本文主要是介绍在linux上如何运用虚拟数据优化器VDO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本章主要介绍虚拟化数据优化器。
- 什么是虚拟数据优化器VDO
- 创建VDO设备以节约硬盘空间
16.1 了解什么是VDO
VDO全称是Virtual Data Optimize(虚拟数据优化),主要是为了节省硬盘空间。
现在假设有两个文件file1和 file2,大小都是10G。file1和 file2中包含了8G的相同数据,
如图16-1中的灰色部分。这个相同数据在硬盘中存储了两份,所以这两个文件占用的硬盘空
间是20G。
如果采用了VDO,效果如图16-2所示。
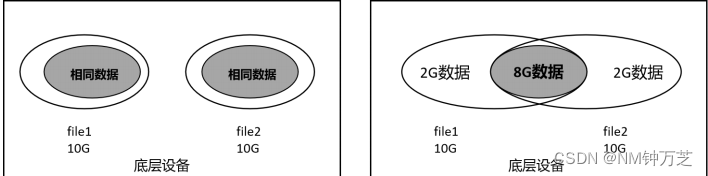
file1和 file2大小都是10G,两个文件中都有8G的相同数据。那么,这个相同数据在硬盘
中只存储一份,让filel和 file2共同使用。所以,最终在硬盘上占用的空间是12G,这样一个
20G大小的硬盘,完全可以存储大于20G的文件,主要看这些文件中到底有多少相同数据。
所以,VDO实现的效果是,多个文件中有相同数据,这个相同数据只存储一份,从而实现
节省硬盘空间的目的。
16.2 配置VDO
首先要安装VDO相关软件包(关于软件包的管理在第23章和第24章中有详细讲解),步骤
如下。
步骤①:挂载光盘,命令如下。
[root@pp ~]# mount /dev/cdrom /mnt/
mount: /mnt: WARNING: device write-protected, mounted read-only.
[root@pp ~]#
这里准备把光盘作为yum 源。
步骤②:编写repo文件,命令如下。
[root@pp ~]# cat /etc/yum.repos.d/aa.repo
[aa]
name=aa
baseurl=file:///mnt/AppStream
enabled=1
gpgcheck=0[bb]
name=bb
baseurl=file:///mnt/BaseOS
enabled=1
gpgcheck=0
[root@pp ~]#
步骤③:安装VDO,命令如下。
[root@pp ~]# yum -y install vdo kmod-kvdo
查看 VDO设备,命令如下。
[root@pp ~]# vdo list [root@pp ~]#
没有任何输出,说明现在还没有任何VDO设备。
因为相同数据只存储一份,大大地节省了存储空间,所以本来20G的磁盘空间现在存储
30G、40G、50G的数据是完全有可能的。
下面创建一个名称为vdo1、底层设备为/dev/sdc的VDO设备,逻辑大小为50G,命令如
下。
[root@pp ~]# vdo create --name vdo1 --device /dev/nvme0n2 --vdoLogicalSize 50G
Creating VDO vdo1The VDO volume can address 46 GB in 23 data slabs, each 2 GB.It can grow to address at most 16 TB of physical storage in 8192 slabs.If a larger maximum size might be needed, use bigger slabs.
Starting VDO vdo1
Starting compression on VDO vdo1
VDO instance 0 volume is ready at /dev/mapper/vdo1
[root@pp ~]#
上面提示的一堆信息不用管,最终能看到的是vdo1已经创建好了,可以通
过/dev/mapper/vdo1来使用。 再次查看有多少VDO设备,命令如下。
[root@pp ~]# vdo list
vdo1
[root@pp ~]#
格式化这个VDO设备,命令如下。
[root@pp ~]# mkfs.xfs -K /dev/mapper/vdo1
meta-data=/dev/mapper/vdo1 isize=512 agcount=4, agsize=3276800 blks= sectsz=4096 attr=2, projid32bit=1= crc=1 finobt=1, sparse=1, rmapbt=0= reflink=1
data = bsize=4096 blocks=13107200, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=6400, version=2= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@pp ~]#
这里-K(大写)的意思类似于Windows中的快速格式化。
把这个 VDO设备挂载到/vdo1目录上,命令如下。
[root@pp ~]# mkdir /vdo1
[root@pp ~]# mount /dev/mapper/vdo1 /vdo1/
[root@pp ~]#
如果希望能永久挂载,需要写入/etc/fstab中,命令如下。
[root@pp ~]# grep vdo /etc/fstab
/dev/mapper/vdo1 /vdo1 xfs defaults,_netdev 0 0
[root@pp ~]#
需要注意的是,这里一定要有_netdev选项,否则重启系统时,系统是启动不起来的。
查看vdo1的空间使用情况,命令如下。
[root@pp ~]# vdostats --hu
Device Size Used Available Use% Space saving%
/dev/mapper/vdo1 50.0G 4.0G 46.0G 8% 99%
[root@pp ~]#
这里自身就消耗了4G空间(Used那列),因为这里不存在文件,所以空间节省率为99%
(Space saving%那列)。
这篇关于在linux上如何运用虚拟数据优化器VDO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









