本文主要是介绍WordCount 源码解析 Mapper,Reducer,Driver,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
创建包 com.nefu.mapreduce.wordcount ,开始编写 Mapper , Reducer ,
Driver
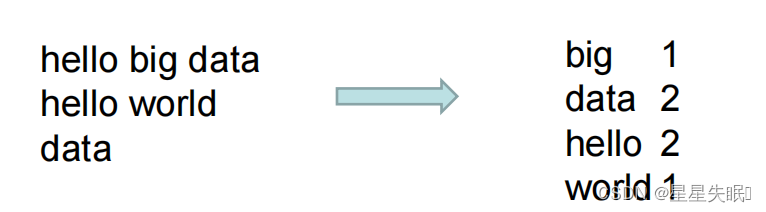
用户编写的程序分成三个部分: Mapper 、 Reducer 和 Driver 。
( 1 ) Mapper 阶段
➢ 用户自定义的 Mapper 要继承自己的父类
➢ Mapper 的输入数据是 KV 对的形式 (KV 的类型可自定义 )
➢ Mapper 中的业务逻辑写在 map () 方法中
➢ Mapper 的输出数据是 KV 对的形式 (KV 的类型可自定义 )
➢ map () 方法 (MapTask 进程 ) 对每一个 <K.V> 调用一次
package com.nefu.mapreducer.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordcountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {private Text outK=new Text();private IntWritable outV=new IntWritable(1);@Overrideprotected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {String line=value.toString();String[] words=line.split(" ");for(String word:words){//封装outK.set(word);//写出context.write(outK,outV);}}
}
( 2 ) Reducer 阶段
➢ 用户自定义的 Reducer 要继承自己的父类
➢ Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV
➢ Reducer 的业务逻辑写在 reduce() 方法中
➢ ReduceTask 进程对每一组相同 k 的 <k,v> 组调用一 次 reduce () 方法,迭代
器类型
package com.nefu.mapreducer.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordcountReducer extends Reducer<Text,IntWritable,Text, IntWritable> {private IntWritable outV=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum=0;for(IntWritable value:values){sum=sum+value.get();}outV.set(sum);context.write(key,outV);}
}
( 3 ) Driver 阶段
相当于 YARN 集群的客户端,用于提交我们整个程序到 YARN 集群,提交的是
封装了 MapReduce 程序相关运行参数的 job 对象
package com.nefu.mapreducer.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordcountDriver {public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {//获取jobConfiguration conf=new Configuration();Job job=Job.getInstance(conf);//设置jar包job.setJarByClass(WordcountDriver.class);job.setMapperClass(WordcountMapper.class);job.setReducerClass(WordcountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job,new Path("D:\\cluster\\mapreduce.txt"));FileOutputFormat.setOutputPath(job,new Path("D:\\cluster\\partion"));boolean result=job.waitForCompletion(true);System.exit(result?0:1);}
}
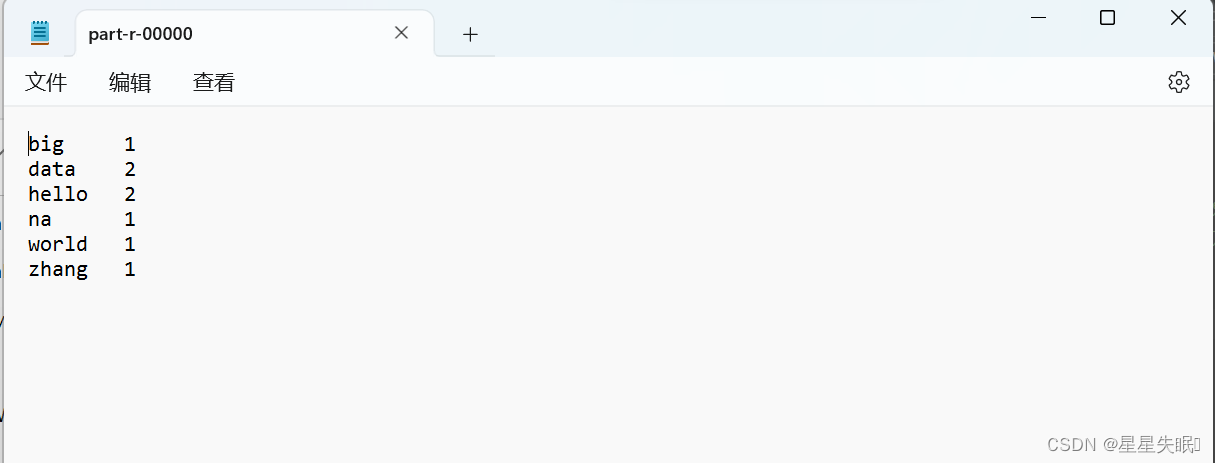
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>

这篇关于WordCount 源码解析 Mapper,Reducer,Driver的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






