本文主要是介绍【Hung-Yi Lee】强化学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- What is RL
- Policy Gradient
- Policy Gradient实际是怎么做的
- On-policy v.s. Off-policy
- Exploration
- 配音大师
- Actor-Critic
- 训练value function的方式
- 网络设计
- DQN
- Reward Shaping
- No Reward:Learning from Demonstration
What is RL
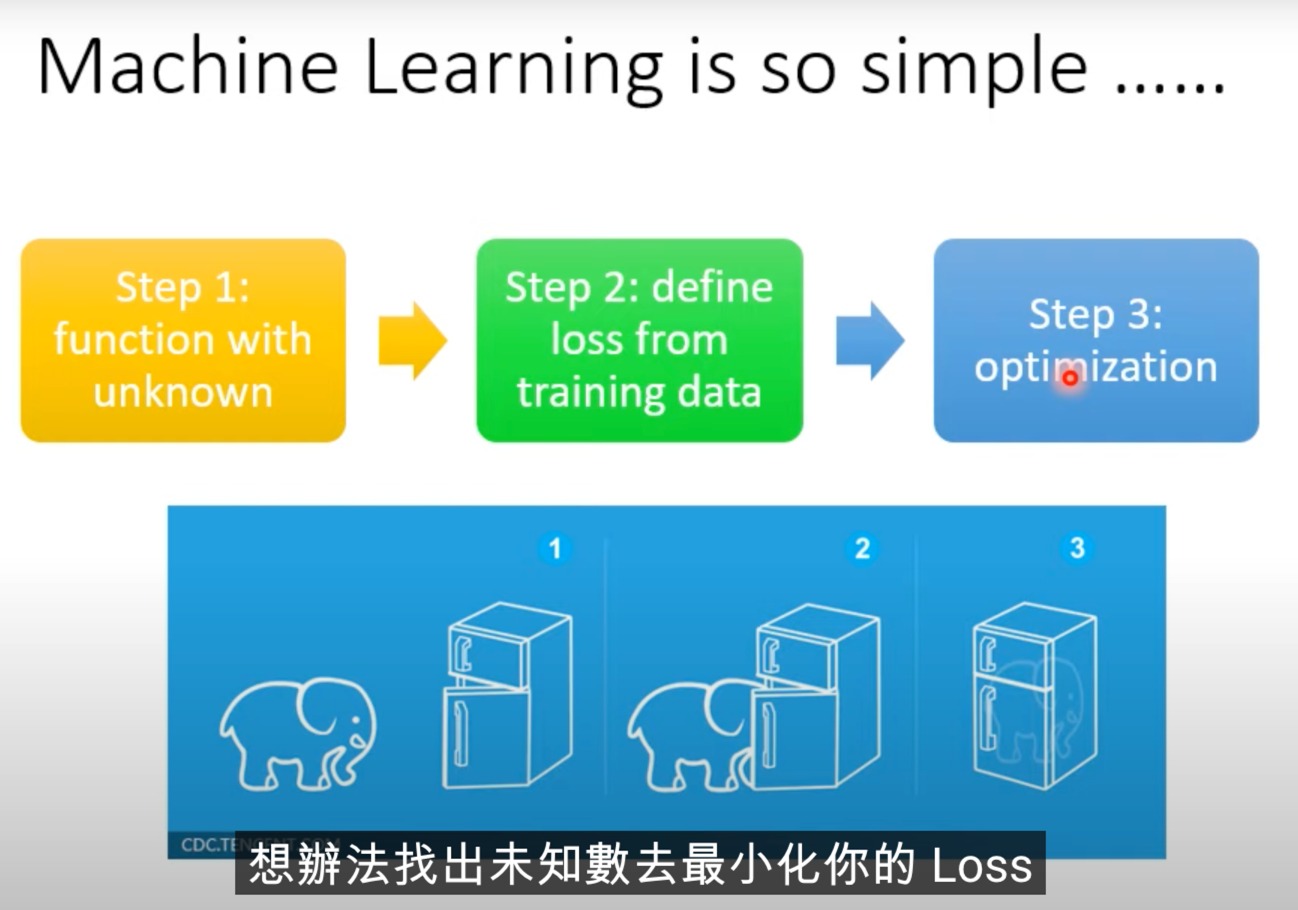
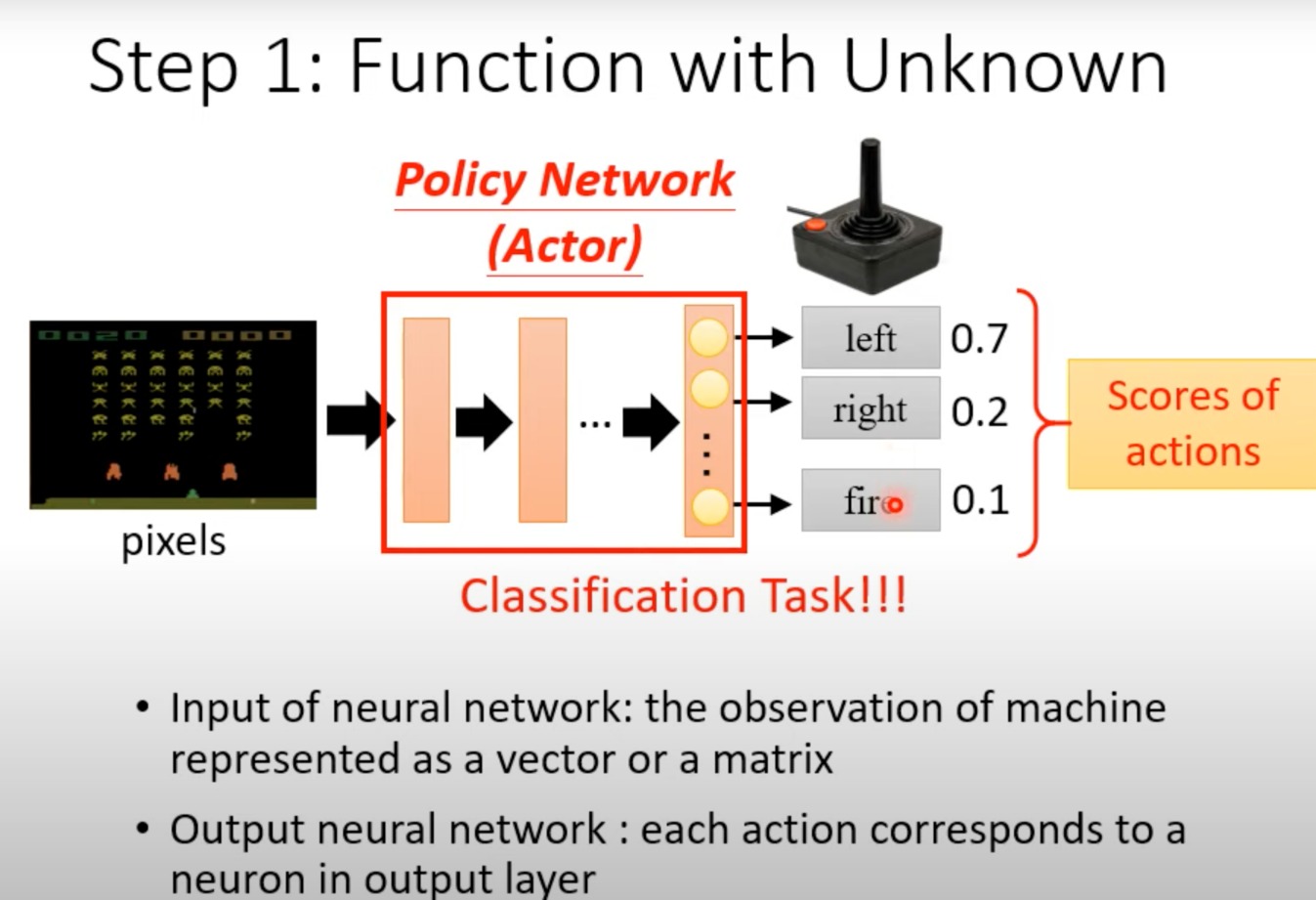
定义一个策略网络,来接受输入,并决定什么输出

不断的在环境和执行的action之间切换,最后获得一个总的reward(每一步的reward加起来),是我们要最大化的东西。
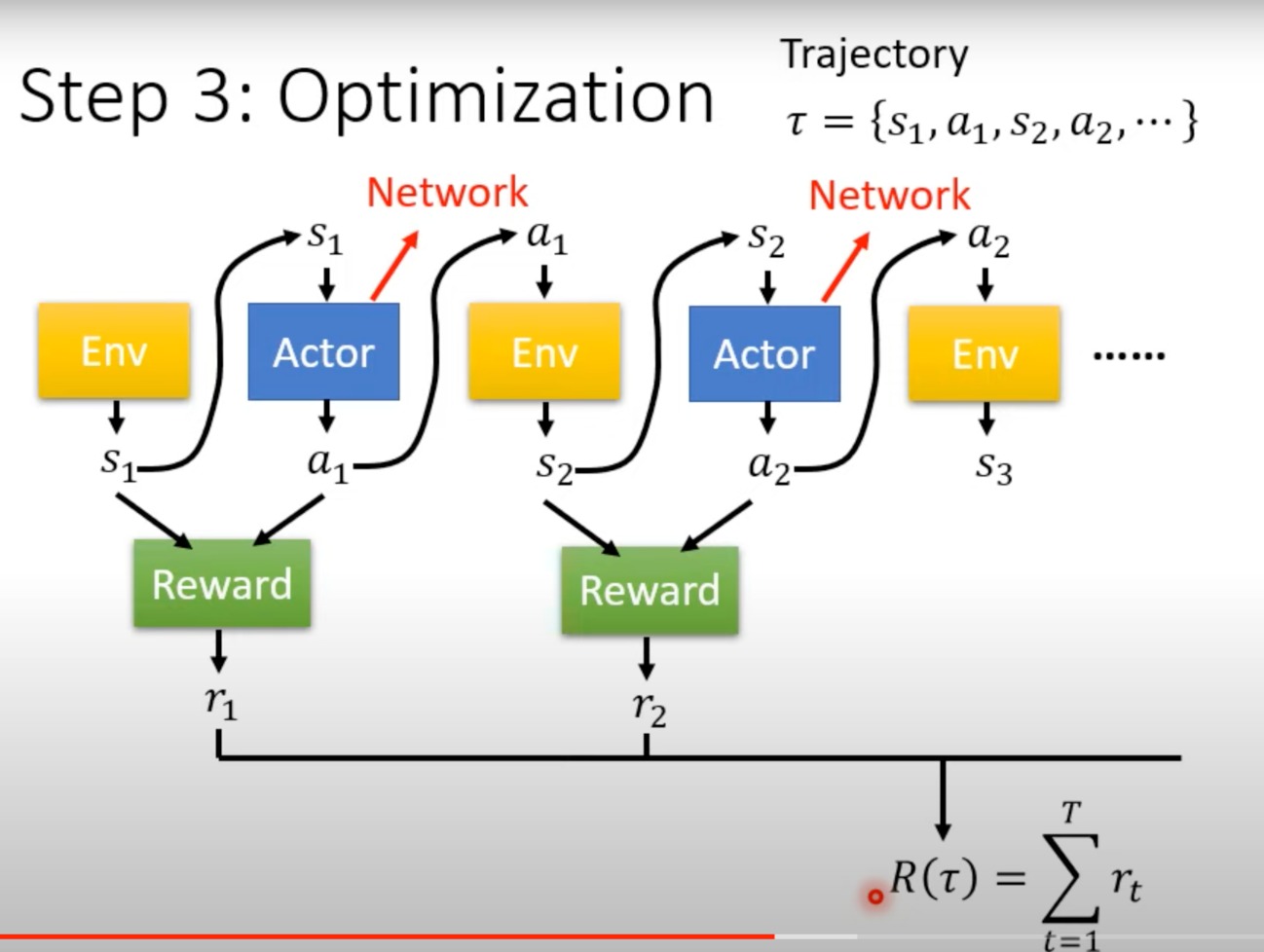
reward是一个function,把s1(observation)和a1(action)当作输入,r1当作输出
我们要learn network里的参数,让R越大越好
但是RL没有一般的深度学习那么简单,主要难在以下几点:
- 对于Actor,对于一样的s1,其输出的a1是有随机性的
- ENV只是一个黑盒子,Reward只是一个规则。而不是一个network,只是都会输入一个东西,然后输出一个东西而已。此外他们也有随机性,对于同样的action,对手的反应是存在随机性的。
所以没办法用梯度下降的方式来训练
Policy Gradient

定义Loss为输出的 α \alpha α,与我们想要他进行的 α ^ \hat{\alpha} α^(比如这里是希望他向左),计算交叉熵,其结果就是loss,然后我们希望actor中的参数能让loss最小
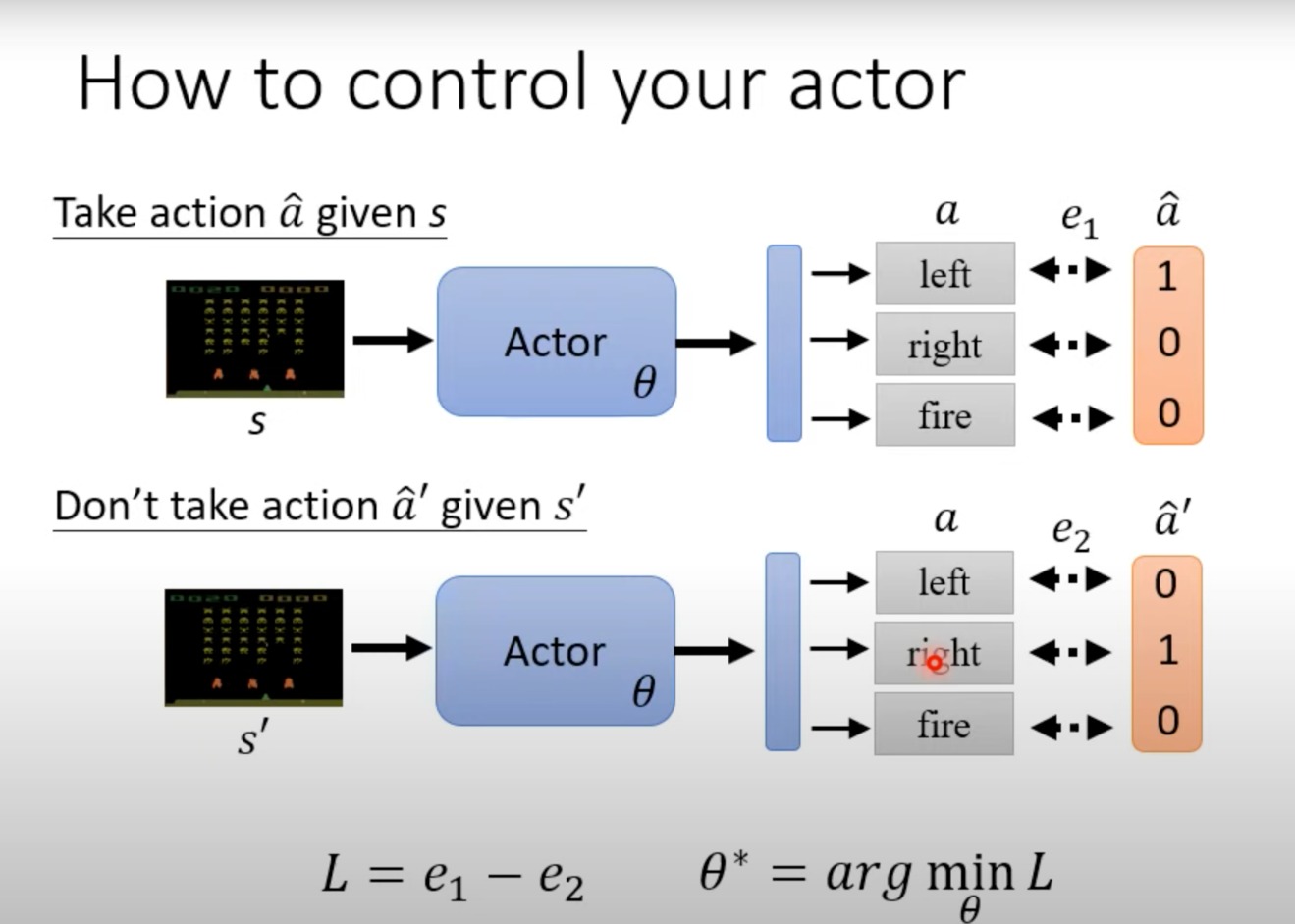
这样用一个训练分类器的方法,大致就是可以去控制actor
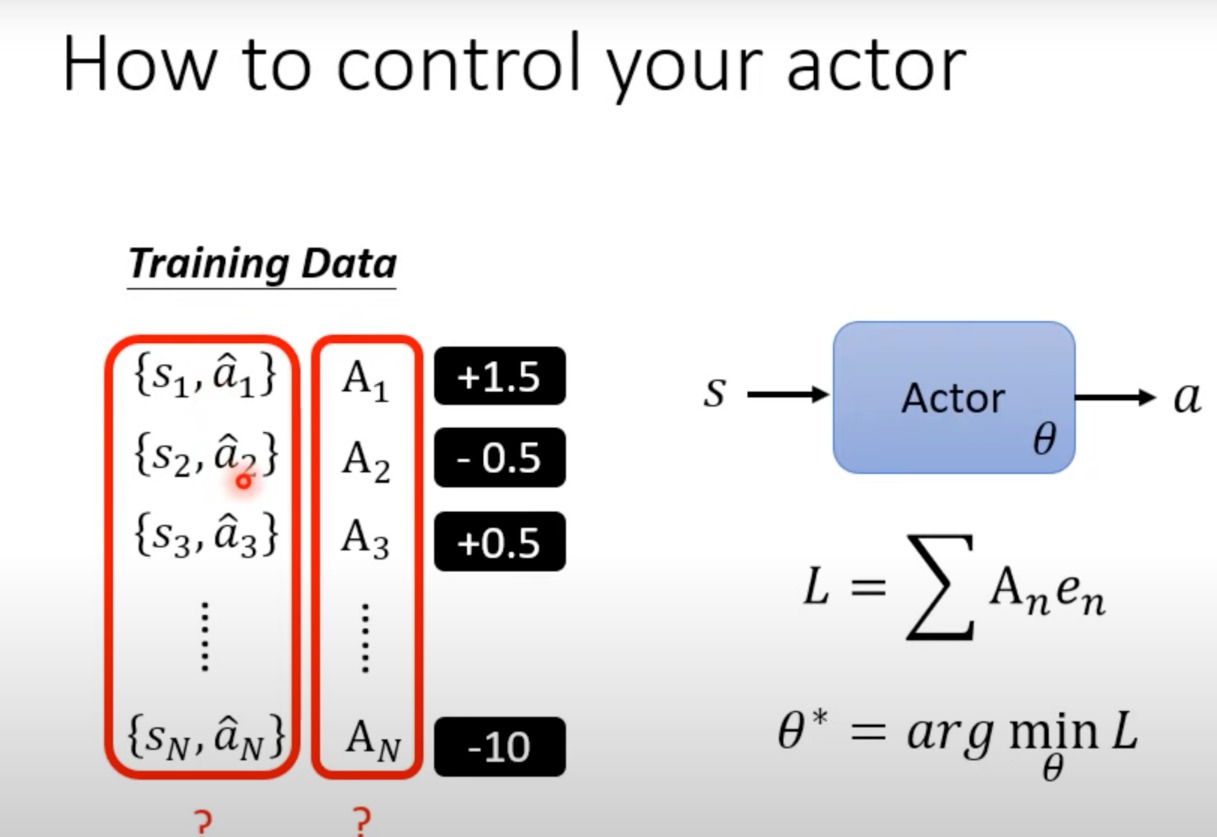
这里就是给定s1和a1后,给出一个参数A1,用于判断a1这个行为对于当前s1这个环境,是正确的决定,还是不要执行的决定。而且有一个正确/错误的程度。
前面这个A的值只是±1,现在有大小区别
至于这个数据是如何产生的,这是后面要讨论的问题
- 训练数据是如何产生的
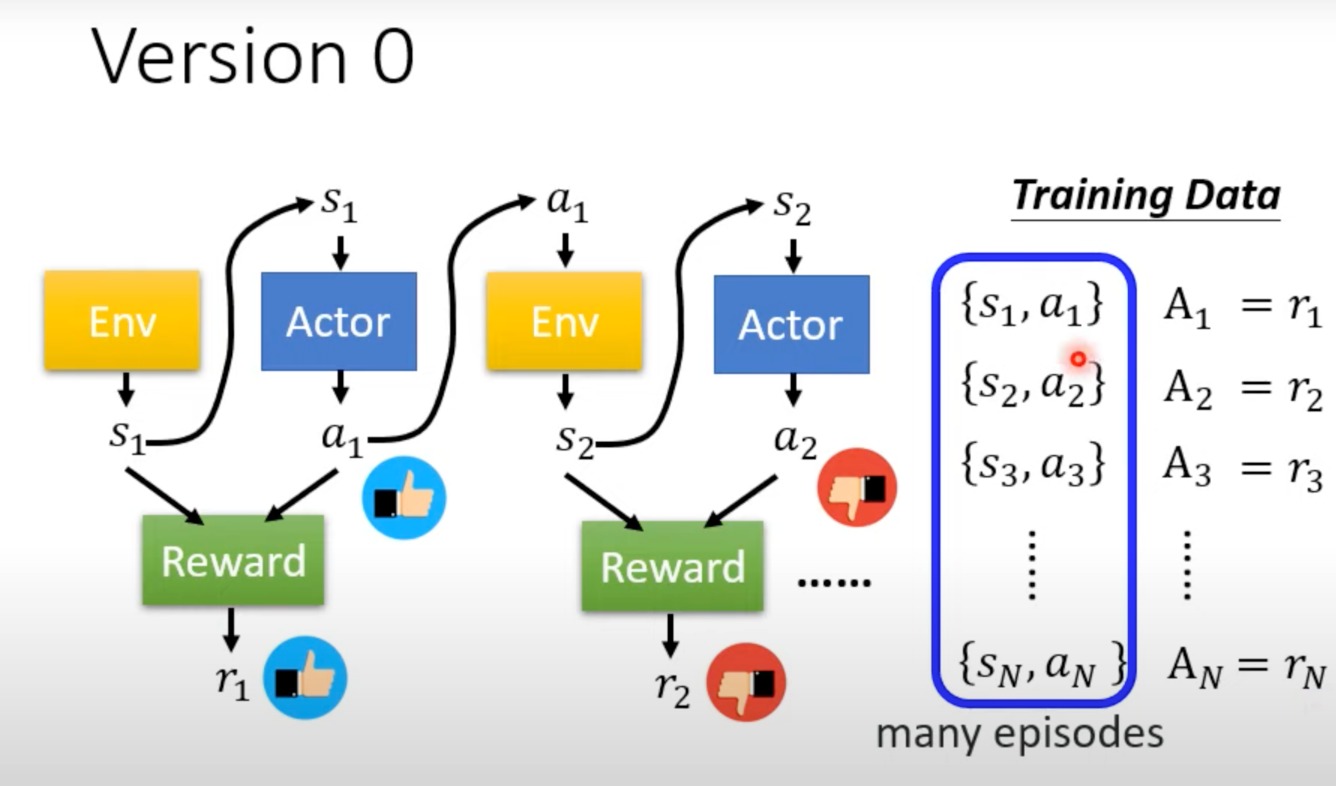
跑很多个episode,然后进行每个pair的评估,将对应reward的值作为评估结果。
不过这样有个问题,这样是一个短期的评估,他没有长期的规划,只知道“一时爽”。
- An action affects the subsequent observations and thussubsequent rewards.
- 比如a1会影响到s2、a2、r2
- Reward delay: Actor has to sacrifice immediate reward togain more fong-term reward.
- 有时候我们需要牺牲短期利益,获取长期目标
- 比如我们要先左右移动瞄准,再进行射击,左右瞄准没有短期reward,但并不代表不重要

- 我们进一步修正,将对于一个a1,将其后面的r都加起来,作为reward,来评估action的好坏

- 进一步添加 γ \gamma γ,距离越远,action的影响越小

- 考虑到reward是相对的,所以我们要做一下类似标准化的事情
- 比如全班的最高分是80,而你得了20分,这样其实是差的,但是G的绝对值还是20分,所以只拿G的数值去算是不对的
- 所以给定一个baseline b,所有的G都要减去这个b

Policy Gradient实际是怎么做的
具体的操作
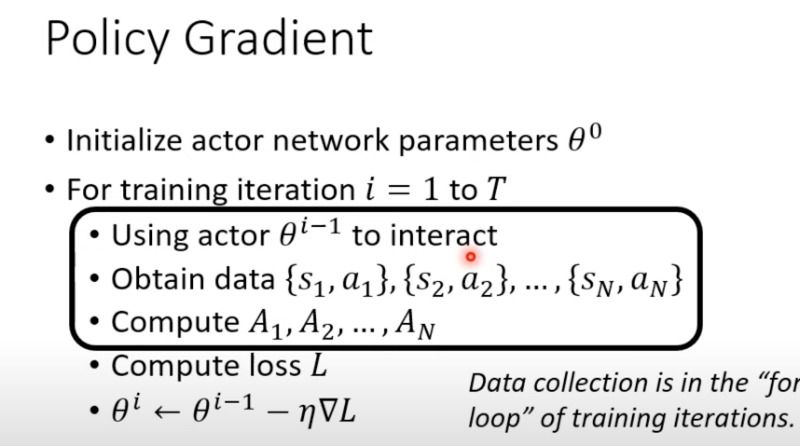
data collection是在for循环,这个训练里面的
- 图像化表示这个过程,每一次更新参数之后,都要重新收集数据,这也是为什么rl的training这么浪费时间的原因
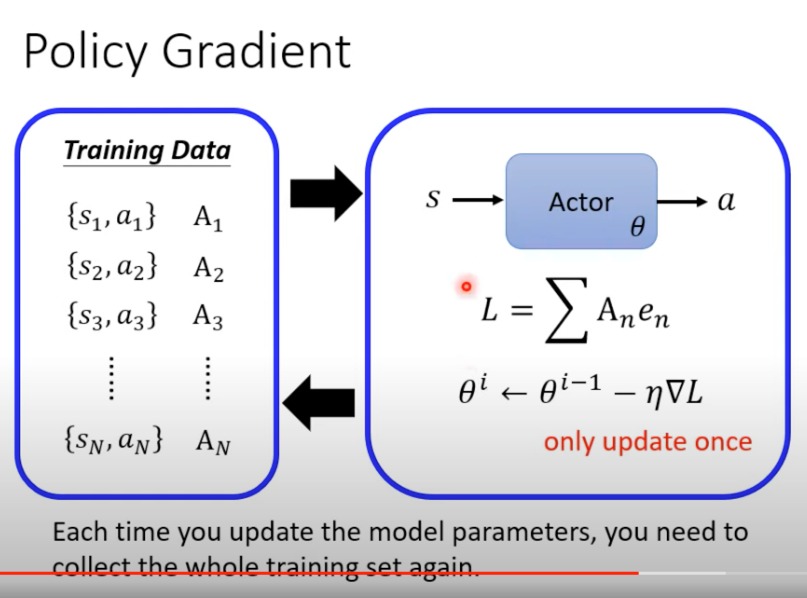
- 为什么一次更新完就要重新收集资料呢
- θ i \theta^i θi是根据 θ i − 1 \theta^{i-1} θi−1推演过来的没错,但是在 θ i − 1 \theta^{i-1} θi−1的时刻,其后面的推测的 θ i \theta^i θi的Traiectory部分,并非真正在 θ i \theta^i θi时刻的Traiectory
- 所以不能只收集一次数据,要一轮收集一次

On-policy v.s. Off-policy

- 我们前面用的方法都是On-policy的,就是训练的actor跟与环境交互的actor是同一个actor。但是也有Off-policy的训练方法,这个这里不细讲,比如用一些方法,用 θ i − 1 \theta^{i-1} θi−1所搜集到的资料去训练 θ i \theta^{i} θi,这样就可以收集一次资料训练好多次,是Off-policy的好处
- 举例一个Off-policy的方法

Exploration
一个重要的技巧
与环境互动的这个actor的随机性非常重要,这个actor多尝试,我们才能获取更大范围的资料,行为对应的reward,更好的训练。

配音大师
全视频最好笑的地方
配音大师 39:39
Actor-Critic
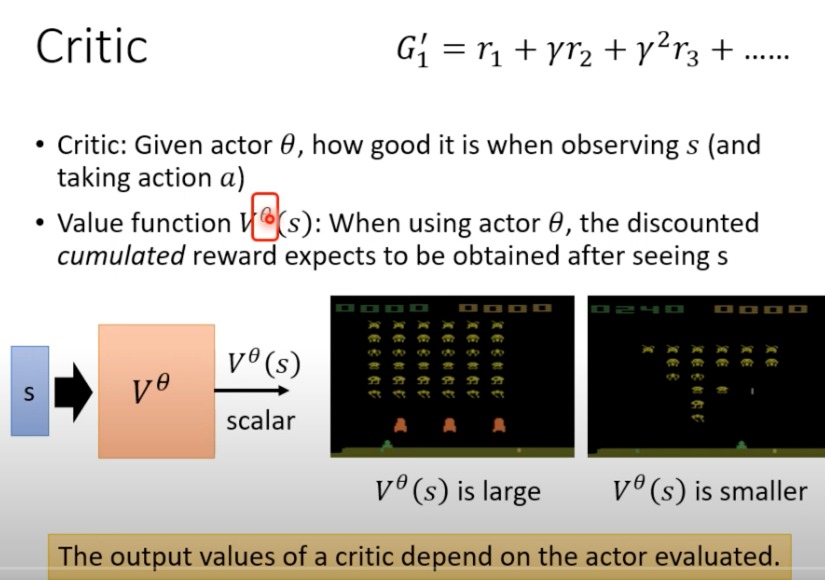
Critic 是 Actor-Critic 方法中的一部分,主要用于评估给定的Actor(即策略)的性能
对于同一个s,不同的actor θ \theta θ,其V值不同
值函数:这是一个由Critic学习的函数,用来估计在策略θ下,在状态s开始并遵循该策略能获得的折扣累积奖励。这个值函数预测了从当前状态s开始,未来所有可能收到的奖励的当前价值。
值函数表示一个策略在特定状态s下的期望收益。它是一个平均的结果,因为它试图总结在该状态下,遵循特定策略可能导致的所有可能的未来路径的预期回报。
对于一个s,一个a会得到多种可能的汇报,而V是一个期望值
训练value function的方式
- 马尔可夫方法
- 需要玩完整把游戏,直接看我们观察到的资料
- 通过完整的序列(或者说是episode)来估计价值函数,这意味着它必须等到一个episode结束后才能进行价值估计
- MC方法不需要模型,即不需要知道环境的状态转移概率和奖励函数。
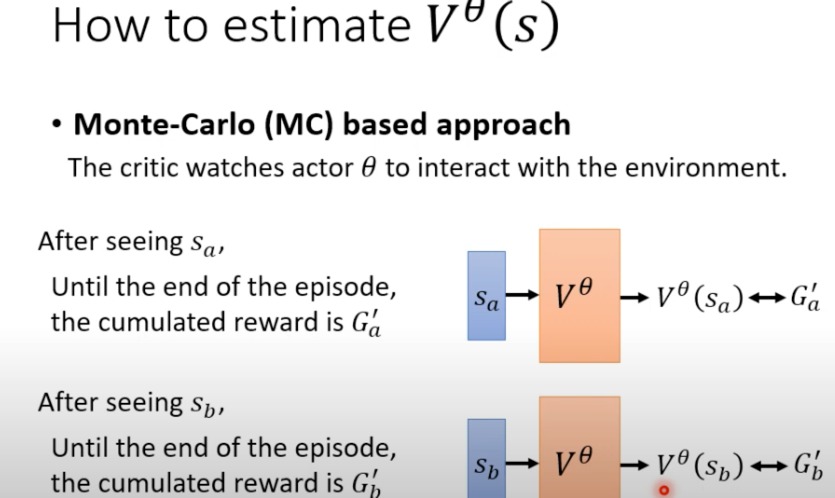
- TD
- 不需要玩完整把游戏
- 与 r t r_t rt越接近越好
- TD方法可以在不需要等待当前episode结束的情况下,通过部分序列来估计价值函数,通常每步都会更新。
- 它结合了当前收到的奖励和下一个状态的估计值来更新当前状态的价值。

- 两种方法比较

选择MC方法还是TD方法取决于应用的特定需求,包括环境的特性、是否有明确的episode边界、以及学习的速度需求等。在实际中,强化学习的策略往往需要根据具体问题进行调整和优化。一些高级的算法如Actor-Critic方法,实际上结合了两种方法,使用TD方法来估计Critic的价值函数,同时使用Policy Gradient方法(可能基于MC的思想)来更新Actor的策略。
- 将Critic用于RL
对于version3来说,如何设置b的值。这里给他设置为V(s)
learn出一个Critic后,对应每个s,都有V值
- Advantage函数 A t A_t At:它定义为在时间步t的实际回报( G t ′ G^{'}_t Gt′)减去在状态 S t S_t St下的值函数估计 ( V θ ( S t ) ) (V^{\theta}(S_t)) (Vθ(St))。这个值告诉我们一个动作实际上比我们通常期望的要好或要坏多少。
- 如果 A t A_t At>0,意味着动作 a t a_t at的表现比平均的期望要好。
- 如果 A t A_t At<0,意味着动作 a t a_t at的表现比平均的期望要差。

-
为什么这样做
-
对于一个s,actor的输出是有随机性的,所以会有不同的reward
-
在实际训练中,我们会调整策略来提高那些具有正Advantage值的动作的概率,同时降低那些具有负Advantage值的动作的概率。
-

-
但是这有一个小问题,就是 G t ′ G^{'}_t Gt′是一次随机的值,而值函数估计 ( V θ ( S t ) ) (V^{\theta}(S_t)) (Vθ(St))是一个平均值,拿某一次值减随机,总感觉怪怪的。
-
所以最后一个版本,就是拿平均减平均
-
-
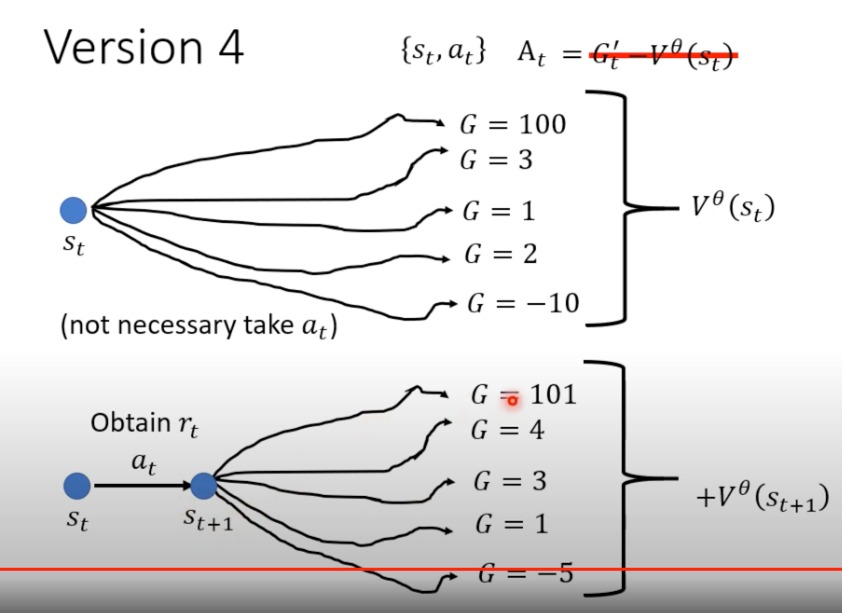
Version 4
-
根据训练好的Critic(相当于预测模型),可以直接根据 s t + 1 s_{t+1} st+1得到 V θ ( S t + 1 ) V^{\theta}(S_{t+1}) Vθ(St+1)
-
这个版本与前面版本的主要区别在于它不等待整个序列(或episode)结束来计算回报 、G,而是使用当前步骤的即时奖励和对下一个状态的值估计来更新。
-
-
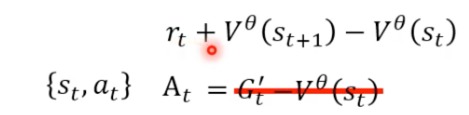
-
意思是什么呢
- 就是对于st,采取at这个action,得到的期望reward。减去不采取at,而是根据某种概率分布sample到的action得到的reward期望。两个期望值差距有多大
- 如果 A t A_{t} At>0,那么就说明这个at好,否则就差。
- 这就是大名鼎鼎的Advantage Actor-Critic
-
有一些我对概念的困惑,问了问gpt。
Actor:强化学习算法中的决策实体,负责根据当前环境状态选择动作。在Actor-Critic架构中,actor是指那部分网络,其目标是通过学习来优化策略参数 ( θ \theta θ ),以最大化期望奖励。
**Action ( $a_t KaTeX parse error: Can't use function '\)' in math mode at position 1: \̲)̲**:在每个时间步 \( t $) 智能体所执行的具体操作。动作是智能体与环境交互的手段,智能体的目标是通过选择最优动作来最大化其长期奖励。
- Actor像是一个分类器,要经过训练,最后输出多个可能的Actions,并且带有每种Action 的概率。最后决定使用的Action是从中sample出来的。
策略参数 ( $\theta $):定义智能体策略的参数集,通常在基于模型的强化学习中,( θ \theta θ ) 表示神经网络的权重和偏置。这些参数确定了智能体在特定状态下各个动作的选择概率。
动作选择过程:智能体(actor)观察当前环境状态 ($ s_t $),并使用其策略参数 ( $\theta KaTeX parse error: Can't use function '\)' in math mode at position 1: \̲)̲ 来决定动作 \( a_t $) 的概率分布。然后智能体从这个概率分布中采样,以选择下一步要执行的具体动作。
总结如下:
智能体(Actor)使用其策略参数 ($ \theta$ ) 来决定在特定环境状态 ( s t s_t st ) 下的动作概率分布,并从中选择动作 ( a t a_t at ),这个动作随后会影响环境,产生新的状态和奖励。这些信息被用来更新策略参数 ($ \theta$ ),从而优化未来的动作选择。
如果有某些observation是没观察到过的话,就没办法训练
网络设计
训练技巧
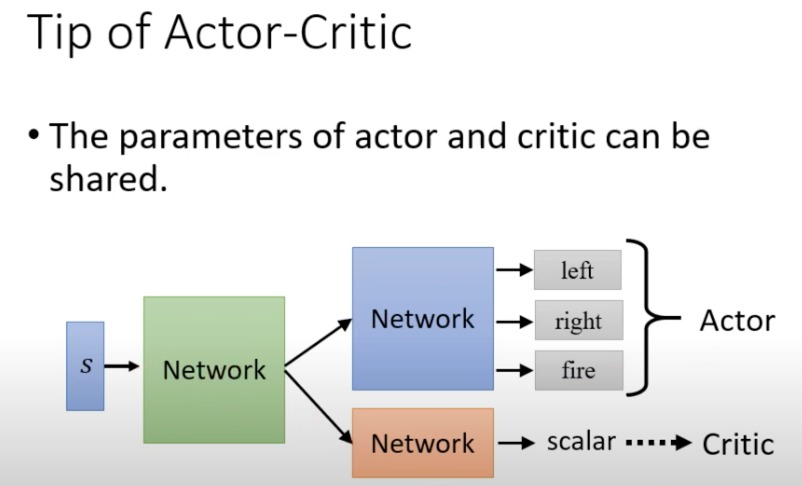
在Actor-Critic强化学习架构中,"Actor"和"Critic"是两种不同的网络组件,但它们可以共享一些参数:
-
Actor:负责选择动作的网络部分,它输出在给定状态下执行每个可能动作的概率。在上图中,Actor根据输入的状态 ( s ) 输出三个动作:“left”, “right”, 和 “fire”。
-
Critic:评估当前策略价值的网络部分,它输出一个标量值,表示当前状态或者状态-动作对的预期回报。Critic的输出有助于指导Actor的训练,通过评价Actor选取动作的好坏。
-
共享参数:Actor和Critic可以共享一些底层的网络参数。在这种情况下,一个单独的网络会首先处理输入状态 ( s ),然后分别为Actor和Critic生成特征表示。这种共享结构的好处是可以减少模型的总参数数量,同时让Actor和Critic能从相同的状态表示中学习,这可能会导致更快的学习和更好的泛化能力。
图中所示的“Tip of Actor-Critic”表明,在设计Actor-Critic网络时,可以让Actor和Critic共享一些(通常是底层的)网络层。这种方法被认为可以提高学习效率和减少所需的计算资源。
DQN
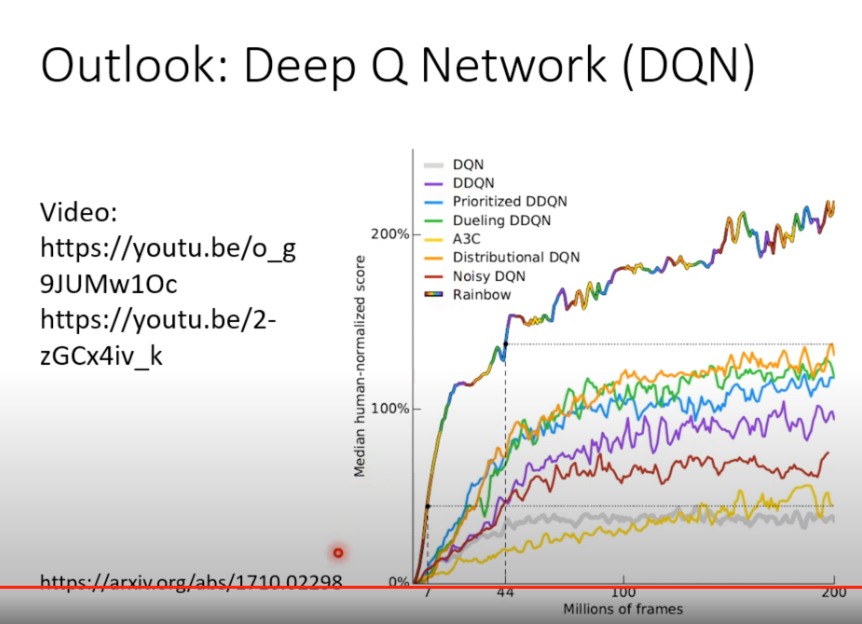
在RL中,有一种犀利的做法,是只知道Critic就可以决定Action。其中最知名的就是DQN
Reward Shaping
对于某些任务,假设reward几乎都是0,只有某些情况有巨大的reward。这时候我们就提供格外的reward帮助训练,叫做Reward Shaping。类似望梅止渴

- 举一个例子
- 一款射击游戏,额外添加的一些reward

-
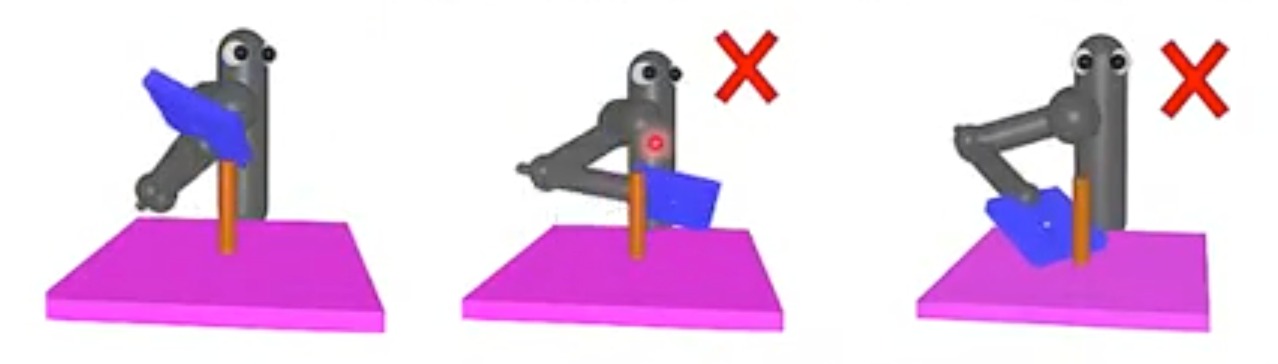
再举一个例子
- 训练机械手臂,只是将板子离棍子的距离越近作为新的reward,会造成一些错误
-
所以reward shaping需要较强的domain knowledge,对问题本身和环境有足够的见解。才能更好的使用。
No Reward:Learning from Demonstration
有时候人定的reward不见得是最好的,容易让机器产生出人类意想不到的结果。
所以在没有reward的时候,有一种训练方式Imitation Learning。
但是如果只是单纯的让机器模仿人类的动作,在机器能力有限的情况下,容易造成更大的问题,机器不知道哪些该学哪些不该学。
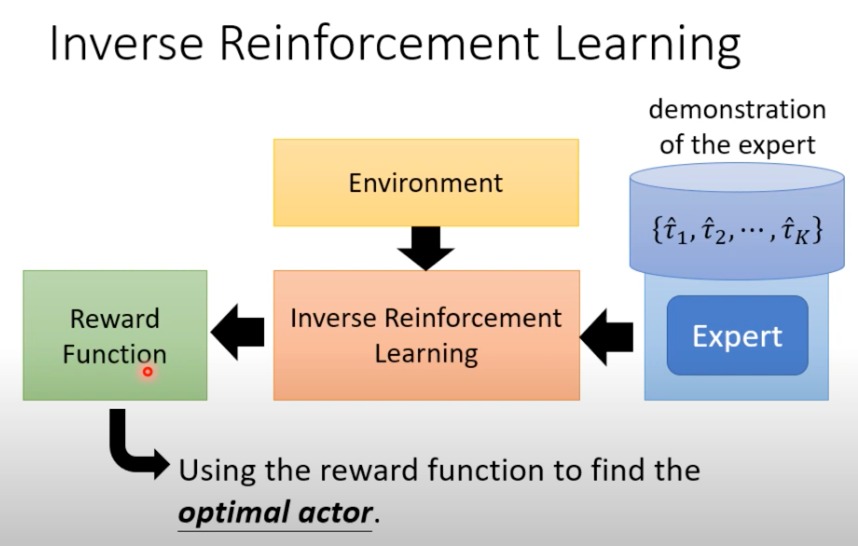
于是又有一个新的技术Inverse reinforcement learning,让机器自己定reward。
-
原来的
-
反转的
- 通过expert的掩饰,来反向学习出reward function
- 再通过这个function进行训练
-
举一个算法例子
- 初始化一个智能体(Actor):这个智能体会在环境中执行动作,试图模仿专家的行为。
- 交互:在每次迭代中,智能体与环境交互以获得轨迹,即一系列的状态和动作序列。
- 定义奖励函数:基于专家的轨迹,定义一个奖励函数,这个函数旨在使专家的轨迹看起来比智能体的轨迹更好,即奖励专家动作高于智能体的动作。
- 学习:智能体根据新定义的奖励函数学习并尝试最大化它的期望奖励,从而提升其行为策略贴近于专家。

-
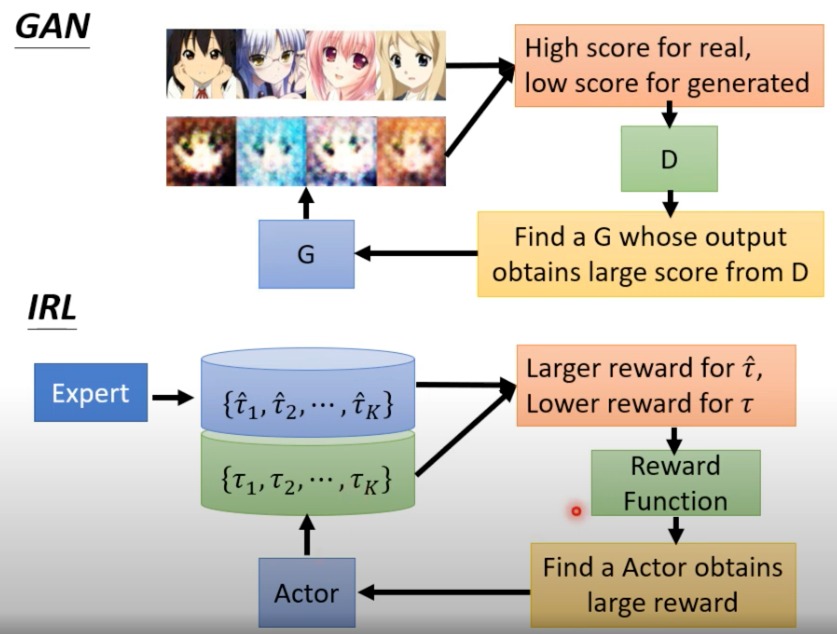
更加形象的表达这个过程
-
专家 ( π ∗ \pi^* π∗ ):这是执行任务的最佳方式的模型或实体。专家的策略 ( π ∗ \pi^* π∗ ) 生成了优化的轨迹集合 ( { τ 1 ∗ , τ 2 ∗ , . . . , τ K ∗ } \{\tau_1^*, \tau_2^*, ..., \tau_K^*\} {τ1∗,τ2∗,...,τK∗} ),这些轨迹表示在特定任务中的最佳行为序列。
-
奖励函数 R:IRL的目标是从专家的轨迹中推断出这个函数。奖励函数是一个映射,它将每一个轨迹映射到一个数值上,该数值表示轨迹的好坏。在这个框架中,我们希望找到一个奖励函数,使得专家轨迹的总奖励大于其他可能的轨迹 ($ \tau$ ) 的总奖励。
-
Actor ( $\pi $):一旦获得了奖励函数,就会使用强化学习来训练一个智能体(Actor),使其能够基于这个奖励函数采取行动。Actor在这里充当了Generator的角色,尝试生成与专家轨迹相似的行为。
-
生成器和鉴别器:这个概念类似于生成对抗网络(GAN)中的概念。智能体(Actor)作为生成器尝试生成数据(轨迹),而奖励函数在这里可以看作是鉴别器,用于区分生成的轨迹和专家轨迹的质量。
-

这篇关于【Hung-Yi Lee】强化学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






