本文主要是介绍数据结构与算法(六)分支限界法(Java),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、简介
- 1.1 定义
- 1.2 知识回顾
- 1.3 两种解空间树
- 1.4 三种分支限界法
- 1.5 回溯法与分支线定法对比
- 1.6 使用步骤
- 二、经典示例:0-1背包问题
- 2.1 题目
- 2.2 分析
- 1)暴力枚举
- 2)分支限界法
- 2.3 代码实现
- 1)实现广度优先策略遍历
- 2)实现限界函数来剪枝
一、简介
1.1 定义
分支限界法 是使用 广度优先策略,依次生成 扩展节点 上的所有分支。就是 把问题的可行解展开,再由各个分支寻找最佳解。
分支限界法 与 回溯法 类似,都是 递归 + 剪枝,区别在于回溯法使用的是深度优先策略,而分支限界法使用的是广度优先策略。
1.2 知识回顾
- 扩展结点: 一个 正在生成儿子 的结点,称为扩展结点。
- 活结点: 一个 自身已生成但其儿子还没有全部生成 的结点,称为活结点。
- 死结点: 一个 所有儿子已经全部生成 的结点,称为死结点。
深度优先策略:
- 如果对一个扩展结点 R,一旦生成了它的一个儿子 C,就把 C 当作新的扩展结点。
- 在完成对子树 C(以 C 为根的子树)的穷尽搜索之后,将 R 重新变成扩展结点,继续生成 R 的下一个儿子(如果存在)。
广度优先策略:
- 在一个扩展结点变成死结点之前,它一直是扩展结点。
剪枝函数:
剪枝函数:当某个顶点没有希望,则其所在的树枝可以减去。
剪枝函数一般有两种:
- 约束函数: 剪去不满足约束条件的路径。
- 限界函数: 减去不能得到最优解的路径。
1.3 两种解空间树
子集树(Subset Trees):
- 当所给问题是 从 n 个元素的集合中找出满足某种性质的子集 时,相应的解空间树称为
子集树。
若 Sn 表示 n 结点子树的数量,在子集树中,|S0| = |S1| = ... = |Sn-1| = c,即每个结点有相同数目的子树,通常情况下 c = 2,所以子树中共有 2^n 个叶子结点。因此,遍历子集树的时间复杂度为 O(2^n)。
排列树(Permutation Trees):
- 当所给问题是 确定 n 个元素满足某种性质的排列 时,相应的解空间树称为
排列树。
若 Sn 表示 n 结点子树的数量,在排列树中,通常情况下 |S0| = n, |S1| = n-1, ..., |Sn-1| = 1。所以,排列树中共有 n! 个叶子结点。因此,遍历排列树的时间复杂度为 O(n!)。
1.4 三种分支限界法
不同于回溯法,在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有儿子结点,通过 剪枝函数 将导致不可行解或非最优解的儿子结点舍弃,其余 儿子结点被加入活结点表中。
然后,从 活结点表 中取下一结点成为当前扩展结点,并重复上述结点扩展过程。这个 过程一直持续到 找到所需解 或 活结点表为空 为止。
根据活结点表的形成方式不同分为 三种分支限界法:
FIFO分支限界法:活结点表是 队列,按照队列先进先出(FIFO)原则选取下一个结点为扩展结点。LIFO分支限界法:活结点表是 堆栈,按照堆栈先今后出(LIFO)原则选取下一个结点为扩展结点。LC分支限界法:活结点是 优先权队列(Low Cost),按照优先队列中规定的优先权选取具有最高优先级的活结点成为新的扩展结点。- 结点优先权: 在其分支下搜索一个答案状态需要花费的代价越小,优先级越高。
1.5 回溯法与分支线定法对比
| 算法名称 | 对解空间树的搜索方式 | 存储结点的常用数据结构 | 结点存储特性 | 求解目标 | 空间复杂度 |
|---|---|---|---|---|---|
回溯法 | 深度优先搜索(DFS) | 递归; 非递归时使用堆栈 | 活结点的所有可行子结点被遍历后才被从栈中弹出(结点可能多次成为扩展结点)。 | 找出解空间树中满足约束条件的所有解。 | 子集树:O(n)排列树: O(n) |
分支限界法 | 广度优先搜索(BFS) 最小消耗优先搜索(LC) | 队列;堆栈、优先队列 | 每个活结点只有一次成为扩展结点的机会。 | 找出满足约束条件的一个解,或在满足约束条件的解中找出某种意义下的最优解。 | 子集树:O(2^n)排列树: O(n!) |
1.6 使用步骤
- 首先 确定一个合理的限界函数,并 根据限界函数确定目标函数的界;
- 然后 按照广度优先策略搜索问题的解空间树;
- 在扩展结点处,生成所有儿子结点,估算所有儿子结点对目标函数的可能取值,舍弃不可能通向最优解的结点(剪枝),将其余结点加入到活结点表(队列/栈)中;
- 在当前活结点表中,依据相应的分支线定法(FIFO、LIFO、LC),从当前活结点表中选择一个结点作为扩展结点;
- 重复 4~3 步,直到 找到所需的解 或 活结点表为空。
二、经典示例:0-1背包问题
2.1 题目
假定有N=4件商品,分别用A、B、C、D表示。每件商品的重量分别为 3kg、2kg、5kg和4kg,对应的价值分别为 66元、40元、95元和40元。现有一个背包,可以容纳的总重量位 9kg,问:如何挑选商品,使得背包里商品的 总价值最大?
2.2 分析
0-1背包问题,实际上就是排列组合的问题。
1)暴力枚举
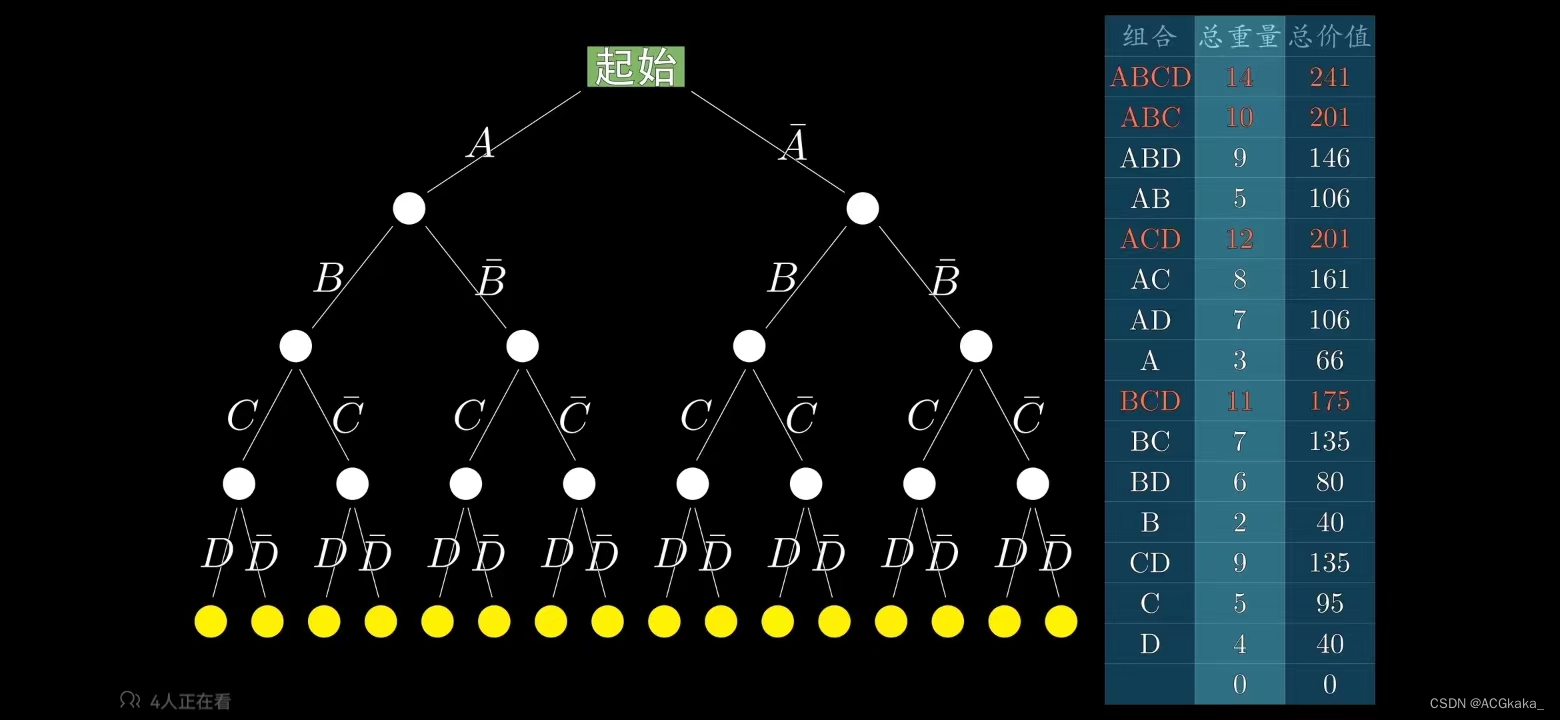
假如我们用A表示物品A存在;A(上划线)表示物品A不存在。暴力枚举所有可能的情况如下:
最优解: A 物品+ C 物品 = 161 价值
2)分支限界法
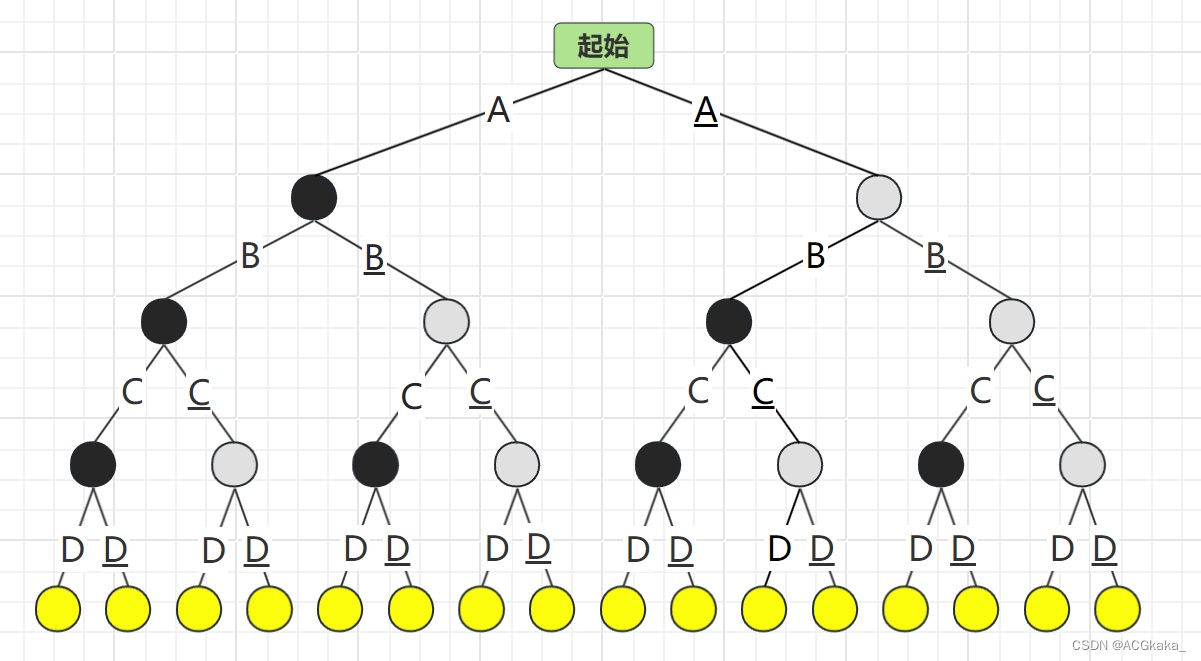
首先根据 价值/重量 进行从大到小进行排序,排序结果如下:
- 重量:3,价值:66,每份重量价值:22;
- 重量:2,价值:40,每份重量价值:20;
- 重量:5,价值:95,每份重量价值:19;
- 重量:4,价值:40,每份重量价值:10;
假如我们用A表示物品A存在;A(下划线)表示物品A不存在。解空间树 如下:
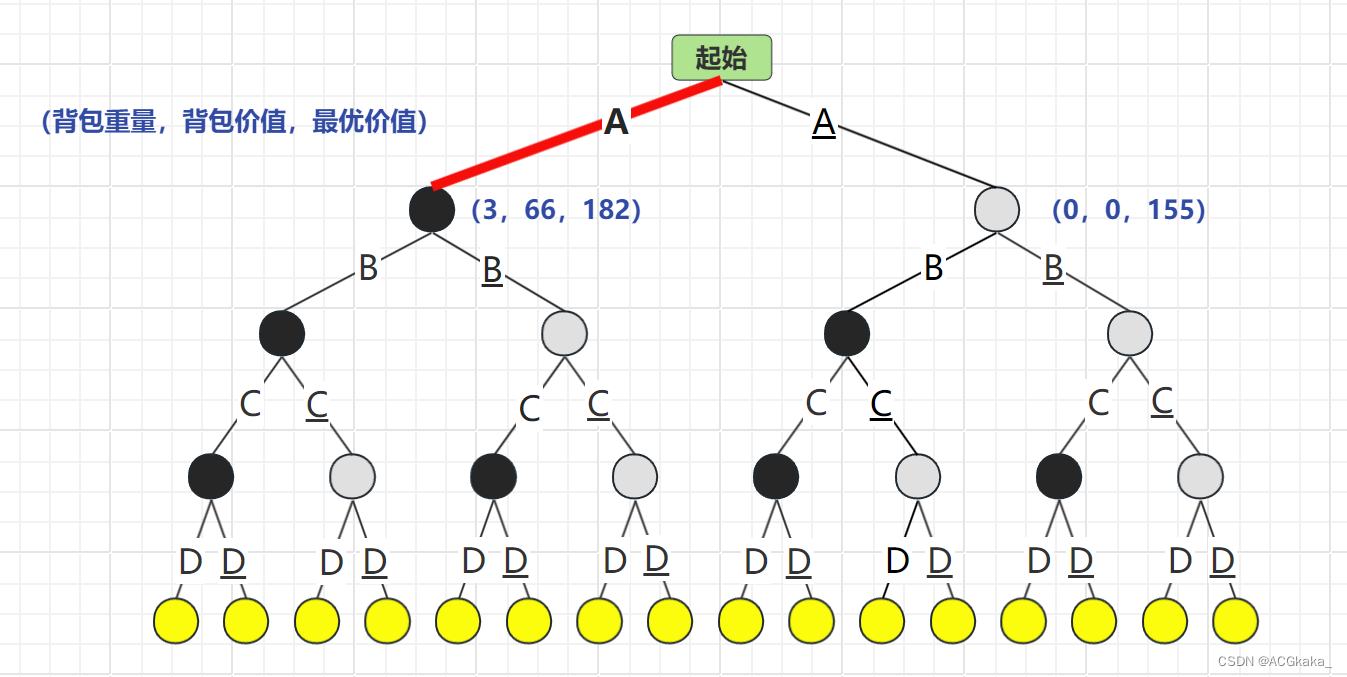
首先根据 A 物品的存在情况进行计算,A存在时最优价值为182,A不存在时最优价值为155。选择 最优价值更高的情况:A结点。
物品列表:A
背包价值:
66最优队列: A(182)> A(155)
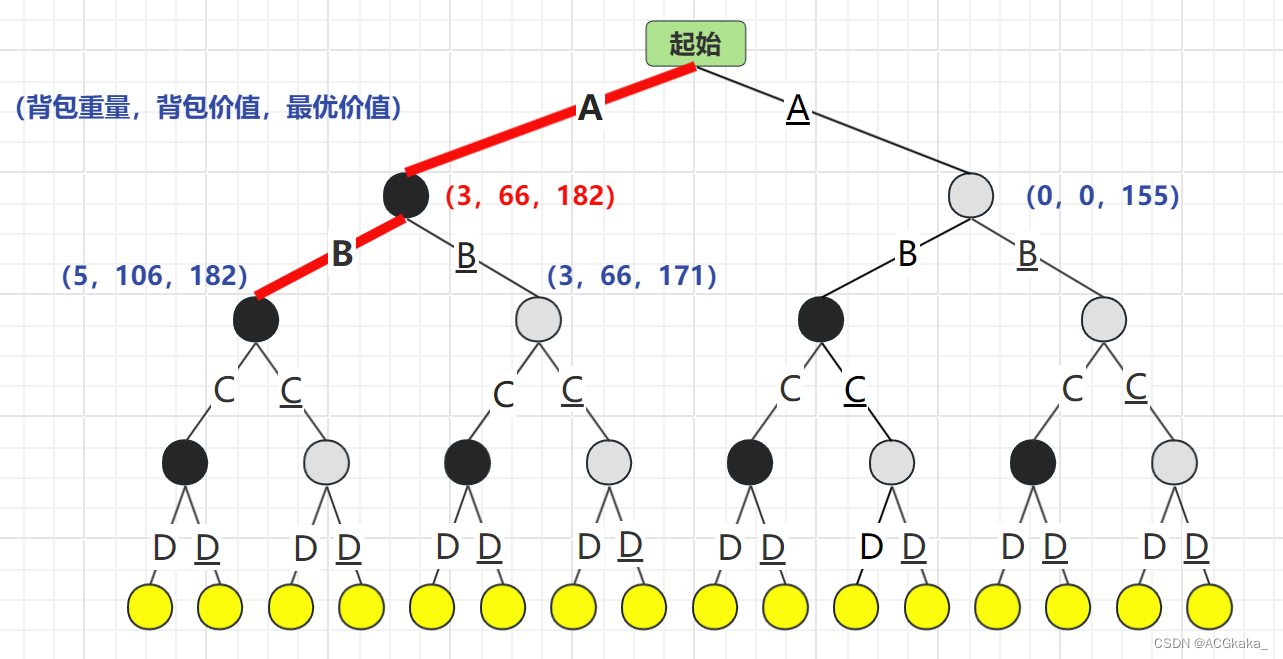
弹出 A 结点,再根据 B 物品的存在情况进行计算,B存在时最优价值为182,B不存在时最优价值为171。选择 最优价值更高的情况:B结点。
物品列表:A、B
背包价值:
106最优队列: B(182)> B(171)> A(155)
弹出 B 结点,再根据 C 物品的存在情况进行计算,C存在时超重×,C不存在时最优价值为146。选择 最优价值更高的情况:B结点。
物品列表:A
背包价值:
66最优队列: B(171)> A(155)> C(146)
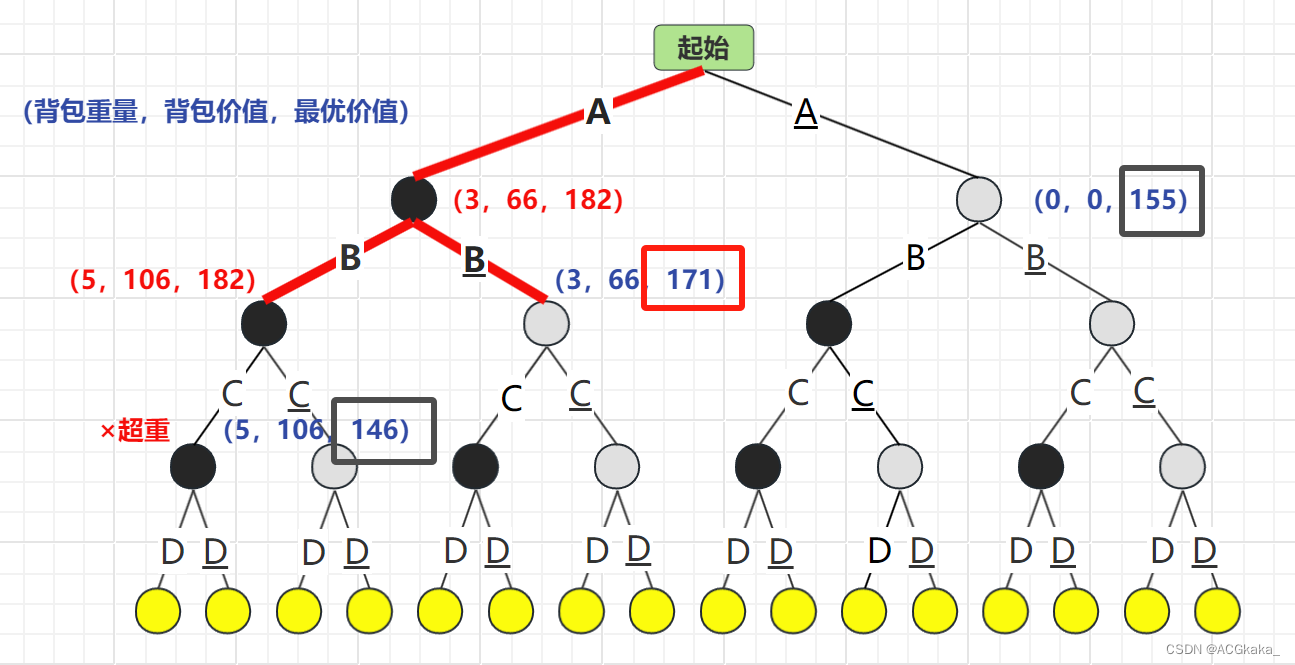
弹出 B 结点,再根据 C 物品的存在情况进行计算,C存在时最优价值为171,C不存在时最优价值为106,由于 106 不大于已有最大价值 161,舍弃。选择 最优价值更高的情况:C结点。
物品列表:A、C
背包价值:161
最优队列: C(171)> A(155)> C(146)
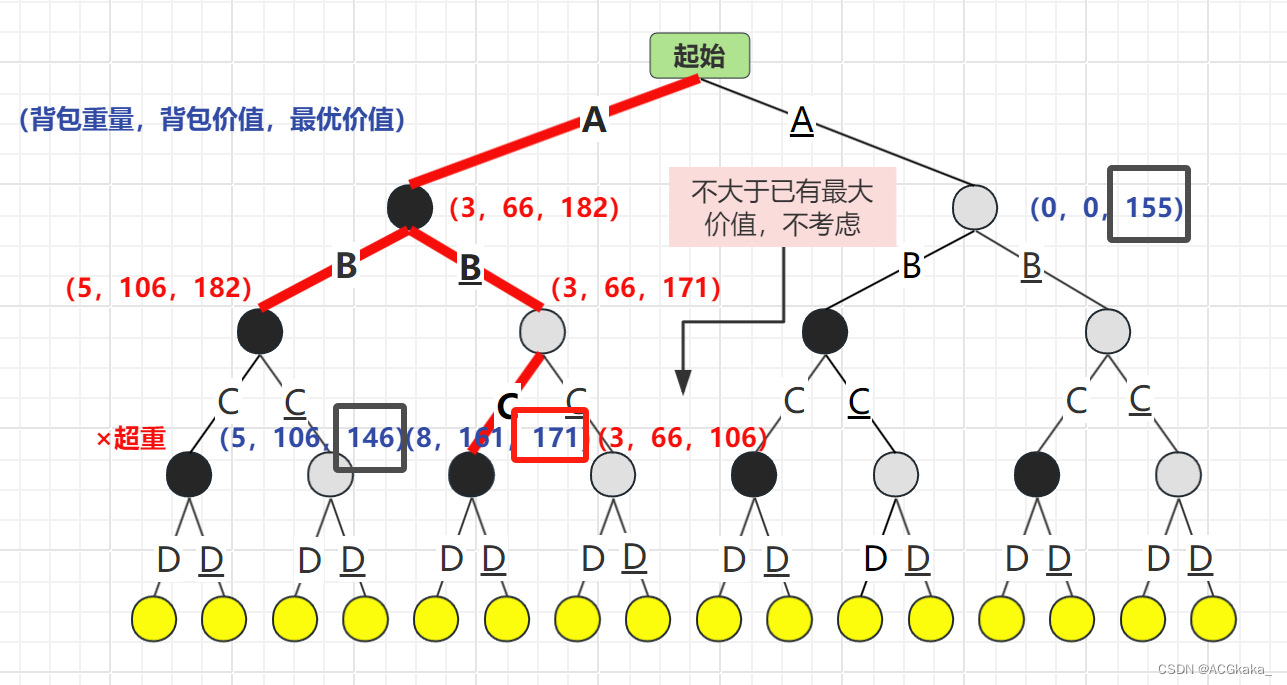
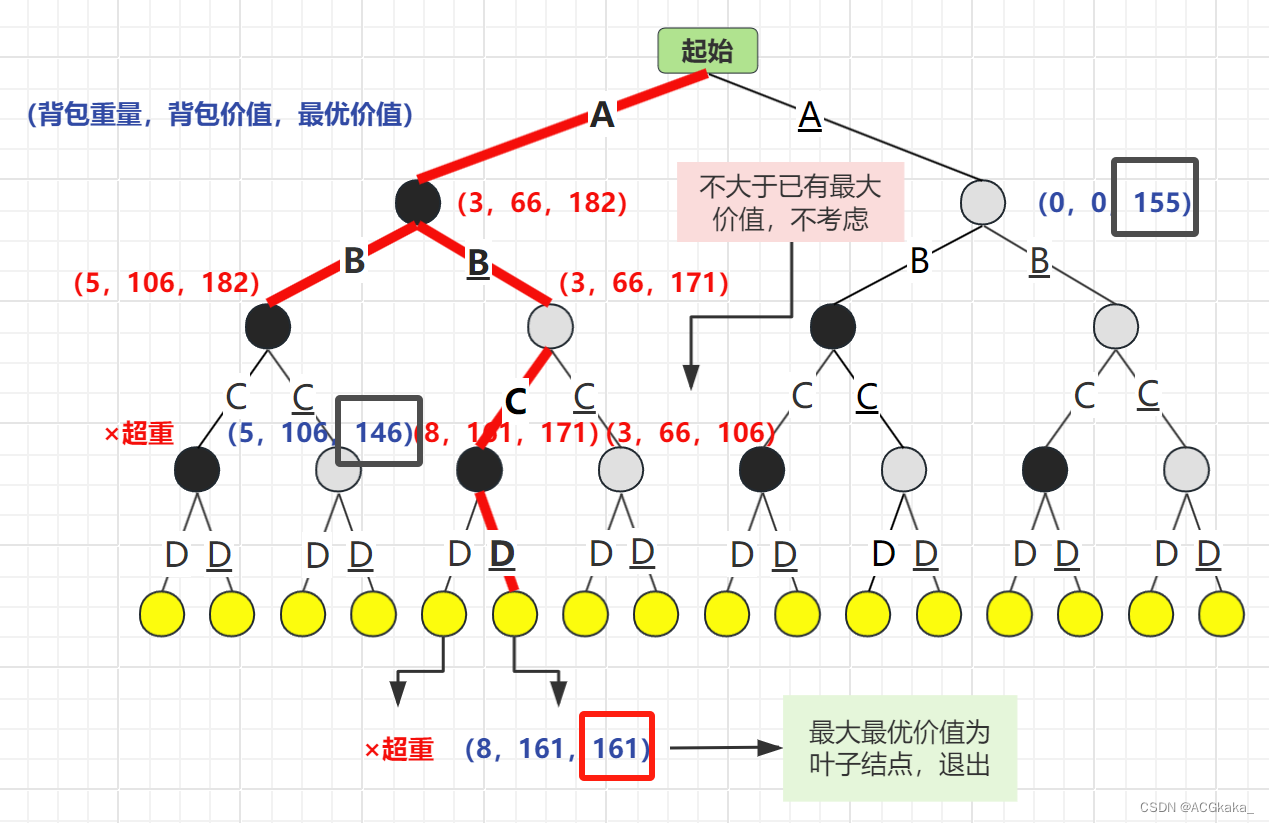
弹出 C 结点,再根据 D 物品的存在情况进行计算,D存在时超重×,D不存在时最优价值为161。由于此结点已为叶子结点,退出循环。
物品列表:A、C
背包价值:161
2.3 代码实现
为了方便理解,这里分两步实现:
- 实现广度优先策略遍历;
- 实现限界函数来剪枝。
1)实现广度优先策略遍历
public static void main(String[] args) {Solution solution = new Solution();int[][] arr1 = {{3,66},{2,40},{5,95},{4,40}};long start1 = System.currentTimeMillis();long start2 = System.nanoTime();// 执行程序int result = solution.knapsack(arr1, 9);long end1 = System.currentTimeMillis();long end2 = System.nanoTime();System.out.println(result);System.out.println("耗时:" + (end1 - start1) + " ms," + (end2 - start2) + " ns");
}public int knapsack(int[][] nums, int capacity) {Node rootNode = new Node(0, 0, 0);Queue<Node> queue = new ArrayDeque<>();queue.add(rootNode);int maxValue = 0;while (!queue.isEmpty()) {Node node = queue.poll();if (node.index >= nums.length) {break;}// 左节点:放入背包if (node.bagWeight + nums[node.index][0] <= capacity) {Node newLeftNode = new Node(node.index + 1, node.bagWeight + nums[node.index][0], node.bagValue + nums[node.index][1]);queue.add(newLeftNode);maxValue = Math.max(maxValue, newLeftNode.bagValue);}// 右节点:不放入背包Node newRightNode = new Node(node.index + 1, node.bagWeight, node.bagValue);queue.add(newRightNode);}return maxValue;
}static class Node {/*** 索引(第几个物品)*/private int index;/*** 背包容量*/private int bagWeight;/*** 背包价值*/private int bagValue;public Node(int index, int bagWeight, int bagValue) {this.index = index;this.bagWeight = bagWeight;this.bagValue = bagValue;}
}
2)实现限界函数来剪枝
public static void main(String[] args) {Solution solution = new Solution();int[][] arr1 = {{3,66},{2,40},{5,95},{4,40}};long start1 = System.currentTimeMillis();long start2 = System.nanoTime();// 执行程序int result = solution.knapsack(arr1, 9);long end1 = System.currentTimeMillis();long end2 = System.nanoTime();System.out.println(result);System.out.println("耗时:" + (end1 - start1) + " ms," + (end2 - start2) + " ns");
}public int knapsack(int[][] nums, int capacity) {// 由于使用了贪心算法,需要先进行排序Arrays.sort(nums, Comparator.comparingDouble(o -> -1.0 * o[1] / o[0]));Node rootNode = new Node(0, 0, 0);// 优先队列(贪心算法,按照最优价值排序)PriorityQueue<Node> queue = new PriorityQueue<>();queue.add(rootNode);int maxValue = 0;// 遍历,直到最大最优价值为某一叶子结点while (queue.size() > 0 && queue.peek().index < nums.length) {Node node = queue.poll();// 左节点:放入背包Node newLeftNode = new Node(node.index + 1, node.bagWeight + nums[node.index][0], node.bagValue + nums[node.index][1]);int newLeftUpBound = newLeftNode.getUpBound(nums, capacity);if (newLeftUpBound >= maxValue && newLeftNode.bagWeight <= capacity) {queue.add(newLeftNode);maxValue = Math.max(maxValue, newLeftNode.bagValue);}// 右节点:不放入背包Node newRightNode = new Node(node.index + 1, node.bagWeight, node.bagValue);int newRightUpBound = newRightNode.getUpBound(nums, capacity);if (newRightUpBound >= maxValue) {queue.add(newRightNode);}}return maxValue;
}static class Node implements Comparable<Node> {/*** 索引(例:第 1个物品索引为 1)*/private final int index;/*** 背包容量*/private final int bagWeight;/*** 背包价值*/private final int bagValue;/*** 背包最优价值(上界)*/private int upBound;public Node(int index, int bagWeight, int bagValue) {this.index = index;this.bagWeight = bagWeight;this.bagValue = bagValue;}public int getUpBound(int[][] nums, int capacity) {if (this.upBound > 0) {return this.upBound;}int newUpBound = this.bagValue;int bagLeft = capacity - bagWeight;int i = this.index;while (i < nums.length && bagLeft - nums[i][0] >= 0) {bagLeft -= nums[i][0];newUpBound += nums[i][1];i++;}// 背包未满,切割后放入if (i < nums.length) {newUpBound += 1.0 * bagLeft / nums[i][0] * nums[i][1];}return this.upBound = newUpBound;}@Overridepublic int compareTo(Node o) {// 倒叙return o.upBound - this.upBound;}
}
整理完毕,完结撒花~ 🌻
参考地址:
1.算法分析与设计:分支限界法,https://blog.csdn.net/weixin_44712386/article/details/105532881
2.(五) 分支限界算法,https://www.jianshu.com/p/538e7612f68d
3.【算法】四、分支限界法,https://blog.csdn.net/m0_64403412/article/details/130694294
4.单源最短路径问题——分支限界法(Java),https://zhuanlan.zhihu.com/p/601400758
5.java 0-1背包问题 动态规划、回溯法、分支限界,https://blog.csdn.net/Dl_MrE/article/details/119572322
6.分支限界法求解0/1背包问题动画演示,https://www.bilibili.com/video/BV1gb411G7FH/
这篇关于数据结构与算法(六)分支限界法(Java)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



