本文主要是介绍【论文翻译】NLP—CogLTX: Applying BERT to Long Texts(使用BERT解决长文本问题),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
BERT不能处理长文本,因为它的内存和时间消耗呈二次增长。解决这个问题的最自然的方法,如用滑动窗口对文本进行切片,或者简化transformer,使用不充分的长范围attention,或者需要定制的CUDA内核。。BERT的最大长度限制提醒我们人类工作记忆的容量是有限的(5个∼9个区块),那么人类是如何认知长文本的呢?本文提出的CogLTX 框架基于Baddeley提出的认知理论,通过训练一个判断模型来识别关键句子,并将其串接进行推理,并通过排练和衰减实现多步骤推理。由于相关性注释通常是不可用的,我们建议使用干预来创建监督。作为一种通用算法,CogLTX在不依赖于文本长度的内存开销情况下,在各种下游任务上优于或获得与SOTA模型相当的结果。
介绍
由BERT开创的Pretrained语言模型已经成为处理许多NLP任务(例如机器阅读理解-问答和文本分类)的灵丹妙药。研究人员和工程师可以轻松地按照标准精细化范式构建最先进的应用程序,但最终可能会失望地发现一些文本的长度超过BERT的限制(通常是512个符号),这种情况在标准化基准测试中可能很少见,例如SQuAD【38】和GLUE【47】,但在更复杂的任务[53]或真实的文本数据中很常见。对于长文本,一个简单的解决方案是滑动窗口【50】,BERT处理连续的512个标记跨度。这种方法牺牲相距过远字符“相互映射(pay attention)”,这成为BERT在复杂任务(例如图1)显示其功效的瓶颈。因为问题的根源在高时间O (L2)和空间复杂性在transformers[46](L是文本的长度),另一条线的研究试图简化的结构transformers【20,37,8,42】,但目前他们已经成功地应用于BERT【35,4】。

BERT的最大长度限制很自然地提醒了我们有限容量的工作记忆[2]:一种人类的认知系统,用来存储逻辑推理和决策的信息。实验【27,9,31】已经表明,在阅读过程中,工作记忆仅能容纳5个~ 9个条目/单词,那么人类到底是怎么理解较长的文本的呢?正如Baddeley【2】在其1992年的经典著作中指出的那样,“中央执行器——(工作记忆)系统的核心,负责协调(多模式)信息”,然后,“功能类似于一个有限容量的注意力系统,能够选择和操作控制过程和策略”。后来的研究详细说明了工作记忆中的内容会随着时间的推移而衰减,除非是通过排演【3】来保存,即注意并刷新头脑中的信息。然后通过检索比较【52】,用长期记忆中的相关条目不断更新被忽略的信息,在工作记忆中收集足够的信息进行推理。BERT和工作记忆之间的类比启发我们用CogLTX框架像人类一样认知长文本。CogLTX背后的基本哲学是相当简洁的——对关键句子的串联进行推理(图2)——而紧凑的设计则需要在机器和人的推理过程之间架起桥梁。

CogLTX的关键步骤是MemRecall,即通过将文本块视为情景记忆来识别相关文本块的过程。 MemRecall模拟了工作记忆的检索竞赛、预演和衰退,便于多步骤推理。另一个BERT,称为judge,被引入来评分块的相关性,并与最初的BERT reasoner一起训练。此外,CogLTX还可以通过干预将面向任务的标签转换为相关性注释,以训练判断人员。我们的实验表明,CogLTX在包括NewsQA[44]、HotpotQA[53]、20个NewsGroups[22]和Alibaba在内的四个任务上优于或达到了相当的性能,无论文本长度如何,内存消耗都是恒定的。
背景
长文本的挑战。长文本的挑战。对长文本的直接和表面障碍是在BERT[12]中预先训练的最大位置嵌入通常为512。然而,即使提供了更大位置的嵌入,内存消耗也是难以承受的,因为所有的激活都存储在训练期间的反向传播。例如,一个1500-token文本需要大约14.6GB的内存才能运行bert -即使批量大小为1,也很大,超过了普通gpu的容量(例如,1个token文本)。11GB的RTX 2080ti)。此外,O(L2)空间复杂度意味着随着文本长度L的增加而快速增加。
相关的工作。如图1所示,滑动窗口法缺乏远距离关注。以前的工作[49,33]试图通过均值池、max-池或额外的MLP或LSTM来聚合每个窗口的结果;但这些方法在长距离交互时仍然很弱,需要O(5122·L/512) = O(512L)空间,这在实践中仍然太大,无法在批量大小为1的RTX 2080ti上训练2500令牌文本的BERT-large。此外,这些晚聚合方法主要是对分类进行优化,而其他任务,如广度提取,输出L BERT值,需要O(L2)空间进行自注意聚合。
在对transformer进行长文本改造的研究中,很多只是压缩或重复使用了之前步骤的结果,无法应用到BERT中,如Transformer- xl[8]、compression Transformer[37]。Reformer使用位置敏感的散列来实现基于内容的群组关注,但它对GPU不友好,仍然需要对BERT的使用进行验证。BlockBERT[35]砍掉不重要的注意力头,将BERT从512令牌提升到1024。最近的里程碑长前[4],定制CUDA内核,以支持窗口注意和全局注意的特殊令牌。然而,由于数据集大多在longformer窗口大小的4倍范围内,对后者的有效性的研究还不够充分。“轻量级BERTs”的方向很有前途,但与CogLTX是正交的,这意味着它们可以结合CogLTX来处理较长的文本,因此本文将不再对它们进行比较或讨论。详细的调查可以在[25]中找到。

方法
CogLTX方法:
CogLTX的这个基本假设是“对于大多数NLP任务来说,文本中的几个关键句子存储了足够和必要的信息来完成任务”。更具体地说,我们假设存在一个由长文本x中的一些句子组成的短文本z,满足

其中x+和z+是推理机BERT w.r.t的输入,文本x和z如图2所示。
我们通过动态编程(见附录)将每个长文本分割成块[x0 ... x(T-1],这将块长度限制为最大B,在我们的实现中,如果BERT长度限制为L = 512,则B = 63。关键短文本z应该由x中的若干块组成,即z = [xz0…xznn 1],满足len(z+)≤L且z0 <…< znn 1。我们用zi表示xzi。z中的所有块都会自动排序,以保持x中的原始相对顺序。
关键块假设与潜变量模型密切相关,潜变量模型通常用EM[11]或变分贝叶斯[19]求解。但是,这些方法估计z的分布,需要多次采样,对BERTs来说不够有效。我们将它们的精髓融入到CogLTX的设计中,并在§3.3中讨论了它们之间的联系。
在CogLTX中,MemRecall和两个BERTs的联合训练是必不可少的。如图2所示,MemRecall是利用判断模型检索关键块的算法,在推理过程中将关键块送入推理机完成任务。
MemRecall
当大脑回忆与工作记忆中当前信息相关的过去事件时,MemRecall的目的是从长文本x中提取关键块z(见图3)。
输入。尽管其目的是提取关键块,但三种任务类型的具体设置有所不同。在图2 (a) (c)中,问题Q或子序列x[i]作为查询,用于检索相关块。但是,(b)中没有查询,相关性仅由训练数据隐式定义。例如,包含“唐纳德·特朗普”或“篮球”的句子在新闻话题分类方面比时间报道句子更相关。那么如何无缝地统一这些案例呢?
MemRecall通过接受初始的z+作为x之外的附加输入来回答这个问题。z+是在MemRecall期间维护的简短“关键文本”,用来模拟工作记忆。任务(a)(c)中的查询成为z+中的初始信息,以引发回忆。然后,判断模型在z+的帮助下学习预测任务特定的相关性。
模型。MemRecall使用的唯一模型是上面提到的 judge,一个BERT来为每个标记评分相关性。假设z+ = [[CLS] Q [SEP]z0[SEP]…znn1),

区块zi的分数记为judge(z+)[zi],是该区块中token分数的平均值。
过程。MemRecall始于一场检索比赛。每个块xi分配一个粗关联评分judge([z+[SEP]xi])[xi]。得分最高的“胜者”块插入z, len(z+)≤l。向量空间模型[40]优于向量空间模型[40]的优势在于xi通过变压器与电流z+完全相互作用,避免了嵌入过程中的信息丢失。
接下来的排演衰减期赋予每个zi一个良好的相关性评分judge(z+)[zi]。只有得分最高的区块会被保存在z+中,就像工作记忆中的排演衰减现象一样。细分值的动机是,没有分块之间的交互和比较,粗分值的相对大小不够准确,类似于重新计算[7]的动机。
MemRecall本质上支持多步骤推理,通过使用新的z+重复这个过程。CogQA[13]强调了迭代检索的重要性,因为在多跳阅读理解中,答案句不能被问题直接检索。值得注意的是,如果z+中新块的更多信息证明它们的相关性不够强(得分较低),上一步保留的块也会衰减,而之前的多步推理方法忽略了这一点[13,1,10]。
训练
下流式任务的多样性对在CogLTX训练BERTs提出了挑战。
算法1总结了不同设置下的解。
Algorithm 1: The Training Algorithm of CogLTX (算法1:CogLTX的训练算法)

对judge进行监督培训。。《自然》中的跨度提取任务(图2(a))建议使用相应的答案块。即使是多跳数据集,例如HotpotQA[53],通常也会对支持句进行注释。在这些情况下,judge自然是在监督下接受训练的:
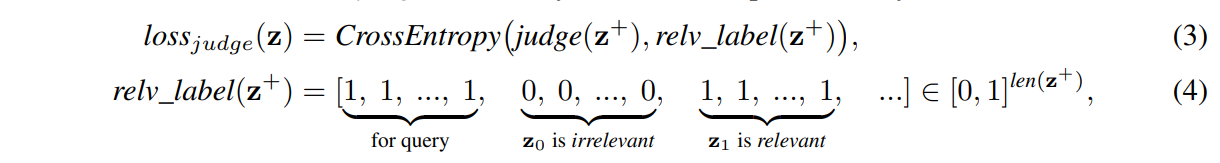
其中训练样本z要么是从x中采样的连续块Zrand序列(对应检索比赛的数据分布),要么是所有相关和随机选择的不相关块Zrelv的混合(近似于排练的数据分布)。
对reasoner进行监督培训。reasoner面临的挑战是如何在训练和推理过程中保持数据分布的一致性,这是监督学习的一个基本原则。理想情况下,reasoner的输入也应该由MemRecall在训练期间生成,但并不能保证所有相关块都能被检索到。例如在回答问题时,如果MemRecall漏掉了答案块,训练就不能进行。最后,近似地发送检索竞赛中所有相关块和“优胜者”块来训练reasoner。
对judge进行无监督培训。不幸的是,许多任务(图2 (b)(c))没有提供相关性标签。因为CogLTX假设所有相关的块都是必要的,所以我们通过干预推断出相关标签:通过从z中删除块来测试块是否是不可缺少的。
假设z是“oracle relevant blocks”,根据我们的假设,

其中Z-zi是z去除了zi的结果,t是一个阈值。在训练reassoner的每一次迭代后,我们切割z中的每个块,根据损失的增加调整其关联标签。不显著的增加表明区块是不相关的,它可能不会再次“赢得检索比赛”来训练推理机在下一个时代,因为它将被贴上不相关的标签来训练裁判。然后真正相关的块可能进入z下一个纪元并被检测出来。在实践中,我们将t分为up和down两部分,留出缓冲区域,以防止频繁更换标签。我们在图4中的20News文本分类数据集上展示了一个无监督训练的示例。

在第一阶段,judge几乎没有经过训练,随机选择一些方块。其中,(7)对正确分类贡献最大,标记为“relevant”。
在第二个时代,经过训练的judge发现(1)有强有力的证据证明“prayers”和(1)立刻被标记为“relevant”。那么在下一个时代,(7)就不再是分类的必要条件,被标记为“irrelevant”。
与潜在变量模型的连接。无监督CogLTX可以看作是(条件)潜变量模型p(y|x;θ)∝p (z | x) p (y | z;θ)。EM[11]推断z的分布为后验p(z|y, x;E-step中的θ),而变分bayes方法[19,3]使用一个估计友好的q(z|y, x)。然而,在CogLTX中z是一个离散分布,其可能值高达Cnm,其中n, m分别是块数和z的容量。在某些情况下,为了训练BERTs,可能需要进行数百次抽样,其昂贵的时间消耗迫使我们转向z的点估计2,例如,我们基于干涉的方法。
干预解决方案维护每个x的z估计,本质上是一个特定于CogLTX的本地搜索。z是通过比较附近的值(替换不相关块后的结果)而不是Bayesian规则来优化的。Judge采用归纳判别模型来帮助推断出z。
实验
我们在四个不同任务的长文本数据集上进行了实验。token-wise(图2 (c))任务不包括从相邻的句子,因为他们大多仅仅需要信息并最终转化为多个sequence-level山姆 pl。图5中的箱线图显示了数据集中文本长度的统计信息。

在所有实验中,judge和reasoner由Adam[18]优化,学习速率分别为4×1005和1004。在前10%的步骤中,学习率开始升温,然后线性衰减到最大学习率的1/10。常用的超参数为batch size = 32, strides= [3, 5], tup = 0.2,当count =0.05。
在本节中,我们将分别介绍每一项任务以及相关的结果、分析和消融研究。
阅读理解
数据集和设置。给定一个问题和一段话,任务是预测在这段话中的回答跨度。我们评估了CogLTX在NewsQA[44]上的性能,NewsQA[44]包含119,633个人工生成的问题,在12,744篇长新闻文章中提出。3由于之前的SOTA[43]在NewsQA中不是基于BERT的(由于文本较长),为了保持相同的参数规模进行公平比较,我们在CogLTX中对RoBERTa[26]的基础版本进行了4个时期的调整。
结果。表1显示,CogLTX-base优于已经建立的QA模型,例如BiDAF [41] (+17.8% F1),先前的SOTA DECAPROP[43](包含精心的自我注意和RNN机制(+4.8%F1),甚至是带滑动窗口的RoBERTa-large (+4.8%F1)。我们假设第一句话(导语)和最后一句话(结论)通常是新闻文章中信息量最大的部分。CogLTX可以聚合它们进行推理,而滑动窗口不能。

Multi-hop question answering
数据集和设置。在复杂的情况下,答案是基于多个段落。以前的方法通常利用段落中关键实体之间的图结构[13,36]。然而,如果我们可以使用CogLTX处理较长的文本,那么通过将所有段落作为BERTs的输入连接起来,就可以很好地解决这个问题。
HotpotQA[53]是一个包含112,779个问题的多跳QA数据集,其distractor设置为每个问题提供了2个必要的段落和8个distractor段落。答案和支持性事实都是评估所需要的。在CogLTX中,我们将每个句子视为一个块,并直接输出分数最高的2个块作为支持事实。
结果。表2显示,CogLTX优于之前的大多数方法和排行榜上的所有7个BERT变体解决方案。

SOTA模型HGN[14]利用了维基百科中额外的超链接数据,数据集是基于这些超链接数据构建的。SAE[45]的思想与CogLTX类似,但不太通用。它通过BERTs的注意层对段落进行评分,选择得分最高的两段,并将它们一起提供给BERT。支持事实是由另一个复杂的图表注意模型决定的。由于定向设计良好,SAE比CogLTX(2.2%联合F1)更适合HotpotQA,但不能解决较长段落的内存问题。CogLTX像普通QA一样直接解决多跳QA问题,得到sota可比的结果,无需额外努力就能解释支持事实。
Ablation的研究。我们还总结了表2中的消融研究,表明
(1)多步推理确实有效(+3.9%关节F1),但不是必要的,可能是因为HotpotQA中的许多问题本身与第二跳句子足够相关,可以检索它们。
(2)在未进行预演的情况下,支持事实的指标显著下降(-35.7% Sup F1),这是因为最高句之间的相关性得分不具有可比性。
(3)如§3.3所述,如果推理机采用随机选择的块进行训练,则训练和测试过程中数据分布的差异会影响性能(-2.3%联合F1)。
文本分类
数据集和设置。文本分类是自然语言处理中最常见的任务之一,它对主题、情感、意图等进行分析是必不可少的。我们在经典的20个新闻组[22]上进行实验,该新闻组包含来自20个类的18,846个文档。我们给罗伯塔安排了6个时代的CogLTX。
结果。表3表明,CogLTX的相关性标签是由Glove[34]初始化的,它的性能优于其他基线,包括先前尝试从滑动窗口[33]聚合[CLS]池结果的结果。此外,基于MLP或LSTM的聚合既不能对长文本进行端到端训练。
Ablation的研究。
(1)由于20个新闻组中的文本长度差异很大(见图5),我们只在大于512的文本上进一步测试性能
(2)基于Glove的初始化虽然提供了较好的相关性标签,但由于没有进行干预调整,仍然导致准确率下降了2.2%。
(3) Bm25初始化基于常用语,由于标签名较短,只初始化了14.2%的训练样本,如sports.baseball。通过干预和逐步训练推理器推断相关句子,准确率达到86.1%。

Multi-label classifification
数据集和设置。在许多实际问题中,每个文本可以同时属于多个类别。多标签分类通常通过为每个标签训练一个单独的分类器来转化为二分类。由于BERT容量大,我们共享所有标签的模型,方法是在文档开头添加标签名作为输入,即[[CLS] label [SEP] doc],用于二进制分类。阿里巴巴是从一个大型电子商务平台的行业场景中提取的3万篇文章的数据集。每篇文章都有67个类别的几个项目的广告。上述类别的检测被完美地建模为多标签分类。为了加快实验速度,我们分别抽样8万对和2万对标签-条目对进行训练和测试。为了完成这个任务,我们在CogLTX找到了RoBERTa。
结果。表4显示了CogLTX优于普通的强基线。TextCNN[17]和Bi-LSTM使用的单词embeddings来自RoBERTa,为了公平比较。即使CogLTX-tiny (7.5M参数)也优于TextCNN。但是,RoBERTa-large滑动窗口的max-pooling结果却不如CogLTX (7.3% Macro-F1)。我们假设这是由于在max-pooling中倾向于给非常长的文本分配更高的概率,突出了CogLTX的效力。

内存和时间消耗
内存。CogLTX的内存消耗在训练期间是恒定的,优于香草BERT的O(L2)复杂性。我们还比较了longformer[4],如果全局注意令牌的数量相对于L较小且不依赖于L,则其空间复杂度大致为O(L)。图6(左)总结了详细的比较。
时间。为了加快推理机的训练,我们可以在训练判断时缓存分块的分数,这样每个epoch只需要2倍的单bert训练时间。由于CogLTX和滑动窗口在训练中直到收敛的epochs数目相似,CogLTX主要关注推理的速度。图6(右)显示了处理10万例不同文本长度的合成数据集的时间。CogLTX的时间复杂度为O(n),在L > 2048之后比香草BERT快,并随着文本长度L的增长接近滑动窗口的速度。

结论与讨论
我们提出了CogLTX,一种将BERT应用于长篇文本的认知启发框架。在训练中,CogLTX只需要固定的记忆,可以在遥远的句子之间进行关注。类似的想法也在DrQA[6]和ORQA[23]的文档级进行了研究,之前也有以非监督方式提取重要句子的工作,如基于结构[24]的元数据。在4个不同的大数据集上的实验表明了该算法的有效性。CogLTX有望成为许多复杂NLP任务的一个通用的、强有力的基线。
CogLTX在“关键句子”假设下定义了一个用于长文本理解的管道。非常困难的序列级任务可能会违反它,因此高效的变分贝叶斯方法(估计z分布)与负担得起的计算仍然值得研究。此外,CogLTX在块前遗漏前件的缺点是,在我们的HotpotQA实验中,在每个句子前添加实体名称来缓解这一问题,未来可以通过位置感知检索竞赛或共指解析来解决。
备注:请结合原论文践行阅读,本博客仅涉及翻译,初次读论文可能有些地方翻译的不正确,请提出来呢,论文详解会在后续进行补充
论文地址:http://keg.cs.tsinghua.edu.cn/jietang/publications/NIPS20-Ding-et-al-CogLTX.pdf
这篇关于【论文翻译】NLP—CogLTX: Applying BERT to Long Texts(使用BERT解决长文本问题)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



