本文主要是介绍基于AIS数据的船舶密度计算与规律研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考文献:[1]陈晓. 基于AIS数据的船舶密度计算与规律研究[D].大连海事大学,2021.DOI:10.26989/d.cnki.gdlhu.2020.001129.
谢谢姐姐的文章!
网格化AIS数据
网格化 AIS 数据是处理和分析船舶轨迹数据的一种有效方法,特别是当涉及到密度计算和模式识别时。以下是网格化 AIS 数据的一些主要好处,以及一些使用 Python 实现这一过程的基本代码示例。
网格化 AIS 数据的好处
简化数据分析:
- 网格化可以将连续的地理空间数据简化为离散的单元,使得对船舶位置和运动的分析更加直观和易于处理。
便于计算密度和分布:
- 通过统计每个网格内的船舶数量,可以更容易地计算和可视化船舶密度分布。计算的不再是所有MMSI船舶各自的航行信息,那个既复杂,又不易计算某地区的船舶密度。
模式识别和趋势分析:
- 网格化数据有助于识别特定区域的流量模式、常用航道和潜在拥堵点。
时间序列分析:
- 通过跟踪船舶在各个网格中的停留时间,可以分析航行模式和时间上的变化。
降低数据复杂性:
- 网格化减少了数据的复杂性,使大规模数据集更易于管理和分析。
Python 代码示例
以下是一个简单的 Python 代码示例,展示如何将 AIS 数据网格化并计算每个网格中的船舶数量。
import pandas as pd
import numpy as np# 示例数据
data = {'MMSI': [123456789, 987654321, 123456789],'Timestamp': ['2023-01-01 00:00', '2023-01-01 01:00', '2023-01-01 02:00'],'Longitude': [-122.33, -122.34, -122.35],'Latitude': [37.39, 37.40, 37.41]
}
ais_data = pd.DataFrame(data)# 定义网格大小
grid_size = 0.01 # 假设每个网格的大小为0.01度# 网格化函数
def gridify(longitude, latitude, grid_size):return (np.floor(longitude / grid_size), np.floor(latitude / grid_size))# 应用网格化
ais_data['Grid'] = ais_data.apply(lambda row: gridify(row['Longitude'], row['Latitude'], grid_size), axis=1)# 计算每个网格中的船舶数量
grid_counts = ais_data['Grid'].value_counts()print(grid_counts)
这段代码首先定义了一个模拟的 AIS 数据集,然后使用一个简单的网格化函数将船舶的经纬度坐标映射到网格坐标上,并计算每个网格中的船舶数量。可以根据自己的数据集和需求调整网格大小和其他参数。
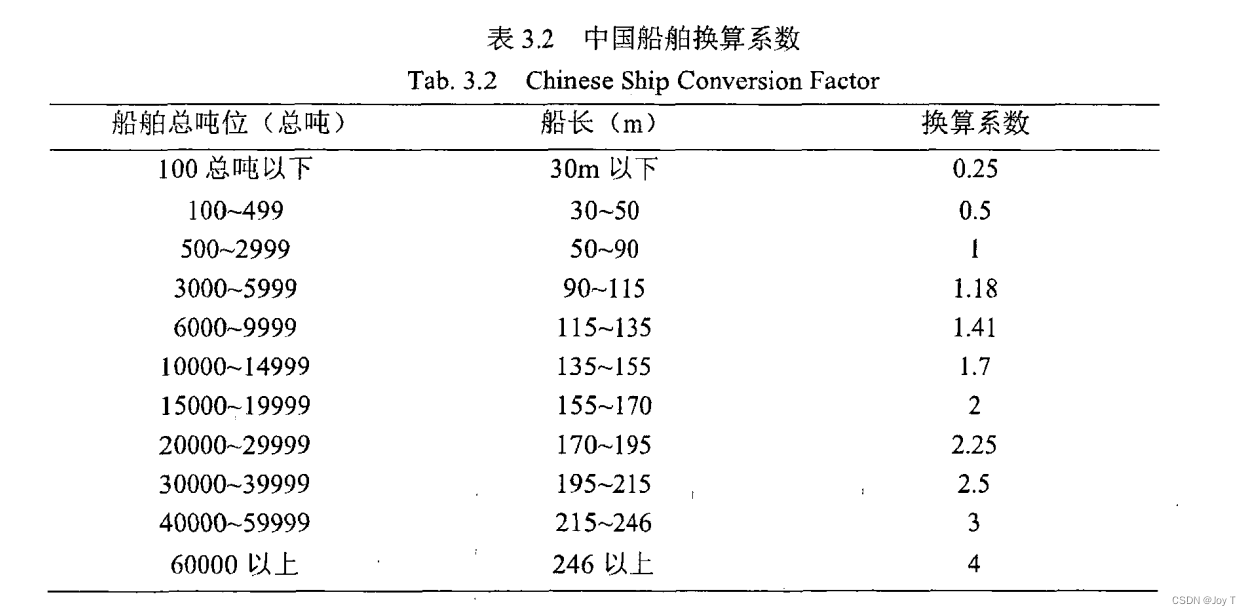
换算系数——考虑船舶大小
在考虑船舶尺度对交通安全的影响时,仅仅按照船舶的数量来计算密度可能不足以准确反映实际情况。因此,建立基于标准船尺寸的船舶密度计算模型是一种更为合理的方法。这种方法允许不同尺寸的船舶根据它们对空间的占用和潜在的安全风险被不同地权衡。
船舶密度计算模型
标准船尺寸定义:
- 将特定尺寸范围内的船舶(例如 50m-100m)定义为标准船尺寸。
- 这个尺寸范围代表了一种“平均”或“典型”的船舶大小,用于密度计算的基准。
换算系数:
- 对于小于或大于标准船尺寸的船舶,分配一个换算系数,以反映它们相对于标准船的大小。
- 例如,一个 200m 长的船可能被计算为两艘标准船,而一个 25m 长的船可能只计为半艘标准船。
船舶密度计算:
- 船舶密度不再简单地基于船舶数量,而是基于换算后的船舶数量进行计算。
- 这种方法更准确地反映了船舶对水域空间的占用和潜在的风险。
实际应用
在实际应用中,这种计算方法可以用于评估航道的拥挤程度、规划航线,以及制定海事安全政策。通过考虑船舶的实际尺寸和占用空间,可以更准确地评估特定水域的安全状况。
Python 代码示例
以下是一个基本的 Python 代码示例,演示如何根据船舶大小调整船舶数量来计算密度:
import pandas as pd# 示例数据
data = {'MMSI': [123456789, 987654321, 456789123],'ShipLength': [30, 80, 150] # 船舶长度,单位:米
}
ais_data = pd.DataFrame(data)# 定义标准船的大小范围
standard_ship_min = 50 # 最小长度
standard_ship_max = 100 # 最大长度# 计算换算系数
def calculate_conversion_factor(length):if length < standard_ship_min:return 0.5elif length > standard_ship_max:return 1.5else:return 1 # 标准船尺寸# 应用换算系数
ais_data['ConversionFactor'] = ais_data['ShipLength'].apply(calculate_conversion_factor)# 计算总的“标准船”数量
total_standard_ships = ais_data['ConversionFactor'].sum()
print("Total 'Standard Ships':", total_standard_ships)
AIS数据的定期广播
AIS(Automatic Identification System)系统定期广播船舶的动态信息(如位置、速度、航向)和静态信息(如船舶识别、类型、尺寸)。不同类型的信息具有不同的广播频率,如下图所示。这可能导致在某一特定瞬时时刻,数据库中不一定包含所有船舶的最新信息。
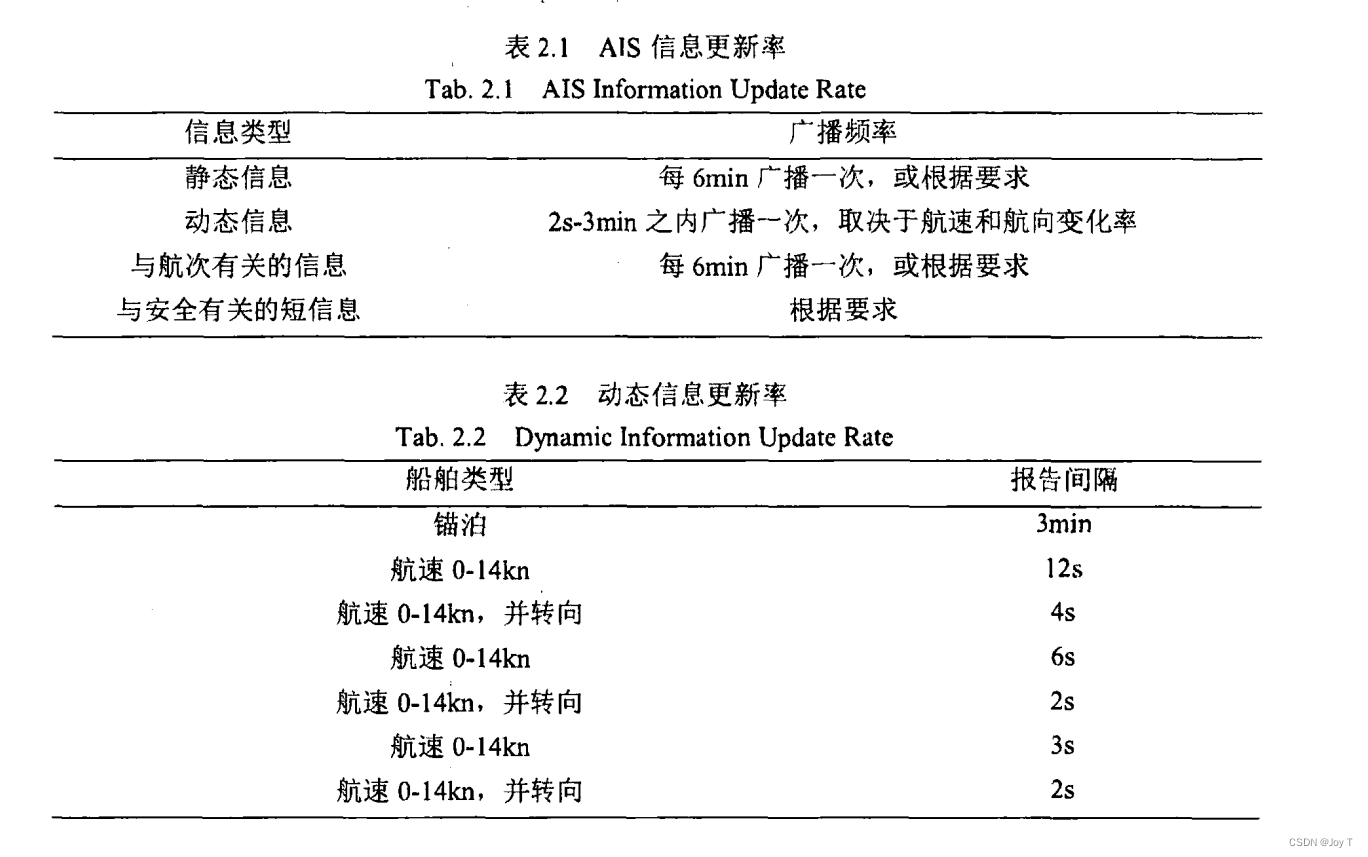
如果计算瞬时密度时,这一刻船舶的AIS信息还没接收到,那么可以利用矩估计选择近似整点时刻。由于最久的静态信息是6min间隔,故可设置前后6min的信息接受域,并在域中选择近似整点时刻,如下图所示:

这种方式的优点是:
-
提高数据的完整性:由于 AIS 数据可能不是实时更新,所以在一定时间范围内统计能够更全面地捕捉到该时刻附近的船舶情况。
-
增加计算的准确性:减少了由于 AIS 更新率不一致而导致的数据缺失或延迟,使得瞬时密度的计算更为准确。
-
适应不同类型的船舶和航速:不同类型的船舶和不同航速的船只可能有不同的 AIS 更新频率,通过扩展统计窗口可以更好地覆盖这些差异。
这种方法在进行航道交通分析、海上交通管理和航行安全评估等方面是非常实用的。它允许分析人员更准确地估计特定时刻或时间段内的船舶密度,从而为相关的决策提供支持。
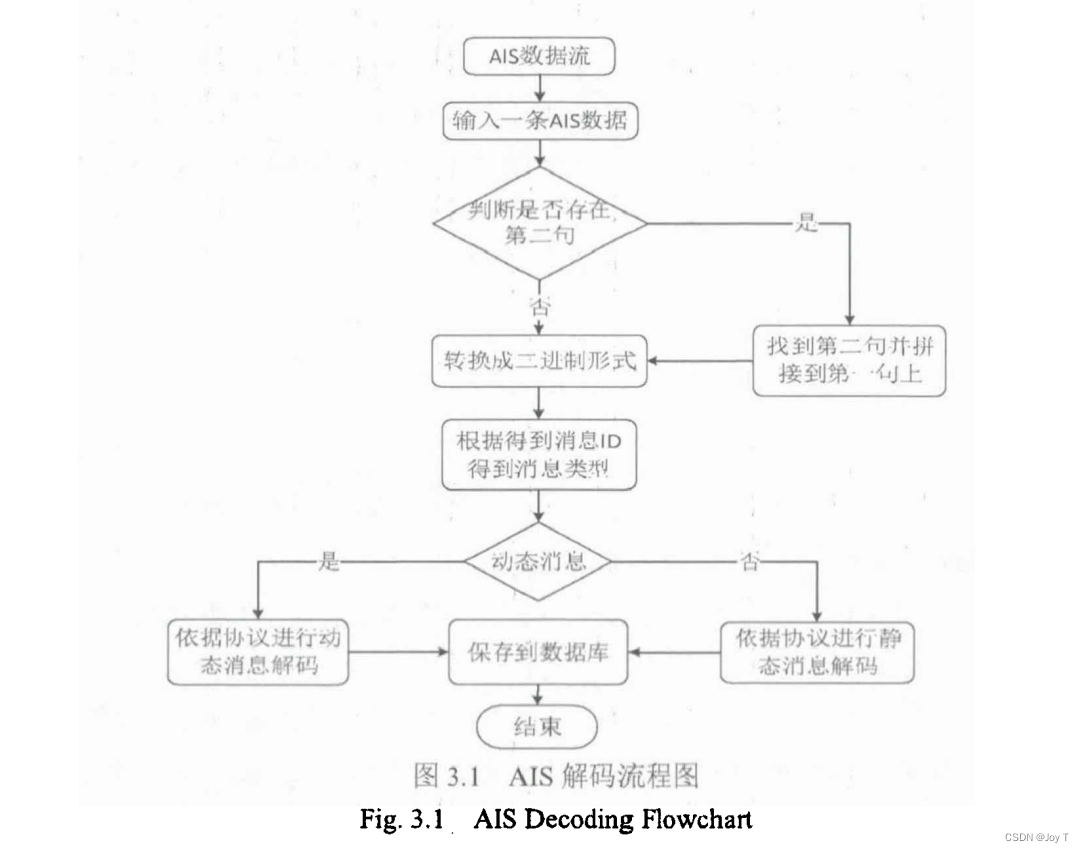
解码AIS数据
处理和解码 AIS 数据是一个涉及多个步骤的复杂过程。AIS 数据通常以 NMEA 0183 标准格式(一种海事通信协议)传输,这些数据包含了各种船舶信息,包括位置、航向、速度等。AIS 消息以特定格式编码,首先需要将这些编码的文本数据转换为二进制格式,然后根据相关协议(如 ITU-R M.1371 和 IEC 61162-2)解码以获取实际的信息。
以下是解码 AIS 数据的基本步骤:
1. 文本到二进制的转换
AIS 消息通常使用六位 ASCII 码表示。这种编码方式将标准 ASCII 码映射到六位二进制数。转换的基本步骤是将每个字符转换为其相应的六位二进制表示。
2. 根据 IEC 61162-2 协议解码
一旦文本数据转换为二进制形式,接下来就需要根据相应的协议解析这些二进制数据。这包括解析船舶的 MMSI、位置坐标、速度、航向等信息。
3. 实现解码
在 Python 中,这个过程可以通过编写自定义函数或使用已存在的库来实现。例如,libais 是一个流行的 Python 库,可以用于解码 AIS 消息。
Python 示例
以下是一个使用 libais 库来解码 AIS 消息的基本示例。需要先安装 libais 库。
import ais# 示例 AIS 消息
ais_message = '!AIVDM,1,1,,B,15N7p<PP00I=0B?4p4p@E=kP058j,0*2C'# 提取消息体和填充位
# msg_parts 是将 AIS 消息按逗号分割后得到的列表。
msg_parts = ais_message.split(',')
# msg_body 是这个列表的第六个元素,即实际的 AIS 数据部分。
msg_body = msg_parts[5]
# fill_bits 是消息中的填充位数,用于告诉解码器如何正确解析消息。
# 这个例子中填充位数为0,从0*2C中提取出来的
fill_bits = int(msg_parts[6].split('*')[0])# 解码 AIS 消息
decoded_message = ais.decode(msg_body, fill_bits)print(decoded_message)
结果如下:

然后根据相关规定,筛除不满足真实要求的AIS数据,规定如下:

这篇关于基于AIS数据的船舶密度计算与规律研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




