本文主要是介绍AI绘画权益纠纷:你的创作是否触碰了版权底线?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近,北京互联网法院就一起人工智能生成图片(AI绘画图片)的著作权侵权案进行了首次审理并做出了判决。这是中国首例牵涉到“AI文生图”著作权的案件,庭审过程在多个平台进行直播,吸引了众多网友,同时引发了对于AI生成内容与著作权之间关系的广泛讨论。
那么近年来,版权问题,尤其是扩散模型中的版权问题,已成为突出的关注点。先前的研究主要集中在图像层面的版权侵犯,即生成模型完全复制受版权保护的图像。此外,这些早期研究主要使用与目标主题在语义上相似的提示来检查版权侵犯。然而,版权侵犯可能比仅仅复制整个图像更为微妙,并且可以通过与版权主题不太直接相关的提示来触发。在工作中,通过深入研究部分版权侵犯来解决先前研究的局限性,这将图像的某些部分视为受版权保护的内容,并使用与受版权主题相差较大的提示。作者开发了一个数据生成pipeline,便于为扩散模型的版权研究创建数据集。利用该pipeline,创建了包含不同扩散模型的版权侵犯样本的数据集。对生成的数据进行了各种标准的评估。结果显示,在一系列扩散模型中,包括最新的Stable Diffusion XL,生成侵犯版权的内容相当普遍。
引言
扩散模型已经成为生成模型的新前沿,许多研究成功证明了它们在各种图像合成任务中生成高质量图像的能力。然而,这些生成图像的显著质量引发了关于版权保护的额外关注。最近的研究表明,扩散模型往往倾向于通过记忆训练数据集中的图像轻松生成受版权保护的内容。对于扩散模型中版权保护的担忧也演变成了一种切实的威胁,因为已经有多起与使用扩散模型进行商业用途的公司涉及的版权侵权诉讼。值得注意的是,有一些诉讼案例:Stability AI 和 MidJourney 都面临因未经艺术家同意而在其模型上训练的民事诉讼,使其模型能够复制这些艺术家的风格和作品。在提示是通用的且不针对特定主题的情况下生成的图像包含受版权保护的信息,这尤为令人担忧。这可能会严重限制这些模型的未来用途,即使在没有明确提示的情况下,它们也可能生成受版权保护的信息。因此,需要进行版权保护研究,以确保这些模型可以安全、公平地使用,充分发挥其能力。
先前关于扩散模型版权侵权的研究主要集中在内容复制的挑战上。这指的是扩散模型创建完全复制现有图像的情况。然而,版权侵犯可能涉及更广泛的领域,在这些领域中,生成的图像不包含来自任何训练源的复制部分,但它们可能具有与受版权保护的内容显著相似的特征。
「贡献」 :本研究通过更为现实的视角解决与扩散模型相关的版权挑战。开发了一个旨在生成跨多种扩散模型侵犯版权实例的框架。在给定目标主题的情况下,数据生成pipeline首先寻找能够诱导生成受版权保护内容的提示,同时避免包含与目标主题相关的过于敏感的信息。随后,pipeline通过基于这些经过精心策划的提示生成图像来展示扩散模型。最后,引入了一个版权评估机制,通过自动标注生成图像中表现出与受版权元素相似的部分来识别部分版权侵权的实例。此外,编制了一组潜在的受版权保护主题,并执行pipeline来生成在这些选择的主题中展现版权侵犯的提示样本,如下图1所示。

这组示例主题和提示可以作为一个数据集,以进一步促进更真实场景下的版权研究,并用于研究扩散模型的行为。通过进行全面的分析来评估数据生成pipeline的性能。这包括进行一系列实验以评估提示的质量、版权测试的性能以及基于预定义标准的图像质量。展示了生成的版权数据集在调查各种扩散模型的版权问题的案例研究中的应用。案例研究揭示了一个令人担忧的现实:即使是最新的扩散模型在面对与受版权主题不相关的提示时,也容易生成包含受版权保护内容的图像。
背景
扩散模型是一类建模扩散过程的生成模型。在扩散过程中,源数据逐渐通过向其添加噪声而变形,直到源数据本身也成为噪声(Sohl-Dickstein等人,2015年)。扩散模型的目标是学习扩散的反向过程,即尝试在给定嘈杂输入的情况下重构目标。扩散模型可以直接学习在每个反向步骤预测较少噪声数据的过程,也可以学习在每个步骤预测噪声,然后使用预测的噪声对数据进行去噪(Ho,Jain和Abbeel,2020年;Saharia等人,2022年)。早期的扩散模型在图像级别工作,并尝试直接从噪声中重构图像。然而,图像级别的反向步骤需要进行密集的计算,限制了重构的速度。相反,Rombach等人(2022年)建议首先将图像转换为低维隐藏空间,然后在隐藏级别应用扩散模型。随后,潜在扩散模型比在图像级别工作的模型快得多,因此可以在大型数据集上进行训练,例如LAION(Schuhmann等人,2022年)。在反向过程中预测噪声或先前状态通常使用U-Net(Ronneberger,Fischer和Brox,2015年)。为了实现扩散模型的条件生成,将交叉注意力模块(Vaswani等人,2017年)embedding到U-Net中,以便生成考虑条件(Rombach等人,2022年)。提出了其他引导技术以进一步提高扩散模型的条件生成性能(Ho和Salimans,2021年;Song等人,2020年;Dhariwal和Nichol,2021年)。
版权保护和记忆问题与扩散模型密切相关。Carlini等人(2023年)观察到扩散模型通过提示模型重构训练数据中的图像具有记忆训练数据的能力。Somepalli等人(2023a)通过利用模型生成现有海报、艺术品和其他潜在受版权保护的图像,讨论了扩散模型通过记忆而导致的版权侵犯。最近的一些研究也致力于解决版权问题。具体而言,Vyas、Kakade和Barak(2023年)提出了受差分隐私启发的可证明的版权保护定理。Gandikota等人(2023年)、Kumari等人(2023年)和Zhang等人(2023年)提出了模型编辑技术,可以引导生成过程以避免生成某些概念。此外,一些研究提出将小扰动注入图像中作为水印,使得这些图像无法被扩散模型记忆(Cui等人,2023年;Ray和Roy,2020年;Zhao等人,2023年)。
扩散模型中的不稳定引导
扩散模型属于条件生成模型,通过从p(x|c;Φ)的样本中生成输出x,其中p(·;Φ)是由权重集Φ参数化的学习条件概率分布,c是用于引导生成过程的条件。对于接受提示的扩散模型,有c = E(p;Θ),其中p是提示文本,E是由集合Θ参数化的embedding模型。由于通常通过经验风险最小化学习p和E,它们都容易出现过拟合的问题。例如,Θ仅通过来自训练数据的关联来压缩输入p,而没有学习实际的语言语义。此外,当c是一个包含训练数据中未见子序列的序列时,p(·;Φ)可以通过忽略未见部分并使用c的其余部分过拟合于训练数据。因此,即使有输入条件,扩散模型也容易出现过拟合的问题。通过使用通用提示在实证中展示了不稳定引导的问题。在下图2中,

包含短语“Great Wave off Kanagawa by Hokusai”(Somepalli等人,2023a)在视觉上相似的图像。类似地,与“Superman”主题无关的提示,但包含“superhero”一词的提示将生成类似“Superman”的图像。
因此,鉴于这类模型倾向于在没有直接提示的情况下生成目标图像,本研究利用了扩散模型的这种不稳定行为,并提出了一个自动测试潜在版权侵权的流程,即使使用的提示未必直接具有对抗性质。
版权数据生成pipeline
在本节中,将介绍专为版权研究量身定制的数据生成pipeline。给定一组目标主题,pipeline首先创建能够生成包含与目标主题相关的潜在受版权保护内容的非敏感提示。然后,该pipeline使用这些提示从扩散模型中生成图像。最后,pipeline执行版权测试,确定生成的图像中包含潜在受版权保护的内容的区域。
生成非敏感提示
「关键词提取」 对于条件扩散模型,提示通过交叉注意力模块集成到扩散过程中。然而,这些注意力模块往往在提示内的单词之间具有不平衡的注意力分布。在下图3中展示了这种不平衡注意力的一个例子。

这对跨模块注意力模块的观察激发了pipeline中关键词提取过程的设计。广义而言,目标是识别在图像生成过程中做出实质贡献的词语。有了这些关键词,可以进一步构建在语义上偏离目标主题的句子。然而,由于存在提取的关键词,这些新构建的句子仍应保留生成与目标主题相关内容的能力。
为提取关键词,作者比较了扩散模型最后反向步骤中与每个单词相关联的注意力图。首先,收集每个扩散模型中每个注意力层的注意力图的平均值。然后,在注意力图上应用两种类型的滤波器以选择关键词。一个软滤波器旨在包含在生成受版权保护的内容方面可能重要的单词,并对误报更宽容。另一个硬滤波器设计更严格,侧重于查找生成受版权保护内容必须存在的单词。对于每个滤波器,定义了一个强度函数I(M),用于计算给定注意力图张量M的强度。对于软滤波器,将强度函数(M)定义为(M) = ρ(M, 90) - ρ(A, 50),其中ρ(M, q)给出了张量M的平坦部分的第q个百分位数的值。然后,计算跨标记的强度值的平均值(不包括开始、结束和填充标记)。然后标记那些是完整单词且强度大于平均值的标记为关键词。对每个层的平均注意力图重复此过程,并获取已识别的关键词的并集。这形成了“软滤波器”中选择的关键词。对于硬滤波器,将强度函数(M)定义为(M) = Q(M, d),其中Q(M, d)给出了M中大于d的值的比例(在通常的标准化之后)。然后,将每个标记的强度值与p = P(Z > d)进行比较,其中Z∼N(0,1)。然后,标记那些是完整单词且强度大于p的标记为关键词。在设置中,设置d=1.96。对每个层的平均注意力图重复此过程,而“硬滤波器”在层间进行交集操作,仅通过在每个注意力层上显示显著贡献的词语。使用“软滤波器”和“硬滤波器”,可以实现平衡。
「提示生成」
在成功提取关键词之后,重点转向形成可能生成受版权保护内容的短语。首先,形成可能生成受版权保护内容的关键词组合。为了简化这个过程,每个关键词组合都由软滤波器标记的关键词的某个子集形成,该子集也是硬滤波器标记的关键词的超集。接下来,使用专门设计的query(见下表1第1行)指导语言模型使用给定的关键词组合形成连贯的短语。一旦形成包含关键词的短语,再次将每个短语传递给语言模型以创建连贯的句子。由于短语中的关键词可能导致语言模型回忆目标主题并引导生成句子朝向目标主题,在语言模型中包含明确的指令,拒绝在生成句子过程中添加与目标主题相关的信息(见下表1第2行)。

然后,修剪生成的提示,只收集K个提示。修剪机制(下图4)固定隐藏状态输入,然后将目标主题embedding和提示embedding分别馈送到交叉注意力层。然后,计算目标embedding的交叉注意力输出与每个提示embedding的交叉注意力输出之间的L2距离。最后,返回具有最低L2距离的K个提示。
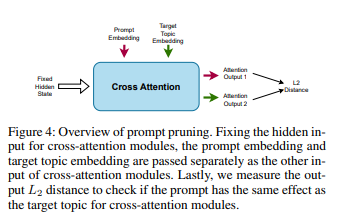
「部分版权测试」
数据生成pipeline的最后阶段是确定生成的图像中被认为与包含受版权保护内容的真实图像块相似的部分。为此,作者引入了部分版权测试。在此测试中,query图块指的是给定图像的矩形部分。首先通过将背景像素替换为黑色像素来从生成的图像中去除背景。然后,在不同位置系统地裁剪N(在设置中N = 1024)个不同大小的图块,丢弃包含50%以上背景像素的块。然后,将这些系统地选择的块与包含受版权保护内容的真实图像块进行比较。比较是通过计算两个图块的CLIP-embedding(Radford et al. 2021)的余弦相似性来完成的。相似性得分超过0.85的来自生成图像的块被认为包含足够的受版权保护内容。这个迭代的版权测试对所有N块继续进行,将所有包含足够受版权保护内容的块识别为一个生成图像中的版权侵权指示。在下图5中展示了部分版权测试的示例。

搜集潜在的受版权保护数据
为了充分利用pipeline来识别潜在的版权侵权,需要一个输入主题和相应的带标注目标图像。主题是指将生成提示以测试潜在版权侵权的主题。为了便于检测生成图像中的受版权保护元素,有必要具有与受版权保护主题相关联的目标图像进行比较。采用手动标注的方式标记这些目标图像中存在的受版权保护内容。
「搜集潜在受版权保护的主题」
目标是识别与包含高度具体特征的受版权保护图像相关的主题。因此,生成这些特征不会被视为创作性作品,从而导致明确的版权侵权(Milner Library 2023)。因此,集中在三个不同的领域:电影、视频游戏和商标(商标)上:电影、视频游戏和商标(商标)。这些领域与潜在的受版权保护主题特别契合,因为电影、视频游戏和商标是为商业用途而设计的产品。因此,这些产品的创作者有保护其知识产权的动机。此外,这些领域的版权侵权形式是对主题的显式复制,而不是样式转移的形式。这些领域的图像也非常受欢迎,增加了它们被包含在扩散模型训练集中的可能性。此外,还优先考虑最近发布的电影和视频游戏,以确保样本质量高。近几年的图像更有可能受到版权保护,因为它们尚未进入公共领域(Office 2023)。然而,值得强调的是,作者的方法是一种学术研究形式,因此避免断言作者在本研究中收集的主题明确符合受版权保护的主题资格。
其中一个方向涉及查找包含多义词的单词或短语的标题。多义词指的是一个对象具有根据上下文变化的几种可能含义的能力。这样一个术语的示例是“Halo”,它可以指的是天使头上的发光环,也可以指的是行星周围的环或视频游戏。然而,即使在前一种情况下使用,生成的图像(前面图1)仍然来自于视频游戏。另一条途径是识别被过度表示的广泛类别。例如,超级英雄类别被“Superman”过度表示,运动鞋品牌被“Nike”过度表示。发现当为这些类别中的图像提供通用提示时,扩散模型倾向于生成包含超人标志或角色的图像(在前一种情况下)或耐克标志的图像(在后一种情况下)。为了有效地为这两个方向生成目标主题的候选项,利用语言模型的能力,提供源自于包含多义词的著名游戏和电影标题的提示。
值得注意的是,将与艺术作品和个体艺术家相关的主题排除在作者指定的目标主题之外。在本研究的范围内,主要重点是评估部分版权侵权。具体而言,这涉及在图像片段中找到在视觉上可辨别的受版权保护内容。作者发现扩散模型可以准确复制艺术家的风格(Casper et al. 2023),但这可能是衍生作品(Cornell 2022)的一种形式,这种形式的版权侵权较难确定。因此,在涉及艺术风格和特定艺术家创作的版权事项时保持克制。在艺术品中识别风格复制需要更为复杂的方法,涉及对风格如何被使用的更深入考虑,这超出了本工作范围的范围。
「图像收集和标注」
本节将描述如何收集具有潜在受版权保护内容的图像并对其进行标注以进行版权测试。对于每个目标主题,手动收集5张代表性图像,这些图像是根据多个标准选择的。这些图像应包含每个主题的独特和/或受版权保护的商标特征。作者手动标注这些特征的位置,使用边界框来进行评估过程。此类特征的示例包括与每个主题相关的商标和角色。为了进行更全面的版权测试,选择了具有2个目标的各种各样的图像。首先,对于围绕特定视频游戏系列的标志,例如下图6中的情况,选择该系列中不同版本的游戏的图像。同样,还选择了以各种姿势和角度展示的目标角色的图像。

实验
实验分为两个部分。首先,评估数据生成pipeline的各个阶段。然后,展示不同扩散模型在生成受版权保护内容方面的行为的案例研究。
「实验设置」
选择使用Stable Diffusion模型作为版权实验的测试对象。具体来说,在Stable Diffusion 1.1、Stable Diffusion 1.4、Stable Diffusion 1.5、Stable Diffusion 2、Stable Diffusion 2.1和Stable Diffusion XL(Podell等人2023)上运行数据生成pipeline。对于每个模型,应用相同的主题集作为输入。主题集包含25个想法,其中有9个与电影相关的主题,9个与游戏相关的主题和7个与商标相关的主题。对于每个pipeline运行,为每个主题生成10个非敏感提示,并为每个提示创建10个图像。对于需要图像收集和块标注的版权测试,利用人工评估员收集每个主题的5张图像,并标注这些图像以标记受版权保护的内容。使用随机种子来确保实验的可重复性。然而,由于涉及使用OpenAI API2进行非确定性温度设置,GPT结果是不可重现的,以确保生成的提示的可变性。在实验中使用一张A100 80GB GPU。整个生成pipeline对于Stable Diffusion 1.1大约需要2小时,对于Stable Diffusion XL大约需要40小时。
「提示敏感性」
为了定量测试生成提示的敏感性,使用BertScore(Zhang等人2019)比较生成的提示与它们的目标主题之间的相似性,这些目标主题也以文本形式制定。BertScore通过计算输入文本的embedding的精确度、召回率和F1得分来衡量两个输入文本的语义相似性。预期生成的提示与其相关的目标主题之间的BertScore较低,因为生成的提示应该包含与目标主题有关的少量语义信息。此外,使用随机提示作为基准进行提示敏感性评估。结果如下图7所示。
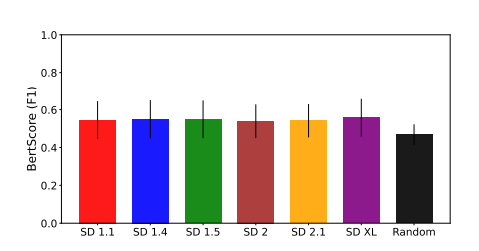
生成的提示与随机提示相比具有稍高的相似性分数,因为它们需要包含一些相关信息才能生成包含受版权保护内容的图像。然而,为所有扩散模型生成的提示的BertScore(F1)都小于0.6,这表明它们在语义上与相应的目标主题不相似。
「交叉注意力输出」
为了评估使用交叉注意输出的修剪方法(前面图4),使用下表2中显示的L2距离将生成的提示的结果与使用随机提示的基线进行比较。
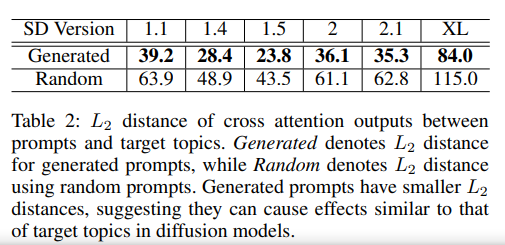
对于在所有测试的扩散模型上生成的提示,生成的提示embedding和目标主题embedding之间的输出差异明显小于随机提示embedding和相应目标主题embedding之间的结果。该结果证实了修剪方法在选择生成的提示时是有效的,这些提示具有触发类似于相应目标主题的扩散模型效果的最大潜力。
「对部分版权侵权识别的评估」
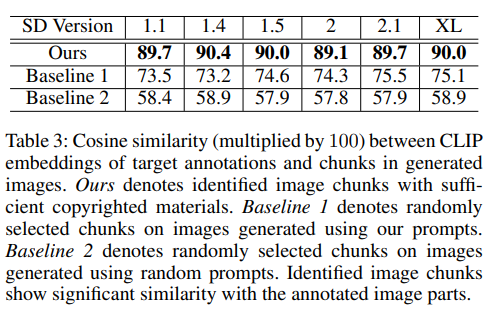
本节旨在评估作者提出的部分版权侵权识别技术的性能。对于两个图像块之间的相似性测量,计算两个图像块的CLIP-embedding的余弦相似性。这种相似性测量应用于使用作者在目标图像上的标注块标识的生成图像上的图像块。此外,还测量了随机块与标注块之间的相似性进行比较。最后,通过测量在使用随机提示生成的图像上的随机块与目标标注之间的相似性,增加了随机性。根据下表3中的结果,识别的块与目标标注块之间显示了很高的余弦相似性(约为0.9),而在生成的图像上选择的随机块和随机图像上的块分别只有约0.7和0.6的余弦相似性。
「生成图像的质量」
作者的目标是生成具有版权侵权的图像。因此,通过检查生成的图像是否包含受版权保护的内容来评估生成图像的质量。为此,计算了具有至少一个识别块的生成图像的比例。根据下图8,对于所有测试的扩散模型,超过70%的图像具有至少一个使用版权测试识别的块。

对于没有识别块的图像,它们仍然可能包含受版权保护的内容。这是因为图像收集和标注可能在现实中未涵盖所有受版权保护的特征。
「案例研究:扩散模型之间的版权问题」
扩散模型正在经历快速的发展阶段,最近提出的扩散模型在生成高质量图像方面表现出改进的性能。然而,它们在版权保护方面的表现是否有所提高仍然是个问题。在本节中,调查了扩散模型在这方面的表现。
初步案例研究探讨了各种扩散模型对不同主题的反应。为此,利用了前一节中的实验设置。具体而言,获得了每个主题具有识别的受版权保护内容图像的比例,并在不同的扩散模型之间进行了比较(下图9 )。
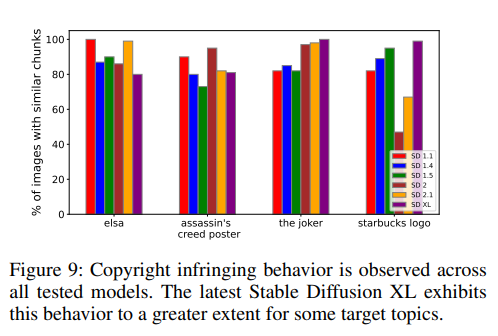
尽管每个模型对每个主题的性能各不相同,但很明显,所有模型都表现出侵犯版权的行为,对于这四个不同的主题。实际上,对于一些主题,像SD-2和SD-XL这样的后期模型表现出了更严重的侵犯版权的行为。这表明目前的扩散模型训练方法无法有效防止版权侵权的发生。
在关于主题脆弱性的案例研究之后,继续进行另一项交叉验证实验,将为一个扩散模型生成的提示应用于另一个扩散模型。通过这个实验,旨在更深入地了解为早期版本的扩散模型生成的提示在最新扩散模型上的性能。下图10显示了为旧版扩散模型生成的提示仍然可以在新模型上使用。
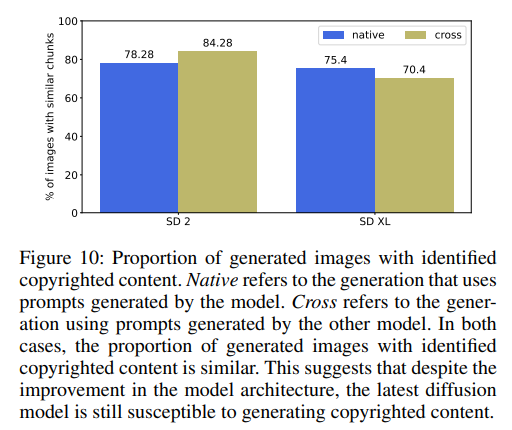
因此,尽管在生成具有更好视觉质量的高分辨率图像方面有所改进,扩散模型仍然容易生成受版权保护的内容。此外,扩散模型中的版权问题跨越了一系列扩散模型,并且对于最新的扩散模型仍然没有解决。
结论
在这项工作中,作者提出了一个数据生成pipeline,用于在扩散模型上生成逼真的侵犯版权的示例。提出的pipeline生成的提示似乎与目标受版权保护的主题无关,但仍然可以用于生成受版权保护的内容。此外,pipeline解决了部分版权侵权问题。通过作者的提案,呈现了一个工具包,其中包括潜在的受版权保护的主题,带有受版权保护的内容标注的受版权保护的主题的目标图像,以及一个数据集生成pipeline。该工具包可以整体用于扩散模型,以测试与版权相关的性能并生成侵犯版权的样本。通过这个工具包展示了当代扩散模型极易生成受版权保护的内容。研究结果强调了采取适当措施以防止模型生成受版权保护的材料的迫切必要性。这尤其关键,因为作者的研究表明,即使是常见短语也可能促使模型创建包含受版权保护内容的图像。这项工作可以为扩散模型的版权研究提供进一步的支持。例如,研究社区可以利用这个工具包根据与版权相关的标准评估扩散模型。此外,版权保护算法可以使用它来评估其有效性。
参考文献
[1] Investigating Copyright Issues of Diffusion Models under Practical Scenarios
链接:https://arxiv.org/pdf/2311.12803.pdf
更多精彩内容,请关注公众号:AI生成未来

这篇关于AI绘画权益纠纷:你的创作是否触碰了版权底线?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







