本文主要是介绍算法介绍及实现——GM(1,1)预测模型(附完整Python代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
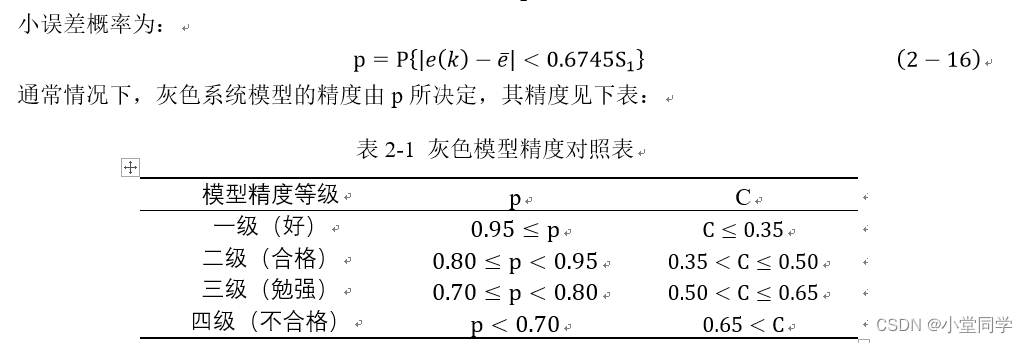
一、模型介绍
二、模型建立
三、模型实现及应用
一、模型介绍
上世纪80年代,我国杰出学者提出了著名的数学模型—灰色系统模型,30年来,灰色系统理论已经广泛的运用于经济、气象、环境、地理等众多领域,解决了生产生活和科学研究中很多亟待解决的问题,且均取得了不错的效果。灰色系统之所以能应用如此广泛,是因为灰色系统对数据的要求不高,它不需要完整清晰的数据集,仍然能对数据进行建模分析。灰色系统理论是把一切变量看成灰色量进行处理。基于这样的理论原理,揭示了数据中相对复杂、离散的内在规律,使得时序数据的规律性加强而降低其随机性。经过30多年的发展,灰色系统理论在的实践应用中不断的丰富和完善,现在的关于灰色系统理论研究主要是包括灰色系统建模理论和灰色预测方法在内的六大领域。
灰色系统理论是一个比较庞大的体系,在数据分析有很多的广泛使用,包括灰色关联分析、GM(1,1)、GM(2,1)、GM(1,n)以及各种改进的灰色模型算法。今天主要介绍GM(1,1)这个最简单的模型。
(参考博文)优质博文推荐:灰色系统理论及其应用 (一) :灰色系统概论、关联分析、与传统统计方法的比较_wamg潇潇的博客-CSDN博客_灰色系统理论及其应用
二、模型建立
所谓GM(1,1)就是一阶微分方程和一个变量。建模过程如下:



三、模型实现及应用
用 前7年考研人数作为实验实验数据,使用GM(1,1)进行建模预测。模拟成果如下:

对后两年考研人数进行预测:分别约为531w和622w。![]()
完整代码:
import numpy as np
import matplotlib.pyplot as pltclass GM_1_1:"""使用方法:1、首先对类进行实例化:GM_model = GM_1_1() # 不传入参数2、使用GM下的set_model传入一个一维的list类型数据: GM_model.set_model(list1)3、想预测后N个数据:GM_model.predict(N)想获得模型某个参数或实验数据拟合值,直接访问,如:GM_model.modeling_result_arr、GM_model.argu_a...等想输出模型的精度评定结果:GM_model.precision_evaluation()"""def __init__(self):self.test_data = np.array(()) # 实验数据集self.add_data = np.array(()) # 一次累加产生数据self.argu_a = 0 # 参数aself.argu_b = 0 # 参数bself.MAT_B = np.array(()) # 矩阵Bself.MAT_Y = np.array(()) # 矩阵Yself.modeling_result_arr = np.array(()) # 对实验数据的拟合值self.P = 0 # 小误差概率self.C = 0 # 后验方差比值def set_model(self, arr:list):self.__acq_data(arr)self.__compute()self.__modeling_result()def __acq_data(self, arr:list): # 构建并计算矩阵B和矩阵Yself.test_data = np.array(arr).flatten()add_data = list()sum = 0for i in range(len(self.test_data)):sum = sum + self.test_data[i]add_data.append(sum)self.add_data = np.array(add_data)ser = list()for i in range(len(self.add_data) - 1):temp = (-1) * ((1 / 2) * self.add_data[i] + (1 / 2) * self.add_data[i + 1])ser.append(temp)B = np.vstack((np.array(ser).flatten(), np.ones(len(ser), ).flatten()))self.MAT_B = np.array(B).TY = np.array(self.test_data[1:])self.MAT_Y = np.reshape(Y, (len(Y), 1))def __compute(self): # 计算灰参数 a,btemp_1 = np.dot(self.MAT_B.T, self.MAT_B)temp_2 = np.matrix(temp_1).Itemp_3 = np.dot(np.array(temp_2), self.MAT_B.T)vec = np.dot(temp_3, self.MAT_Y)self.argu_a = vec.flatten()[0]self.argu_b = vec.flatten()[1]def __predict(self, k:int) -> float: # 定义预测计算函数part_1 = 1 - pow(np.e, self.argu_a)part_2 = self.test_data[0] - self.argu_b / self.argu_apart_3 = pow(np.e, (-1) * self.argu_a * k)return part_1 * part_2 * part_3def __modeling_result(self): # 获得对实验数据的拟合值ls = [self.__predict(i+1) for i in range(len(self.test_data)-1)]ls.insert(0,self.test_data[0])self.modeling_result_arr = np.array(ls)def predict(self,number:int) -> list: # 外部预测接口,预测后指定个数的数据prediction = [self.__predict(i+len(self.test_data)) for i in range(number)]return predictiondef precision_evaluation(self): # 模型精度评定函数error = [self.test_data[i] - self.modeling_result_arr[i]for i in range(len(self.test_data))]aver_error = sum(error)/len(error)aver_test_data = np.sum(self.test_data)/len(self.test_data)temp1 = 0temp2 = 0for i in range(len(error)):temp1 = temp1 + pow(self.test_data[i]-aver_test_data,2)temp2 = temp2 + pow(error[i]-aver_error,2)square_S_1 = temp1/len(self.test_data)square_S_2 = temp2/len(error)self.C = np.sqrt(square_S_2)/np.sqrt(square_S_1)ls = [ifor i in range(len(error))if np.abs(error[i]-aver_error) < (0.6745*np.sqrt(square_S_1))]self.P = len(ls)/len(error)print("精度指标P,C值为:",self.P,self.C)def plot(self): # 绘制实验数据拟合情况(粗糙绘制,可根据需求自定义更改)plt.figure()plt.plot(self.test_data,marker='*',c='b',label='row value')plt.plot(self.modeling_result_arr,marker='^',c='r',label='fit value')plt.legend()plt.grid()return pltif __name__ == "__main__":GM = GM_1_1()# 前7年的每年考研报名人数x = [177, 201, 238, 290, 341, 377, 457]GM.set_model(x)print("模型拟合数据为:",GM.modeling_result_arr)GM.precision_evaluation()print("后两个模型预测值为:",GM.predict(2))p = GM.plot()p.show()浅薄之见,敬请指正!
共勉!
这篇关于算法介绍及实现——GM(1,1)预测模型(附完整Python代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





