本文主要是介绍概率密度函数(PDF)正态分布,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概率密度函数(PDF)是一个描述连续随机变量取特定值的相对可能性的函数。对于正态分布的情况,其PDF有一个特定的形式,这个形式中包括了一个常数乘以一个指数函数,它假设误差项服从均值为0的正态分布:
p ( ϵ ( i ) ) = 1 2 π σ 2 exp ( − ( ϵ ( i ) ) 2 2 σ 2 ) p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\right) p(ϵ(i))=2πσ21exp(−2σ2(ϵ(i))2)
各名词解释:
p ( ϵ ( i ) ) p(\epsilon^{(i)}) p(ϵ(i)):这部分表示给定误差 ϵ ( i ) \epsilon^{(i)} ϵ(i)的概率密度。
σ 2 \sigma^2 σ2:正态分布的形状完全由两个参数决定:均值( μ \mu μ)和方差( σ 2 \sigma^2 σ2)。均值决定了分布的中心位置,而方差(标准差的平方)决定了分布的离散程度。这里均值( μ \mu μ)都假设为0因此不讨论。详细解释一下 σ 2 \sigma^2 σ2:
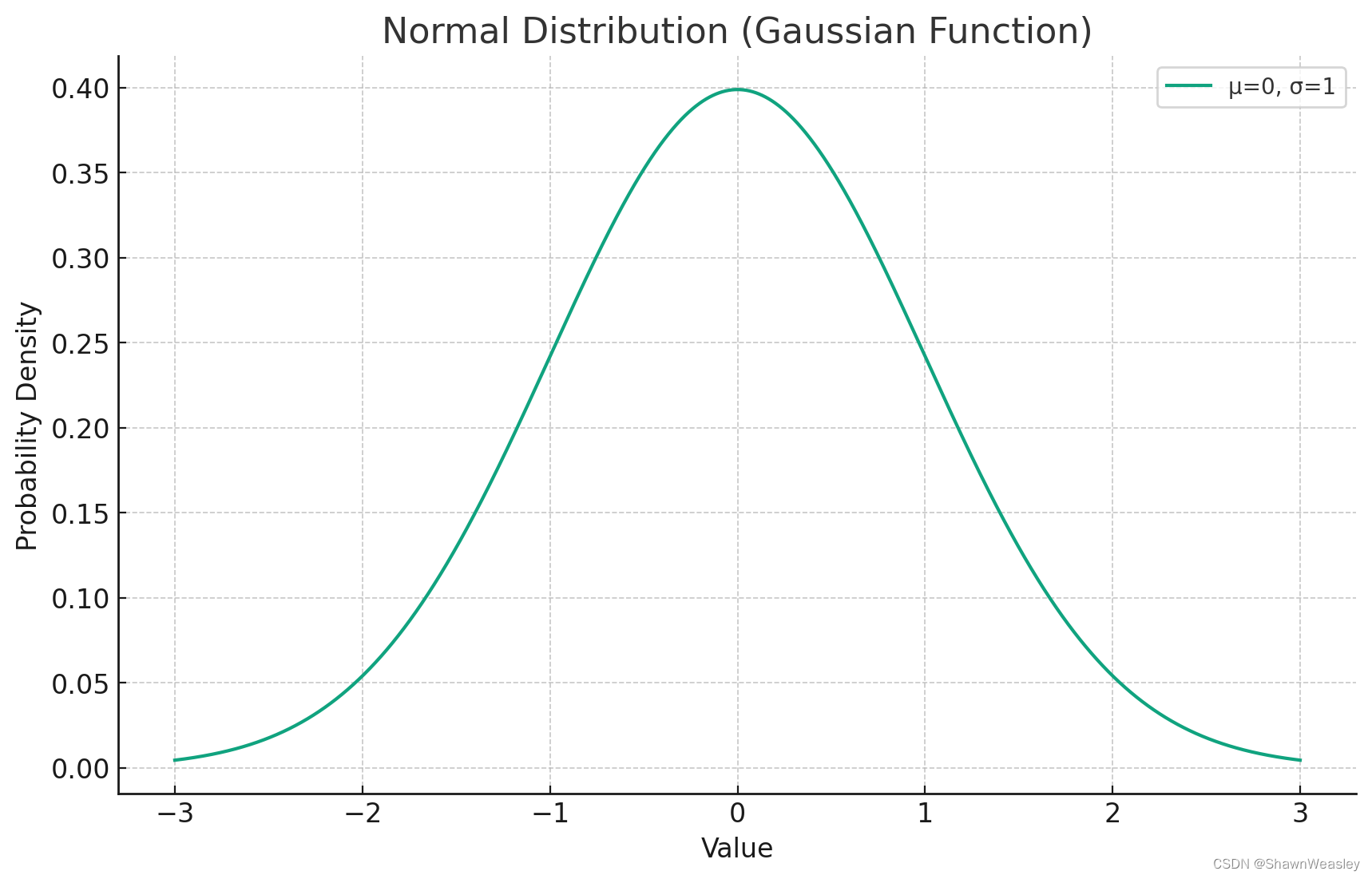
- σ 2 \sigma^2 σ2是分布宽度的度量, σ 2 \sigma^2 σ2的数值表示数据分布的离散程度: σ 2 \sigma^2 σ2越大,数据分布越分散; σ 2 \sigma^2 σ2越小,数据分布越集中(如上图中的钟形越瘦)。
- σ 2 \sigma^2 σ2的计算过程:
a.假设你有一组数据 X = { x 1 , x 2 , . . . , x n } X = \{x_1, x_2, ..., x_n\} X={x1,x2,...,xn},且已知均值 μ \mu μ为0。
b.计算每个数据点的平方: x i 2 x_i^2 xi2计算了每个数据点距离均值(0)的距离的平方。
c.计算这些平方的平均值(即方差 σ 2 \sigma^2 σ2): σ 2 = 1 n ∑ i = 1 n x i 2 \sigma^2 = \frac{1}{n} \sum_{i=1}^{n} x_i^2 σ2=n1∑i=1nxi2(即 x i 2 x_i^2 xi2求和后平均)
1 2 π σ 2 \frac{1}{\sqrt{2\pi\sigma^2}} 2πσ21:这是正态分布概率密度函数的前缀,其中 σ 2 \sigma^2 σ2是方差。它的作用是确保概率密度函数(PDF)的积分——也就是函数下整个面积等于1。在数学上,这意味着对于连续概率分布,确保所有概率值的总和为1。
exp: e e e是一个重要的数学常数(自然对数的底数),约等于2.71828,而exp是 e e e的幂。exp用于计算概率的指数部分,确保了大多数数据点都集中在平均值附近,而远离均值的数据点则呈指数级减少,就是让曲线呈“钟形曲线(高斯分布)”。
− ( ϵ ( i ) ) 2 2 σ 2 -\frac{(\epsilon^{(i)})^2}{2\sigma^2} −2σ2(ϵ(i))2:这是exp指数函数内的幂,代表了 ϵ ( i ) \epsilon^{(i)} ϵ(i)偏离均值0的程度。
- 由于我们假设误差项 ϵ \epsilon ϵ均值为0,所以这里直接用 ϵ ( i ) \epsilon^{(i)} ϵ(i)。这个比例的平方表示了误差项的值距离均值(0)的距离的平方,然后除以 2 σ 2 {2\sigma^2} 2σ2来“标准化”这个距离。在正态分布中,这个距离的平方越大,观测到该误差的概率就越低。
- 这个过程与误差项 ϵ ( i ) \epsilon^{(i)} ϵ(i)的值(第 i i i个数据点的误差项)的平方成正比,这里的平方是必要的,因为我们对误差的大小感兴趣,而不管它是正的还是负的。平方确保了所有的误差值都是非负的,且更大的误差(无论正负)都会产生更大的平方值。
- 与方差 σ 2 {\sigma^2} σ2的两倍成反比,这里 σ 2 {\sigma^2} σ2表示整个数据集中的误差项的分布宽度。方差的两倍是概率密度函数的标准组成部分,用于“标准化”误差项的平方,这样不同的分布(具有不同的方差)就可以使用相同的函数形式。这里的乘以 1 2 σ 2 \frac{1}{2\sigma^2} 2σ21类似于计算出“相对”值而不是“绝对”值,在不改变误差项的方向的情况下,调整它的相对重要性。主要作用是:由于不同的数据集可能有不同的方差(即不同的误差分布宽度),我们需要有一种方式来标准化这些误差,使它们可以在统一的尺度上比较。
- − 1 2 σ 2 -\frac{1}{2\sigma^2} −2σ21:这个负号和分母 2 σ 2 {2\sigma^2} 2σ2一起工作,形成一个比例因子,表示一个衰减的过程,它反映了误差项 ϵ ( i ) \epsilon^{(i)} ϵ(i)相对于方差的大小。由于是负指数,误差项的平方越大, e e e的幂就越小,从而降低了该误差值的概率密度。
这篇关于概率密度函数(PDF)正态分布的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








