本文主要是介绍UDS诊断 10服务的肯定响应码后面跟着一串数据的含义,以及诊断报文格式定义介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、首先看一下10服务的请求报文和肯定响应报文格式
a.诊断仪发送的请求报文格式

b.ECU回复的肯定响应报文格式

c.肯定响应报文中参数定义

二、例程数据解析
a.例程数据
0.000000 1 725 Tx d 8 02 10 03 00 00 00 00 00
0.000806 1 7A5 Rx d 8 06 50 03 00 32 01 F4 CC
b.解析诊断仪发送的数据
725 Tx d 8 02 10 03 00 00 00 00 00

c.解析ECU回复的肯定响应数据
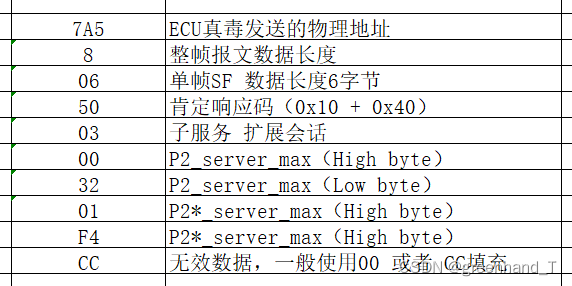
7A5 Rx d 8 06 50 03 00 32 01 F4 CC
三、诊断报文格式定义以及时间参数定义
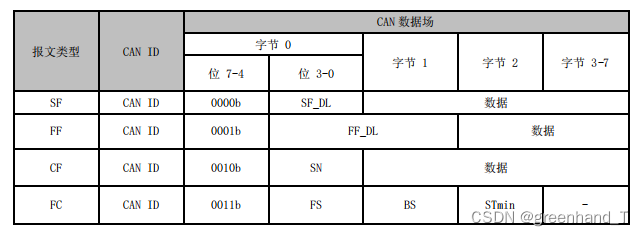
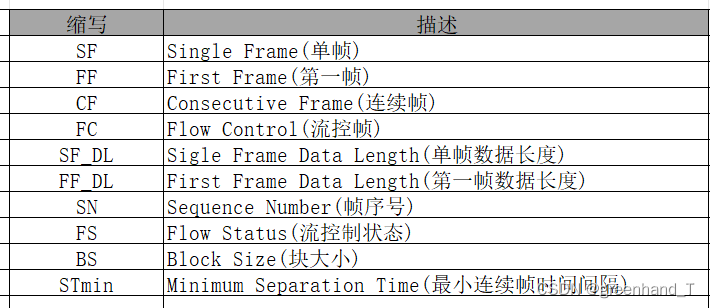
a.诊断报文格式定义
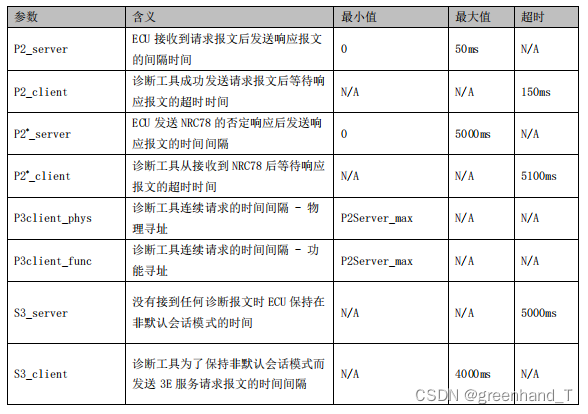
b.部分时间参数定义
四、总结
由此可见,10服务的肯定响应码后面跟着一串数据的含义是表示的时间参数;
00 32 表示P2_server参数,0x0032转换为十进制为50ms,即ECU 接收到请求报文后发送响应报文的间隔时间;
01 F4 表示P2_server参数*,0x01F4转换为十进制为500,但是这个参数的单位是10ms,所以500*10ms = 5000ms,即ECU 发送 NRC78 的否定响应后发送响应报文的时间间隔;
这篇关于UDS诊断 10服务的肯定响应码后面跟着一串数据的含义,以及诊断报文格式定义介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






