本文主要是介绍MSE,MAE和CE的区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MSE和MAE的区别
异常值
MSE对异常值敏感,因为它的Cost是平方的,所以异常值的loss会非常大,下面的公式中y表示标注,a表示网络预测值。
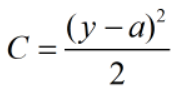
MAE对异常之不敏感,
![]()
不妨设拟合函数为常数,那么MSE就相当于所有数据的均值(列出loss对c求导即可),而MAE相当于所有数据的中位数,所以会对异常值不敏感。
优化效率
MAE不可导而且所有的导数的绝对值都相同,优化时无法确定更新速度,
MSE可导,有closed-form解,只需要令偏导数为0即可。
如何选择
因为MSE对异常值敏感,
1. 如果想要检测异常值则使用MSE,比如裂缝分割,缺陷分割。
2. 如果想学习一个分类预测模型则建议使用MAE,或者先进行异常值处理再使用MSE。
MSE和CE的区别
1.为什么MSE不适合分类问题?
首先列出MSE的公式,并对W和b求导数。
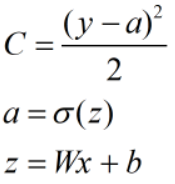
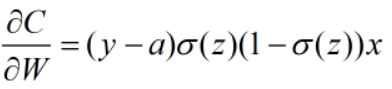
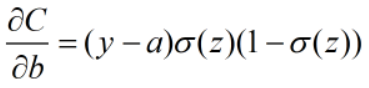
导数中有(y-a)和x当出现异常值的时候很可能出现梯度爆炸的情况,而且MSE中采用了sigmoid激活函数,所以肯定带有sigmoid激活函数的一些弊端。
由上述公式可以看出,在使用MSE时,w、b的梯度均与sigmoid函数对z的偏导有关系,而sigmoid函数的偏导在自变量非常大或者非常小时,偏导数
的值接近于零,这将导致w、b的梯度将不会变化,也就是出现所谓的梯度消失现象。
2. 再列出交叉熵的损失函数,并对W和b求导数。
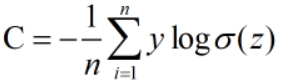
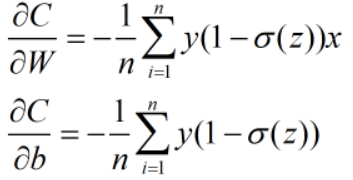
而使用cross-entropy时,w、b的梯度就不会出现上述的情况。
2.交叉熵不适用于回归问题
当MSE和交叉熵同时应用到多分类场景下时,(标签的值为1时表示属于此分类,标签值为0时表示不属于此分类),MSE对于
每一个输出的结果都非常看重,而交叉熵只对正确分类的结果看重。例如:在一个三分类模型中,模型的输出结果为(a,b,c),
而真实的输出结果为(1,0,0)。
从上述的公式可以看出,交叉熵的损失函数只和分类正确的预测结果有关系,而MSE的损失函数还和错误的分类有关系,
该分类函数除了让正确的分类尽量变大,还会让错误的分类变小,但实际在分类问题中这个调整是没有必要的。但是对
于回归问题来说,这样的考虑就显得很重要了。所以,回归问题熵使用交叉上并不合适。
这篇关于MSE,MAE和CE的区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





