于数据链路层,其他各层均可选择实现可靠传输服务。
例如下图TCP/IP的四层体系结构:

- 如果网络接口层使用的是802.11无线局域网,那么其数据链路层要求实现可靠传输;
- 如果网络接口层使用的是以太网,那么其数据链路层不要求实现可靠传输;
- 网际层中的IP协议向其上层提供的是无连接不可靠的传输服务;
- 运输层中的TCP协议向其上层提供的是面向连接的可靠传输服务;
- 而UDP协议向其上层提供的是无连接不可靠的传输服务 。
最后需要提醒,可靠传输的实现比较复杂,开销也就比较大,是否使用可靠传输取决于应用需求。
END
学习自:湖科大——计算机网络微课堂
这篇关于计算机网络——数据链路层-可靠传输的基本概念(可靠传输服务、不可靠传输服务,分组丢失、分组失序、分组重复)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






