本文主要是介绍【由浅入深讨论HBase:自认全网最全最细】,你想了解的关于HBase知识,基本上都有,有需要的可以收藏当字典使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一 HBase简介
- 二 HBase表的数据模型
- 1 rowkey行键
- 2 Column Family列族
- 3 Column列
- 4 cell单元格
- 5 Timestamp时间戳
- 三 HBase整体架构
- 1 Client客户端
- 2 ZooKeeper集群
- 3 HMaster
- 4 HRegionServer
- 5 Region
- 四 HBase安装
- 1 安装准备
- 2 安装步骤
- 3 启动HBase集群
- 4 停止HBase集群
- 五 HBase shell 命令基本操作
- 1 进入HBase客户端命令操作界面
- 2 HBase表模型特点
- 3 HBase数据类型
- 4 HBase命令行操作
- 六 HBase的高级shell管理命令
- 1 status
- 2 whoami
- 3 list
- 4 count
- 5 describe
- 6 exists
- 7 is_enabled、is_disabled
- 8 alter
- 9 disable/enable
- 10 drop
- 11 truncate
- 七 Hive与HBase的集成
- 八 HBase客户端API操作
- 九 phoenix操作HBase
- 1 安装pheonix
- 1.1 下载pheonix
- 1.2 解压pheonix
- 1.3 整合phoenix到hbase
- 1.4 使用phoenix SQL命令行
- 1.4.1 创建表
- 1.4.2 编辑并导入数据
- 1.4.3 查询数据
- 2 Squirrel-sql 连接Phoenix
- 2.1 下载Squirrel-sql
- 2.2 设置Squirrel-sql 连接Phoenix
- 3 Phoenix 映射Hbase 表
- 3.1 视图映射
- 3.2 表映射
前言
各位小伙伴大家好,最近因为公司电脑固态硬盘坏掉和大院拆迁被迫搬家的事情,心情一直比较苦闷;在周末搬完家后,想着怎么写个专题类的文章跟各位小伙伴们一起在知识的海洋中遨游下,好好用知识让我们自己放松下,最终确认下来干一篇非常全面的HBase文章,大家可以一键三连加评论,有相关的意见和想法可以一起讨论学习。话不多说,直接开始我们今天的正题,让我们在HBase海洋中尽情遨游吧:
一 HBase简介
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
HBase与mysql、oralce、db2、sqlserver等关系型数据库不同,它是一个NoSQL数据库(非关系型数据库)
HBase的表模型与关系型数据库的表模型不同:
HBase与mysql、oralce、db2、sqlserver等关系型数据库不同,它是一个NoSQL数据库(非关系型数据库)
HBase的表模型与关系型数据库的表模型不同:
HBase的表没有固定的字段定义;
HBase的表中每行存储的都是一些key-value对;
Hbase的表中有列族的划分,用户可以指定将哪些kv插入哪个列族;
Hbase的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中;
Hbase的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复;
Hbase中的数据,包含行键,包含key,包含value,都是byte[ ]类型,hbase不负责为用户维护数据类型;
HBASE对事务的支持很差;
HBASE相比于其他nosql数据库(mongodb、redis、cassendra、hazelcast)的特点:
Hbase的表数据存储在HDFS文件系统中,所以,hbase具备如下特性:
海量存储
列式存储
数据存储的安全性可靠性极高
支持高并发
存储容量可以线性扩展
二 HBase表的数据模型

1 rowkey行键
table的主键,table中的记录按照rowkey 的字典序进行排序
Row key行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes)
2 Column Family列族
列族或列簇
HBase表中的每个列,都归属与某个列族
列族是表的schema的一部分(而列不是),即建表时至少指定一个列族
比如创建一张表,名为user,有两个列族,分别是info和data,建表语句create ‘user’, ‘info’, ‘data’
3 Column列
列肯定是表的某一列族下的一个列,用列族名:列名表示,如info列族下的name列,表示为info:name
属于某一个ColumnFamily,类似于我们mysql当中创建的具体的列
4 cell单元格
指定row key行键、列族、列,可以确定的一个cell单元格
cell中的数据是没有类型的,全部是以字节数组进行存储

5 Timestamp时间戳
可以对表中的Cell多次赋值,每次赋值操作时的时间戳timestamp,可看成Cell值的版本号version number;即一个Cell可以有多个版本的值
三 HBase整体架构
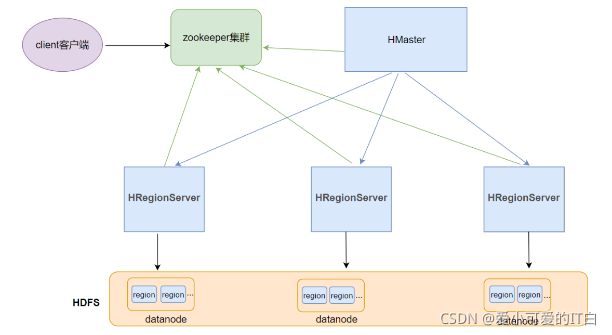
1 Client客户端
Client是操作HBase集群的入口;
对于管理类的操作,如表的增、删、改操纵,Client通过RPC与HMaster通信完成;
对于表数据的读写操作,Client通过RPC与RegionServer交互,读写数据
Client类型:
HBase shell
Java编程接口
Thrift、Avro、Rest等等
2 ZooKeeper集群
作用:
实现了HMaster的高可用,多HMaster间进行主备选举;
保存了HBase的元数据信息meta表,提供了HBase表中region的寻址入口的线索数据;
对HMaster和HRegionServer实现了监控;
3 HMaster
HBase集群也是主从架构,HMaster是主的角色,是老大
主要负责Table表和Region的相关管理工作:
关于Table
管理Client对Table的增删改的操作
关于Region
在Region分裂后,负责新Region分配到指定的HRegionServer上
管理HRegionServer间的负载均衡,迁移region分布
当HRegionServer宕机后,负责其上的region的迁移
4 HRegionServer
HBase集群中从的角色,是小弟
作用:
响应客户端的读写数据请求
负责管理一系列的Region
切分在运行过程中变大的region
5 Region
HBase集群中分布式存储的最小单元
一个Region对应一个Table表的部分数据
HBase使用,主要有两种形式:①命令;②Java编程
四 HBase安装
HBASE是一个分布式系统
其中有一个管理角色:HMaster(一般2台,一台active,一台backup)
其他的数据节点角色:HRegionServer(很多台,看数据量)
1 安装准备
需要先有一个java环境
首先,要有一个HDFS集群,并正常运行;regionserver应该跟hdfs中的datanode在一起
其次,还需要一个zookeeper集群,并正常运行,然后,安装HBase
角色分配如下:
Hdp01: namenode datanode regionserver hmaster zookeeper
Hdp02: datanode regionserver zookeeper
Hdp03: datanode regionserver zookeeper
2 安装步骤
解压HBase安装包
修改hbase-env.sh
export JAVA_HOME=/root/apps/jdk1.7.0_67
export HBASE_MANAGES_ZK=false
修改hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://hdp01:9000/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>hdp01:2181,hdp02:2181,hdp03:2181</value></property>
</configuration>
修改 regionservers
hdp01
hdp02
hdp03
3 启动HBase集群
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/start-hbase.sh
启动完后,还可以在集群中找任意一台机器启动一个备用的master
bin/hbase-daemon.sh start master
新启的这个master会处于backup状态
4 停止HBase集群
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/stop-hbase.sh
五 HBase shell 命令基本操作
1 进入HBase客户端命令操作界面
node01执行以下命令,进入HBase的shell客户端
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/hbase shell

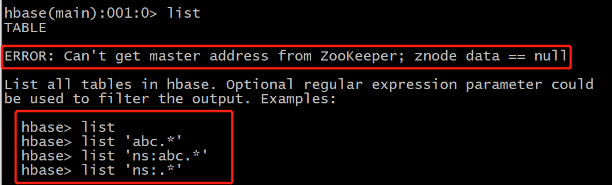
如果出现下图所示情况,说明HBase未正常启动
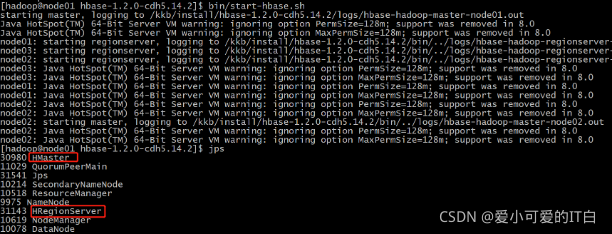
以下为正常启动页面,并且有相关进程
① list查看当前数据库中有哪些表

② 查看HBase集群状态

③ 查看HBase集群版本

ps:NameSpace操作
HBase系统默认定义了两个缺省的namespace
hbase:系统内建表,包括namespace和meta表
default:用户建表时未指定namespace的表都创建在此创建:create_namespace 'lzc'
删除:drop_namespace 'lzc'
查看:describe_namespace 'lzc'
列出所有:list_namespace
在namespace下创建表:create 'lzc:user_info','id','name','age'
查看namespace下的表 :list_namespace_tables 'lzc'
2 HBase表模型特点

1.一个表,有表名
2.一个表可以分为多个列族(不同列族的数据会存储在不同文件中)
3.表中的每一行有一个“行键rowkey”,而且行键在表中不能重复
4.表中的每一对kv数据称作一个cell
5.hbase可以对数据存储多个历史版本(历史版本数量可配置)
6.整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识),不同region的数据也存储在不同文件中

7.hbase会对插入的数据按顺序存储:
要点一:首先会按行键排序
要点二:同一行里面的kv会按列族排序,再按k排序
3 HBase数据类型
hbase中只支持byte[]
此处的byte[] 包括了:rowkey,key,value,列族名,表名
4 HBase命令行操作
| 名称 | 命令表达式 |
|---|---|
| 创建表 | create ‘表名’, ‘列族名1’,‘列族名2’,‘列族名N’ |
| 查看所有表 | list |
| 描述表 | describe ‘表名’ |
| 判断表存在 | exists ‘表名’ |
| 判断是否禁用启用表 | is_enabled ‘表名’ is_disabled ‘表名’ |
| 添加记录 | put ‘表名’, ‘rowKey’, ‘列族 : 列‘ , ‘值’ |
| 查看记录rowkey下的所有数据 | get ‘表名’ , ‘rowKey’ |
| 查看表中的记录总数 | count ‘表名’ |
| 获取某个列族 | get ‘表名’,‘rowkey’,‘列族’ |
| 获取某个列族的某个列 | get ‘表名’,‘rowkey’,'列族:列’ |
| 删除记录 | delete ‘表名’ ,‘行名’ , ‘列族:列’ |
| 删除整行 | deleteall ‘表名’,‘rowkey’ |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除 第一步 disable ‘表名’ ,第二步 drop ‘表名’ |
| 清空表 | truncate ‘表名’ |
| 查看所有记录 | scan “表名” |
| 查看某个表某个列中所有数据 | scan “表名” , {COLUMNS=>‘列族名:列名’} |
| 更新记录 | 就是重写一遍,进行覆盖,hbase没有修改,都是追加 |
① help 帮助命令
hbase(main):005:0> help
查看具体命令的帮助信息
hbase(main):006:0> help ‘create’
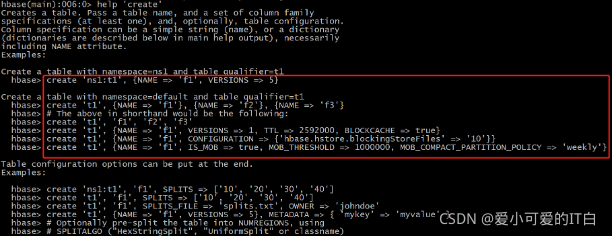
② create 创建表
创建user表,包含info、data两个列族
使用create命令
hbase(main):008:0> create ‘user’, ‘info’, ‘data’
0 row(s) in 1.3080 seconds
或者
=> Hbase::Table - user
hbase(main):009:0> create ‘user’,{NAME => ‘info’, VERSIONS => ‘3’},{NAME => ‘data’}
ERROR: Table already exists: user!

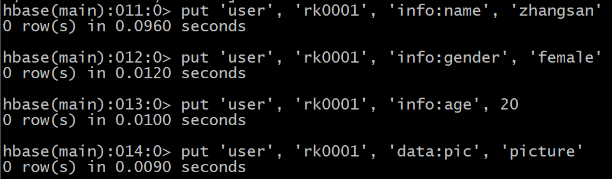
③ put 插入数据操作
向表中插入数据
使用put命令
向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
HBase(main):011:0> put ‘user’, ‘rk0001’, ‘info:name’, ‘zhangsan’
向user表中插入信息,row key为rk0001,列族info中添加名为gender的列,值为female
HBase(main):012:0> put ‘user’, ‘rk0001’, ‘info:gender’, ‘female’
向user表中插入信息,row key为rk0001,列族info中添加名为age的列,值为20
HBase(main):013:0> put ‘user’, ‘rk0001’, ‘info:age’, 20
向user表中插入信息,row key为rk0001,列族data中添加名为pic的列,值为picture
HBase(main):014:0> put ‘user’, ‘rk0001’, ‘data:pic’, ‘picture’
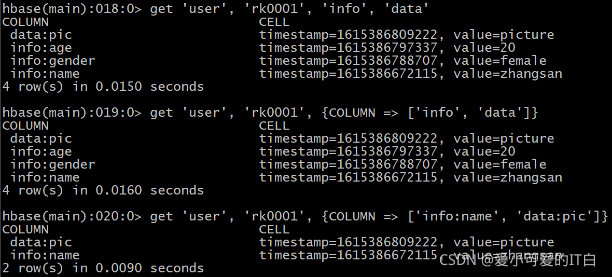
④ 查询数据操作一
查询方式一 使用get命令通过rowkey进行查询
获取user表中row key为rk0001的所有信息(即所有cell的数据)
使用get命令
HBase(main):015:0> get ‘user’, ‘rk0001’

使用get命令查看rowkey下某个列族的信息
获取user表中row key为rk0001,info列族的所有信息
HBase(main):016:0> get ‘user’, ‘rk0001’, ‘info’

使用get命令查看rowkey指定列族指定字段的值
获取user表中row key为rk0001,info列族的name、age列的信息
HBase(main):017:0> get ‘user’, ‘rk0001’, ‘info:name’, ‘info:age’


使用get命令查看rowkey指定多个列族的信息
获取user表中row key为rk0001,info、data列族的信息
HBase(main):018:0> get ‘user’, ‘rk0001’, ‘info’, ‘data’
或者你也可以这样写
HBase(main):019:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info’, ‘data’]}
或者你也可以这样写,也行
HBase(main):020:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info:name’, ‘data:pic’]}
使用get命令指定rowkey与列值过滤器查询
获取user表中row key为rk0001,cell的值为zhangsan的信息
HBase(main):021:0> get ‘user’, ‘rk0001’, {FILTER => “ValueFilter(=, ‘binary:zhangsan’)”}

使用get命令指定rowkey与列名模糊查询
获取user表中row key为rk0001,列标示符中含有a的信息
HBase(main):022:0> get ‘user’, ‘rk0001’, {FILTER => “QualifierFilter(=,‘substring:a’)”}

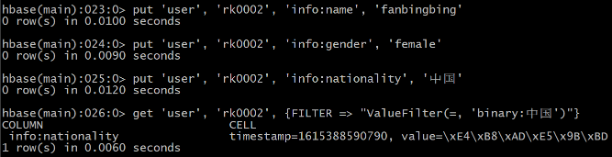
继续插入一批数据
HBase(main):023:0> put ‘user’, ‘rk0002’, ‘info:name’, ‘fanbingbing’
HBase(main):024:0> put ‘user’, ‘rk0002’, ‘info:gender’, ‘female’
HBase(main):025:0> put ‘user’, ‘rk0002’, ‘info:nationality’, ‘中国’
HBase(main):026:0> get ‘user’, ‘rk0002’, {FILTER => “ValueFilter(=, ‘binary:中国’)”}
⑤ 查询所有行的数据二
查询user表中的所有信息
使用scan命令
HBase(main):027:0> scan ‘user’

使用scan命令进行列族查询
查询user表中列族为info的信息
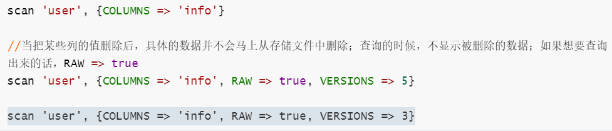
scan ‘user’, {COLUMNS => ‘info’}

//当把某些列的值删除后,具体的数据并不会马上从存储文件中删除;查询的时候,不显示被删除的数据;如果想要查询出来的话,RAW => true
scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 5}

scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 3}

使用scan命令进行多列族查询
查询user表中列族为info和data的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’]}

使用scan命令指定列族与某个列名查询
查询user表中列族为info、列标示符为name的信息
scan ‘user’, {COLUMNS => ‘info:name’}

查询info:name列、data:pic列的数据
scan ‘user’, {COLUMNS => [‘info:name’, ‘data:pic’]}

查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan ‘user’, {COLUMNS => ‘info:name’, VERSIONS => 5}

使用scan命令指定多个列族与条件模糊查询
查询user表中列族为info和data且列标示符中含有a字符的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’], FILTER => “QualifierFilter(=,‘substring:a’)”}

使用scan命令指定rowkey的范围查询
查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan ‘user’, {COLUMNS => ‘info’, STARTROW => ‘rk0001’, ENDROW => ‘rk0003’}

使用scan命令指定rowkey模糊查询
查询user表中row key以rk字符开头的数据

使用scan命令指定数据版本的范围查询
查询user表中指定范围的数据(前闭后开)
scan ‘user’, {TIMERANGE => [1392368783980, 1392380169184]}

hbase(main):039:0> scan ‘user’, {TIMERANGE => [1615386788707,1615386809222]}

⑥ 更新数据操作
1 更新数据值
更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加
使用put命令
2 更新版本号
将user表的f1列族版本数改为5
HBase(main):040:0> alter ‘user’, NAME => ‘info’, VERSIONS => 5

⑦ 删除数据以及删除表操作
1 指定rowkey以及列名进行删除
删除user表row key为rk0001,列标示符为info:name的数据(删除一个kv数据)
HBase(main):041:0> delete ‘user’, ‘rk0001’, ‘info:name’

删除整行数据
hbase(main):024:0> deleteall 't_user_info','001'
0 row(s) in 0.0090 seconds
hbase(main):025:0> get 't_user_info','001'
COLUMN CELL
0 row(s) in 0.0110 seconds
2 指定rowkey,列名以及版本号进行删除
删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
hbase(main):042:0> delete ‘user’, ‘rk0001’, ‘info:name’, 1392383705316

3 删除一个列族
删除一个列族:
alter ‘user’, NAME => ‘info’, METHOD => ‘delete’
或 alter ‘user’, ‘delete’ => ‘info’

4 清空表数据
HBase(main):045:0> truncate ‘user’

5 删除表
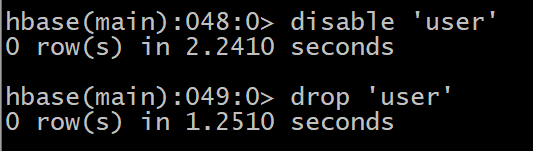
首先需要先让该表为disable状态,使用命令:
HBase(main):049:0> disable ‘user’
然后使用drop命令删除这个表
HBase(main):050:0> drop ‘user’
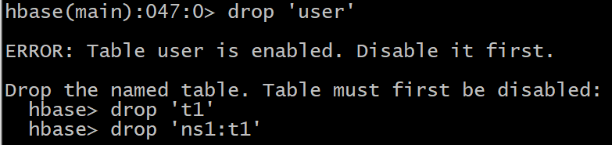
(注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled)
⑧ 统计一张表有多少行数据
HBase(main):046:0> count ‘user’
六 HBase的高级shell管理命令
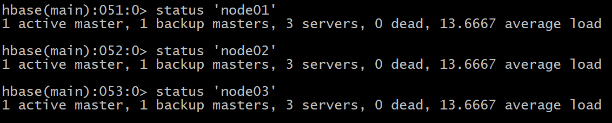
1 status
例如:显示服务器状态
HBase(main):051:0> status ‘node01’
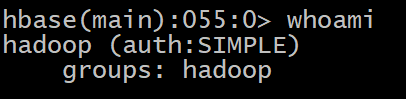
2 whoami
显示HBase当前用户,例如:
HBase> whoami
3 list
显示当前所有的表
HBase > list

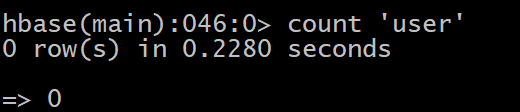
4 count
统计指定表的记录数,例如:
HBase> count ‘user’
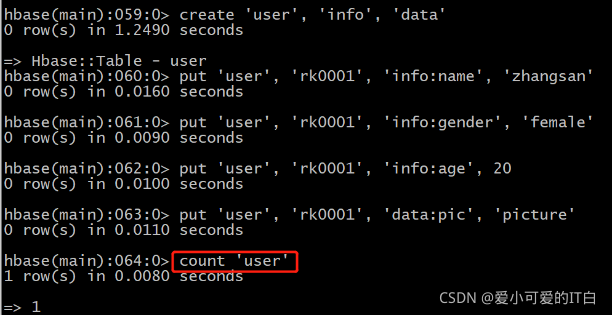
为了展示下面功能,然后重新创建user表,并插入数据
创建user表,包含info、data两个列族
使用create命令
hbase(main):008:0> create 'user', 'info', 'data'
0 row(s) in 1.3080 seconds
向表中插入数据
使用put命令
向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
HBase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
向user表中插入信息,row key为rk0001,列族info中添加名为gender的列,值为female
HBase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
向user表中插入信息,row key为rk0001,列族info中添加名为age的列,值为20
HBase(main):013:0> put 'user', 'rk0001', 'info:age', 20
向user表中插入信息,row key为rk0001,列族data中添加名为pic的列,值为picture
HBase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'
5 describe
展示表结构信息
HBase> describe ‘user’

6 exists
检查表是否存在,适用于表量特别多的情况
7 is_enabled、is_disabled
检查表是否启用或禁用
HBase> is_enabled ‘user’
HBase> is_disabled ‘user’
8 alter
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
HBase> alter ‘user’, NAME => ‘CF2’, VERSIONS => 2

为当前表删除列族:
HBase(main):002:0> alter ‘user’, ‘delete’ => ‘CF2’

9 disable/enable
禁用一张表/启用一张表
HBase> disable ‘user’
HBase> enable ‘user’
10 drop
删除一张表,记得在删除表之前必须先禁用
11 truncate
禁用表-删除表-创建表
七 Hive与HBase的集成
Hive提供了与HBase的集成,使得能够在HBase表上使⽤HQL语句进⾏查
询 插⼊操作以及进⾏Join和Union等复杂查询、同时也可以将hive表中的
数据映射到Hbase中。
版本说明:
hbase版本:hbase-1.2.0-cdh5.14.2
hive版本:hive-1.1.0-cdh5.14.2
数据模型:
row,addres,age,username
001,guangzhou,20,alex
002,shenzhen,34,jack
003,beijing,23,lili
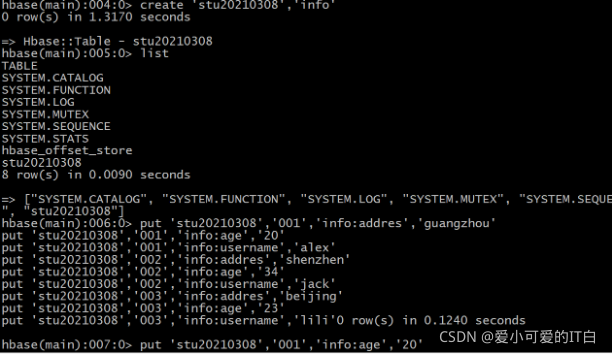
创建HBase的数据:
create 'stu20210308','info'
put 'stu20210308','001','info:addres','guangzhou'
put 'stu20210308','001','info:age','20'
put 'stu20210308','001','info:username','alex'
put 'stu20210308','002','info:addres','shenzhen'
put 'stu20210308','002','info:age','34'
put 'stu20210308','002','info:username','jack'
put 'stu20210308','003','info:addres','beijing'
put 'stu20210308','003','info:age','23'
put 'stu20210308','003','info:username','lili'
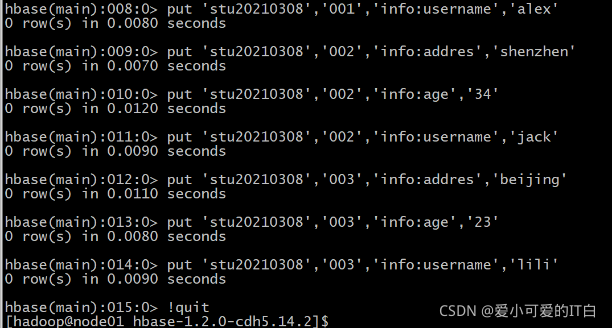
ps:退出HBASE指令是!quit
创建与HBase集成的Hive的外部表:
CREATE EXTERNAL TABLE stu20210308(
id string,
addres string,
age string,
username string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,info:addres,info:age,info:username")
TBLPROPERTIES ("hbase.table.name" = "stu20210308");
hive (test)> CREATE EXTERNAL TABLE stu20210308(> id string,> addres string,> age string,> username string)> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'> WITH SERDEPROPERTIES (> "hbase.columns.mapping" => ":key,info:addres,info:age,info:username")> TBLPROPERTIES ("hbase.table.name" = "stu20210308");
OK
Time taken: 1.933 seconds
hive (test)> select * from stu20210308;
OK
stu20210308.id stu20210308.addres stu20210308.age stu20210308.username
001 guangzhou 20 alex
002 shenzhen 34 jack
003 beijing 23 lili
Time taken: 0.09 seconds, Fetched: 3 row(s)
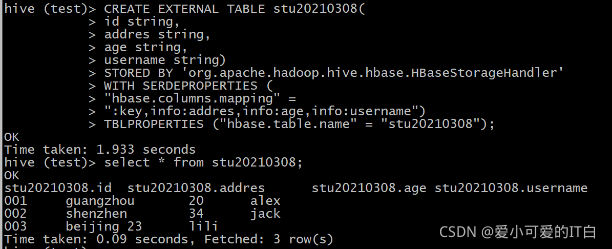
ps:具体这里可查看Hive与HBase的集成
Hive表映射HBase实例二
建HBase表
hbase(main):018:0> create ‘user_info’,‘info’
数据插入HBase
info:order_amt
info:order_id
info:user_id
info:user_name
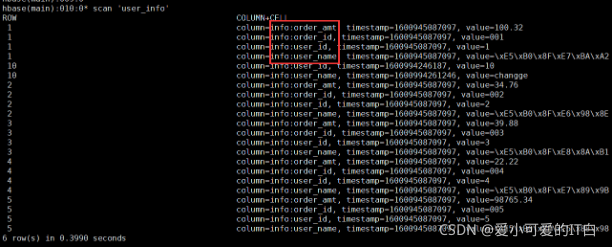
建hive映射表
create external table wedw_tmp.t_user_info
(
id string
,order_id string
,order_amt string
,user_id string
,user_name string
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping"=":key,info:order_id,info:order_amt,info:user_id,info:user_name")
tblproperties("hbase.table.name"="user_info");
查询映射好的hive表
select * from wedw_tmp.t_user_info;
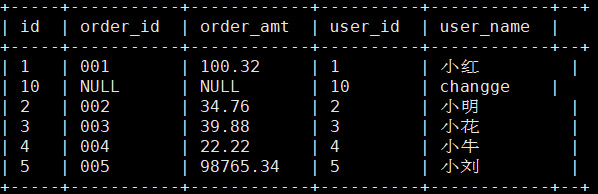
八 HBase客户端API操作
表创建
增加数据
删除数据
全表扫描
过滤器
匹配
九 phoenix操作HBase
Phoenix,由saleforce.com 开源的一个项目,后又捐给了Apache。它相当于一个Java 中间件,帮助开发者,像
使用jdbc 访问关系型数据库一样,访问NoSql 数据库HBase。
Apache Phoenix 与其他Hadoop 产品完全集成,如Spark,Hive,Pig,Flume 和MapReduce。
1 安装pheonix
1.1 下载pheonix
http://phoenix.apache.org/download.html
注意:下载Phoenix 的时候,请注意对应的版本,其中4.14 版本可以运行在HBase0.98、1.1、1.2、1.3、1.4 上。
下载时也可以直接使用:
wget http://mirrors.shu.edu.cn/apache/phoenix/apache-phoenix-4.14.0-HBase-1.2/bin/apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
1.2 解压pheonix
tar -zxvf apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
1.3 整合phoenix到hbase
查看Phoenix 下的所有的文件,将phoenix-4.14.0-HBase-1.2-server.jar 拷贝到所有HBase 节点(包括Hmaster以及HregionServer)的lib 目录下:
重启HBase:
bin/stop-hbase.sh
bin/start-hbase.sh
1.4 使用phoenix SQL命令行
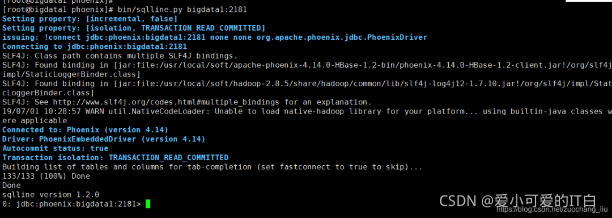
进入Phoenix 的安装包,执行:
bin/sqlline.py bigdata1:2181
1.4.1 创建表
在Phoenix 终端下创建us_population 表:
>> CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
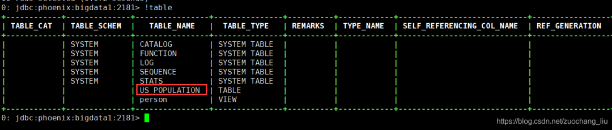
使用!tables 查看创建的表:
>> !tables
1.4.2 编辑并导入数据
在Phoenix 目录下创建一个data 目录,在data 目录下创建:
vi us_population.csv
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
执行bin/psql.py data/us_population.csv 导入数据。
除了导入数据外,还可以使用Phoenix 的语法插入数据:upsert into us_population values(‘NY’,‘NewYork’,8143197);
1.4.3 查询数据
方式一:在data 目录下创建us_population_queries.sql 文件:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
执行bin/psql.py data/us_population_queries.sql 检索数据。
方式二:使用命令行终端
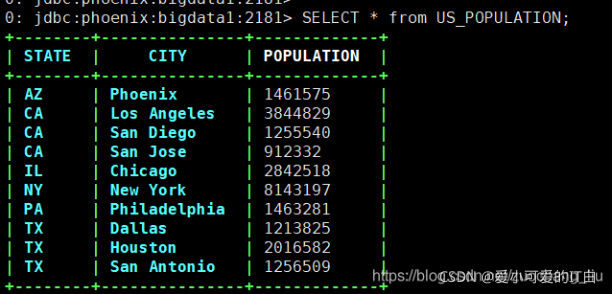
bin/sqlline.py bigdata1:2181
>> select * from us_populcation;
2 Squirrel-sql 连接Phoenix
2.1 下载Squirrel-sql
http://www.squirrelsql.org/#installation
2.2 设置Squirrel-sql 连接Phoenix
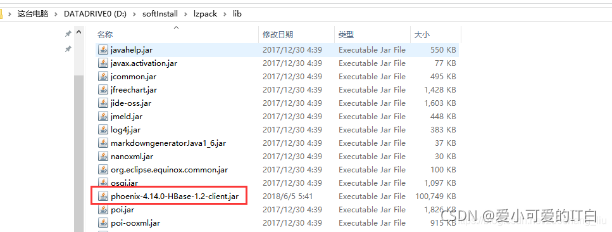
拷贝Phoenix Client jar【phoenix-4.14.0-HBase-1.2-client.jar】到Squirrel-sql 的lib 目录;
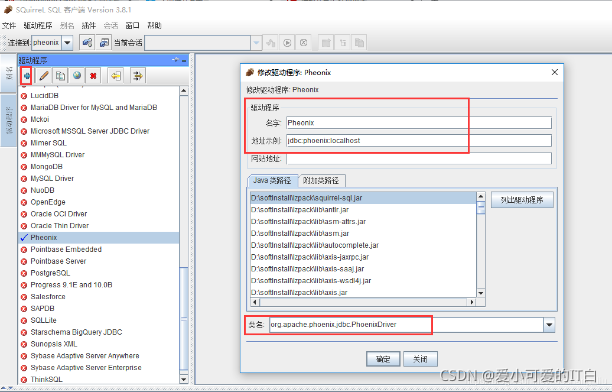
设置Phoenix 连接的Driver 信息,其中localhost 为zookeeper 所在的主机地址,填写一个即可。
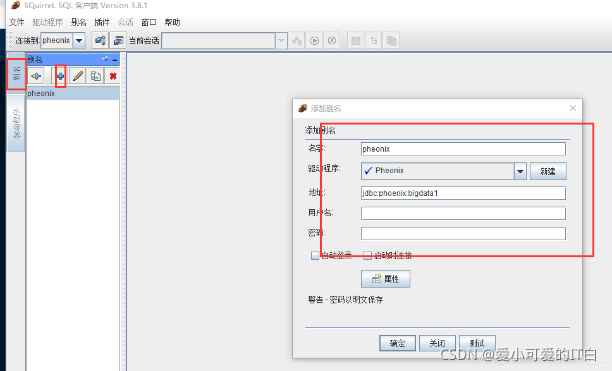
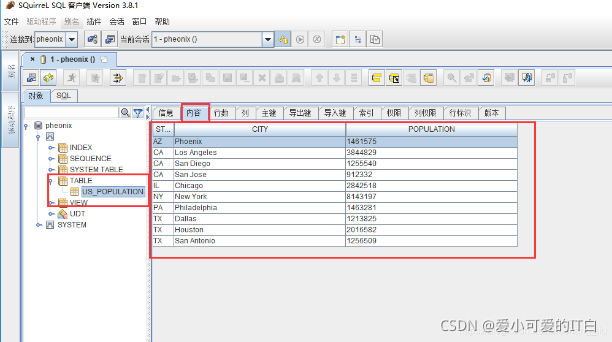
3 Phoenix 映射Hbase 表
进入Hbase 命令行终端bin/hbase shell
创建Hbase 表’phoenix’:
– 创建Hbase 表Phoenix,列族info
create ‘phoenix’,‘info’
– 添加数据
put ‘phoenix’, ‘row001’,‘info:name’,‘phoenix’
put ‘phoenix’, ‘row002’,‘info:name’,‘hbase’
映射HBase 表的方式有两种,一直是视图映射,一种是表映射。
两者的区别就是对HBase 的物理表有没有影响;
删除Phoenix 视图映射不会对Hbase 的表造成影响;
删除Phoenix 表映射会将Hbase 的表也删除;
非必要情况下一般创建视图映射。
3.1 视图映射
在Phoenix 下创建视图映射HBase 表:
-- 创建视图关联映射Hbase 表
create view "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
);
查询创建好的Phoenix 视图:
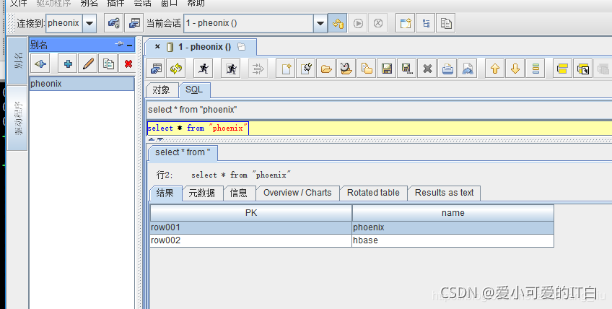
– 删除视图后,在hbase shell 终端下查看phoenix 依然存在
drop view "phoenix";
3.2 表映射
在Phoenix 下创建表映射HBase 表:
– 创建表关联映射Hbase 表,4.10 以后Phoenix 优化了列映射,COLUMN_ENCODED_BYTES=0 禁用列映射。
create table "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
) COLUMN_ENCODED_BYTES = 0;
查询数据:
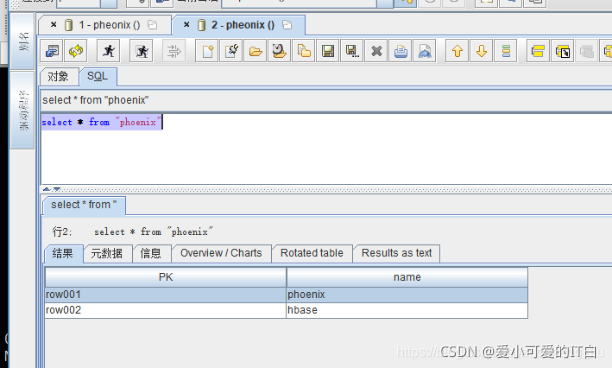
结语:
本篇文章介绍到此结束,码字不易,如果本篇文章对您有所帮助,麻烦动动发财的小手,三连点赞,关注,收藏支持下。有需要沟通交流的,可随时沟通交流,多谢大家支持!!!



这篇关于【由浅入深讨论HBase:自认全网最全最细】,你想了解的关于HBase知识,基本上都有,有需要的可以收藏当字典使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






