本文主要是介绍【Deeplearning4j】小小的了解下深度学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 起因
- 2. Deeplearning4j是什么
- 3. 相关基本概念
- 4. Maven依赖
- 5. 跑起来了,小例子!
- 6. 鸢尾花分类
- 代码
- 7. 波士顿房价 回归预测
- 代码
- 8. 参考资料
1. 起因
其实一直对这些什么深度学习,神经网络很感兴趣,之前也尝试过可能因为Java做这个不成熟或者其他什么原因但是没开始。这次,从Jone到TensorFlow到Deeplearning4j(DL4j)试了好几种,最终选了DL4j。
2. Deeplearning4j是什么
深度学习是一个极具吸引力的新领域,尤其是在 计算机视觉Q、自然语言处理等领域。目前,业界热议的有基手TensorFlow、Caffe、Theano枸建的开源深度学习框架,还有基于Spark构建的分布式、高性能的神经网络平台。而近年来,基于多种深度学习框架的开源工具如Keras、Torch、MxNet等越来越火爆。但是,这些框架各不兼容,很难构建复杂的深度学习模型。为解决这个问题,业界提出了另一种思路——用统一的JavaAP!构建统一的深度学习框架,使得不同深度学习框架可以方便地互联互通。从此,Deeplearning4j诞生了!
Deeplearning4j(简称DL4J)是Apache顶级项目,面向机器学习和深度学习开发者提供一个开源、商业级、健壮的平台。已是基于JVM (Java Virtual Machine) 的框架,支持Java、Scala及其他语言编写的代码。它的主要功能包括:
- 交叉语言接口:支持多种编程语言,包括Java、Scala、Python、C++、尺等;
2.向量化计算:支持高度优化的矢量化计算,同时也兼顾易用性;
3.自动微分:支持自动求导,并针对各类机器学习任务进行优化;
4.深度学习模型库:包括卷积网络、循环网络、递归网络等;
5.可扩展性:提供了便利的组件模型,并且允许用户自定义组件;
6.分布式计算:通过Spark、Hadoop等计算框架可实现海量数据的分布式运算;
7.模型训练工具:提供了命令行工具和图形界面工具,让用户快速上手;
8.文档和示例代码:提供详尽的文档和丰富的示例代码,帮助用户快速入门。
3. 相关基本概念
列举了后面代码可能遇到的
3.1.神经网络(Neural Network)
神经网络(neural network)是由大量感知器组织起来的集成系统,每个感知器具有多个输入和输出连接,根据一定规则对其输入信号做加权处理,然后送给输出单元,产生一个输出信号。一个简单的神经元可以看作是—个具有单个阅值的线性分类器,它接受多个输入信号并决定是否激活,将信号传播至输出层。神经网络中的感知器可以互相连接,构成一个多层结构。深度学习中的神经网络通常具有多层结构,其中隐藏层的数量和各层节点的数量是手动设定的。
3.2.反向传播算法(Backpropagation algorithm)
反向传播算法是指用来更新神经网络参数的最常用的方法之一。每一次选代中,从最后一层往回迭代,首先计算当前层的误差值,然后依据误差和权重更新前一层的参数,直到更新完整个网络。反向传播算法相当于一个链式法则,将权重与误差传播给每一层,并根据这一链式法则更新权重,最终达到合理的训练结果。
3.3.梯度下降算法(Gradient Descent Algorithm)
梯度下降算法是反向传播算法的基础,它是利用误差最小化的方法来确定参数的最优解。具体来说,梯度下降算法以损失函数对参数的偏导数作为搜索方向,沿着该方向递减参数,直到找到全局最优解。梯度下降算法在每次迭代中计算出代价函数在当前参数处的梯度,根据梯度更新参数,直到得到局部最优解。
3.4.激活函数(Activation function)
激活函数 (activation function)是神经网络的关键组件之一。它作用在每一个非线性变换之后,用来修正线性组合的输出,使其成为非线性的。常用的激活函数有sigmoid函数、tanh函数、ReLU函数和softmax函数。
3.5.损失函数(Loss Function)
损失函数 (loss function)是描述神经网络性能的指标。神经网络的目标是最小化损失函数的值,以达到良好的性能。常用的损失函数有均方误差函数(mean squared error)、交叉熵函数 (cross entropy)
4. Maven依赖
不多废话,直接给能跑的代码
本人使用环境 MacOS 13.1 JDK 1.8
首先,在Windows/Linux/Mac 系统上,操作系统需要 64 位的(早期的版本支持 32 位,但由于训练深度神经网络需要大量内存,而 32 位系统访问内存有限,因此后期的版本只支持 64 位系统)。
其次,由于 Deeplearning4j 是基于 JVM 的框架,因此JDK 必须安装,JDK 版本推荐 1.7以上。由于篇幅关系,这里不再赘述JDK 的相关安装,请读者自行阅读Oracle 相关文档进行安装和相关环境变量的设置。
再者,DeepLearnina 依赖以及间接依赖的库很多,比如 JavaCPP、JavaCV、Guava、Spark 等。所以我们需要用类似 Maven 的jar 包管理工具进行依赖的引入。
在DL4j版本上进行过多次选择 一开始直接1.0.0-beta7 → 0.8.0 →0.9.0→0.9.1→1.0.0-beta4
因为有很多周边配置或者依赖或者机器(Apple M1 Pro)arm原因,目前是beta4(2023.12.02)
注意:但是以下两个例子需要0.8.0的版本,所以使用0.8.0,后面MNIST手写数据识别,会修改为1.0.0-beta4
为了怕遗漏,我就把我的相关依赖全放上去了(要下挺久)
<properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><dl4j.version>0.8.0</dl4j.version><nd4j.version>0.8.0</nd4j.version><spark.version>2</spark.version><datavec.version>0.8.0</datavec.version><scala.binary.version>2.11</scala.binary.version></properties><!--deeplearning4j--><dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-core</artifactId><version>${dl4j.version}</version></dependency><dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-nn</artifactId><version>${dl4j.version}</version></dependency><dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-zoo</artifactId><version>0.9.0</version></dependency><dependency><groupId>org.nd4j</groupId><artifactId>nd4j-native-platform</artifactId><version>${nd4j.version}</version></dependency><dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-ui_${scala.binary.version}</artifactId><version>${dl4j.version}</version></dependency><dependency><groupId>org.datavec</groupId><artifactId>datavec-api</artifactId><version>${datavec.version}</version></dependency><dependency><groupId>org.datavec</groupId><artifactId>datavec-data-image</artifactId><version>${datavec.version}</version></dependency><dependency><groupId>org.datavec</groupId><artifactId>datavec-spark_${scala.binary.version}</artifactId><version>${dl4j.version}_spark_2</version></dependency><dependency><groupId>org.nd4j</groupId><artifactId>nd4j-native</artifactId><version>${dl4j.version}</version></dependency><dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-scaleout-parallelwrapper-parameter-server</artifactId><version>${dl4j.version}</version></dependency>
如果下不了,可以在pom.xml project标签下新增(存在就看着替换)仓库
<repositories><repository><id>tensorflow-maven-repo</id><url>https://repo.maven.apache.org/maven2/</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>tensorflow-snapshots</id><url>https://oss.sonatype.org/content/repositories/snapshots/</url><snapshots><enabled>true</enabled></snapshots></repository></repositories>
5. 跑起来了,小例子!
直接跑 ,超简单的小例子(加法)
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;import java.io.IOException;public class ND4j_create {public static void main(String[] args) throws IOException{System.out.println(Nd4j.getBackend());INDArray tensor1 = Nd4j.create(new double[]{1,2,3});INDArray tensor2 = Nd4j.create(new double[]{10.0,20.0,30.0});System.out.println(tensor1.add(tensor2));}
}
6. 鸢尾花分类
以下俩例子,仅模型训练来自参考资料2的付费课程(提醒下文章中在线图片都过期了,有会员的可以看看)
两个例子所需文件在文章顶部,无需积分
也可以直接去参考资料3,下载官网demo
鸢尾花是广泛分布于温带的一种植物,在中国国内也种植有大量的鸢尾花,据百度百科—一鸢尾花词条中记录的信息表明,鸢尾花的种类有 13种之多。
鸢尾花数据集是由 R.A.Fisher 收集的关于 3种鸢尾花 (lris Setosa、Iris Versicolour 和 Iris Virginica) 且每一个种类有 50 条记录的开源数据集。
数据集中的每条记录共包含 4 个维度(萼片长度、萼片宽度、花瓣长度和花瓣宽度),部分数据集的截图如下:
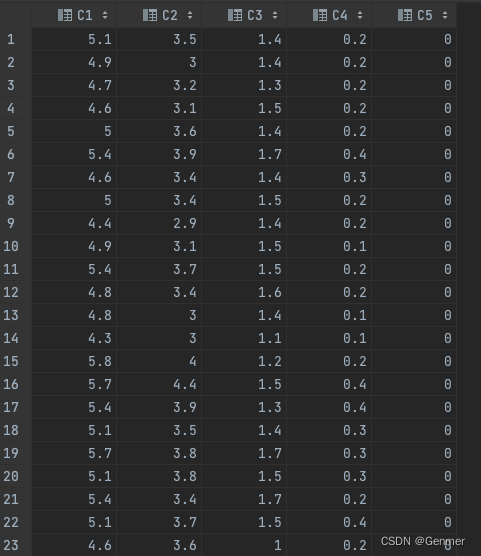
需要注意的是,最后一列表示鸢尾花类别的例子是文本的,因此为了方便之后训练数据集的构建,我们将最后一列统一替换成数字(用数字 0、1、2分别标识三种类别的鸢尾花)。
代码
以下代码中说的单核多核,在现在的版本好像没什么区别了,默认好像就是多线程的
import org.deeplearning4j.api.storage.StatsStorage;
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.eval.Evaluation;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.Updater;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.ui.api.UIServer;
import org.deeplearning4j.ui.stats.StatsListener;
import org.deeplearning4j.ui.storage.InMemoryStatsStorage;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;/*** 鸢尾花: http://archive.ics.uci.edu/dataset/53/iris** 本Demo需要在 0.8.0版本才能跑,1.0.0-beta4 一堆问题*/
public class MLPClassifyLris {private final static int numClasses= 3;private final static String TRAIN_DATA_PATCH = "src/main/resources/training/iris.csv";// 模型保存路径(注意模型无后缀 lris_model就是我起的模型名称,这和后面版本不一样,后面是zip后缀)private final static String MODEL_PATCH = "your path/lris_model";public static void training() throws IOException {/*--------------超参数常量声明------------------*/final int batchSize = 3;final long SEED = 1234L;final int trainSize = 120;/*--------------数据集构建------------------*/List<DataSet> irisList = loadIrisSeq(new File(TRAIN_DATA_PATCH));
// merge(irisList,batchSize);DataSet allData = DataSet.merge(irisList);allData.shuffle(SEED);SplitTestAndTrain split = allData.splitTestAndTrain(trainSize);DataSet dsTrain = split.getTrain();DataSet dsTest = split.getTest();DataSetIterator trainIter = new ListDataSetIterator(dsTrain.asList() , batchSize);DataSetIterator testIter = new ListDataSetIterator(dsTest.asList() , batchSize);// 设置UI页面UIServer uiServer = UIServer.getInstance();StatsStorage statsStorage = new InMemoryStatsStorage();uiServer.attach(statsStorage);// 加载模型MultiLayerNetwork mlp = model();mlp.setListeners(new StatsListener(statsStorage));mlp.setListeners(new ScoreIterationListener(1)); //loss score监听器// 单(核)CPUfor( int i = 0; i < 20; ++i ){mlp.fit(trainIter); //训练模型trainIter.reset();Evaluation eval = mlp.evaluate(testIter); //在验证集上进行准确性测试System.out.println(eval.stats());testIter.reset();}ModelSerializer.writeModel(mlp, new File(MODEL_PATCH), true); //save model}public static List<DataSet> loadIrisSeq(File file) throws IOException {BufferedReader br = new BufferedReader(new FileReader(file));String line = null;List<DataSet> trainDataSetList = new LinkedList<DataSet>();while( (line = br.readLine()) != null ){String[] token = line.split(",");double[] featureArray = new double[token.length - 1];double[] labelArray = new double[numClasses];for( int i = 0; i < token.length - 1; ++i ){featureArray[i] = Double.parseDouble(token[i]);}labelArray[Integer.parseInt(token[token.length - 1])] = 1.0;//INDArray featureNDArray = Nd4j.create(featureArray);INDArray labelNDArray = Nd4j.create(labelArray);trainDataSetList.add(new DataSet(featureNDArray, labelNDArray));}br.close();return trainDataSetList;}public static List<DataSet> merge(List<DataSet> seq, int batchSize){int count = 0;List<DataSet> miniBatchSeq = new LinkedList<DataSet>();List<DataSet> tempSeq = new LinkedList<DataSet>();for( DataSet ds : seq ){if( count == batchSize ){miniBatchSeq.add(DataSet.merge(tempSeq));tempSeq.clear();count = 0;}tempSeq.add(ds);++count;}if( !tempSeq.isEmpty() ){miniBatchSeq.add(DataSet.merge(tempSeq));}return miniBatchSeq;}public static MultiLayerNetwork model(){MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder().seed(12345)
// .iterations(1) // Training iterations as above 0.9.1 ok | 1.0.0 X
// .learningRate(0.01).weightInit(WeightInit.XAVIER).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).updater(Updater.ADAM).list().layer(0, new DenseLayer.Builder().activation(Activation.LEAKYRELU).nIn(4).nOut(2).build()).layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD).activation(Activation.SOFTMAX).nIn(2).nOut(3).build());MultiLayerConfiguration conf = builder.build();MultiLayerNetwork model = new MultiLayerNetwork(conf);model.init();return model;}public static void main(String[] args) throws IOException, InterruptedException {training();}}
如无意外,结果为:
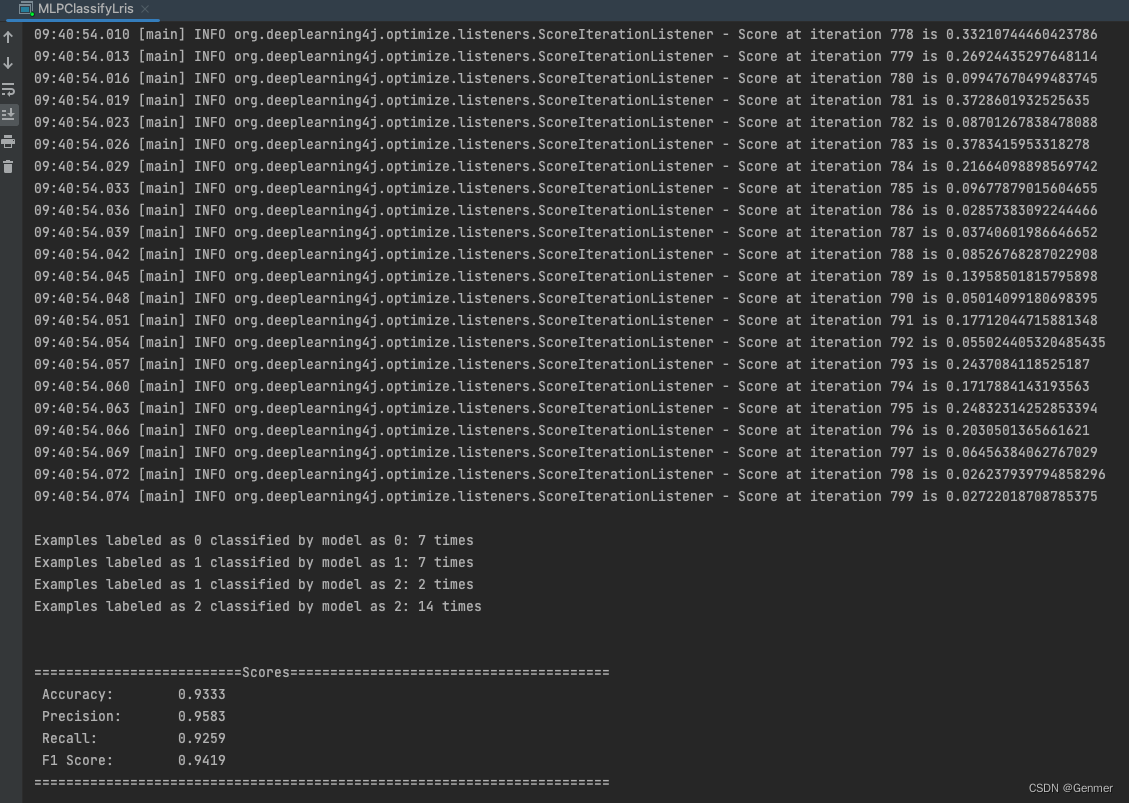
准确率(Accuracy)为 0.9333,表示模型正确预测的样本比例约为 93.33%。
精确率(Precision)为 0.9583,表示模型在预测为正类的样本中,正确预测为正类的比例约为 95.83%。
召回率(Recall)为 0.9259,表示模型在所有正类样本中,正确预测为正类的比例约为 92.59%。
F1 分数(F1 Score)为 0.9419,综合考虑了精确率和召回率的综合指标,越接近 1 表示模型的性能越好。
然后你设定的路径上会多一个模型文件

这里两个例子为就不使用模型了,我是在后面的MNIST才开始使用的
7. 波士顿房价 回归预测
前面说分类,好理解,那什么是回归
回归分析是一种统计分析方法,用于研究变量之间的关系和预测一个变量(称为因变量)的值,基于其他变量(称为自变量)的值。它旨在寻找自变量与因变量之间的关联,并使用这种关联来预测因变量的值。
回归分析的目标是建立一个数学模型,该模型可以描述自变量与因变量之间的函数关系。常见的回归分析方法包括线性回归、多项式回归、逻辑回归等。
在回归分析中,通常假设自变量与因变量之间存在某种线性或非线性关系。通过分析数据样本,回归分析可以估计出模型的参数,从而预测因变量的值。
回归分析在许多领域中都有广泛的应用,包括经济学、金融学、社会科学、医学、工程等。它可以帮助研究人员了解变量之间的关系、预测未来的趋势和行为,并支持决策和策略制定。
总而言之,回归分析是一种用于研究变量关系和预测因变量的统计分析方法,它是统计学和数据分析中常用的工具之一。
(所需数据在文章顶部,有资源链接,无需积分)

代码
package cn.genmer.test.security.machinelearning.deeplearning4j.begin;import org.deeplearning4j.api.storage.StatsStorage;
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.eval.RegressionEvaluation;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.ui.api.UIServer;
import org.deeplearning4j.ui.storage.InMemoryStatsStorage;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.NormalizerMinMaxScaler;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;/*** 波士顿房价: http://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html* 本Demo需要在 0.8.0版本才能跑,1.0.0-beta4 一堆问题*/
public class MLPRetuenTheBostonHousingDataset {private final static String TRAIN_DATA_PATCH = "src/main/resources/training/boston-house-price.csv";private final static String MODEL_PATCH = "your path/bostonHousing_model";public static void training() throws IOException {final int batchSize = 4;final long SEED = 1234L;final int trainSize = 400;List<DataSet> housePriceList = loadHousePrice(new File(TRAIN_DATA_PATCH));//获取全部数据并且打乱顺序DataSet allData = DataSet.merge(housePriceList);allData.shuffle(SEED);//划分训练集和验证集SplitTestAndTrain split = allData.splitTestAndTrain(trainSize);DataSet dsTrain = split.getTrain();DataSet dsTest = split.getTest();DataSetIterator trainIter = new ListDataSetIterator(dsTrain.asList() , batchSize);DataSetIterator testIter = new ListDataSetIterator(dsTest.asList() , batchSize);//归一化处理DataNormalization scaler = new NormalizerMinMaxScaler(0,1);scaler.fit(trainIter);scaler.fit(testIter);trainIter.setPreProcessor(scaler);testIter.setPreProcessor(scaler);//声明多层感知机MultiLayerNetwork mlp = model();mlp.setListeners(new ScoreIterationListener(1));// 设置UI页面UIServer uiServer = UIServer.getInstance();StatsStorage statsStorage = new InMemoryStatsStorage();uiServer.attach(statsStorage);//训练200个epochfor( int i = 0; i < 200; ++i ){mlp.fit(trainIter);trainIter.reset();}//利用 Deeplearning4j 内置的回归模型分析器进行模型评估RegressionEvaluation eval = mlp.evaluateRegression(testIter);System.out.println(eval.stats());testIter.reset();//输出验证集的真实值和预测值System.out.println("真实值:");System.out.println(testIter.next(testIter.totalExamples()).getLabels());System.out.println();testIter.reset();System.out.println("预测值:");System.out.println(mlp.output(testIter));testIter.reset();ModelSerializer.writeModel(mlp, new File(MODEL_PATCH), true); //save model}public static List<DataSet> loadHousePrice(File file) throws IOException {BufferedReader br = new BufferedReader(new FileReader(file));String line = null;List<DataSet> totalDataSetList = new LinkedList<DataSet>();while( (line = br.readLine()) != null ){String[] token = line.split(",");double[] featureArray = new double[token.length - 1];double[] labelArray = new double[1];for( int i = 0; i < token.length - 1; ++i ){featureArray[i] = Double.parseDouble(token[i]);}labelArray[0] = Double.parseDouble(token[token.length - 1]);//INDArray featureNDArray = Nd4j.create(featureArray);INDArray labelNDArray = Nd4j.create(labelArray);totalDataSetList.add(new DataSet(featureNDArray, labelNDArray));}br.close();return totalDataSetList;}public static List<DataSet> merge(List<DataSet> seq, int batchSize){int count = 0;List<DataSet> miniBatchSeq = new LinkedList<DataSet>();List<DataSet> tempSeq = new LinkedList<DataSet>();for( DataSet ds : seq ){if( count == batchSize ){miniBatchSeq.add(DataSet.merge(tempSeq));tempSeq.clear();count = 0;}tempSeq.add(ds);++count;}if( !tempSeq.isEmpty() ){miniBatchSeq.add(DataSet.merge(tempSeq));}return miniBatchSeq;}public static MultiLayerNetwork model(){MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder().seed(12345L)
// .iterations(1)
// .updater(Updater.ADAM).weightInit(WeightInit.XAVIER).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).list().layer(0, new DenseLayer.Builder().activation(Activation.LEAKYRELU).nIn(13).nOut(10).build()).layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.MEAN_SQUARED_LOGARITHMIC_ERROR).activation(Activation.IDENTITY).nIn(10).nOut(1).build());
// .backprop(true).pretrain(false);MultiLayerConfiguration conf = builder.build();MultiLayerNetwork model = new MultiLayerNetwork(conf);model.init();return model;}public static void loadModelAndPredict(INDArray feature) throws IOException{MultiLayerNetwork reloadModel = ModelSerializer.restoreMultiLayerNetwork(new File(MODEL_PATCH));reloadModel.predict(feature);}public static void main(String[] args) throws IOException, InterruptedException {training();}}
执行结果


8. 参考资料
- 介绍来自 Deeplearning4j: 用 Java 实现深度学习框架
- 鸢尾花 & 波士顿房价预测 多层感知机在结构化数据中的应用实现
- Deeplearning4j官网项目地址 有demo
这篇关于【Deeplearning4j】小小的了解下深度学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








