本文主要是介绍Hadoop学习笔记(HDP)-Part.08 部署Ambari集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
八、部署Ambari集群
1.Ambari数据库
【hdp01】创建Ambari数据库
create database ambari character set utf8;
create user 'ambari'@'%' identified by 'Ambari123456';
grant all privileges on ambari.* to 'ambari'@'%';
flush privileges;
2.部署Ambari-Server
【hdp01】yum安装ambari-server服务
yum install -y ambari-server
下载mysql-connector-java压缩包,创建/usr/share/java目录并将java-connector复制到该目录下
下载链接:
https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.49.tar.gz
mkdir /usr/share/java
cp /opt/mysql-connector-java-5.1.49.jar /usr/share/java
自动化设置Ambari
ambari-server setup
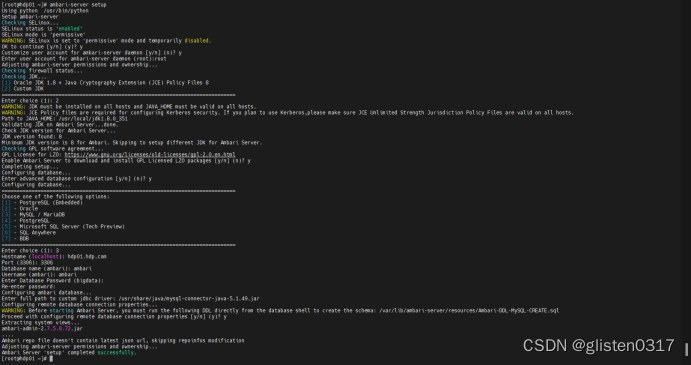
密码:Ambari123456
登录Ambari数据库,导入Ambari相关表
mysql -uambari -pAmbari123456
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;
启动ambari-server服务
ambari-server start
ambari-server status
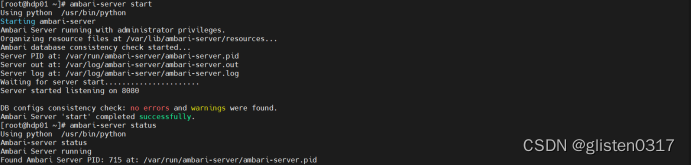
3.部署Ambari-Agent
在hdp01-hdp05节点上部署Ambari-Agent
【hdp01】通过anbile完成安装并启动,/root/ansible/ambari-agent.yml
---
- hosts: alltasks:- name: install ambari-agentyum:name: ambari-agentstate: present- name: start ambari-agentservice:name: ambari-agentstate: started
执行
ansible-playbook ambari-agent.yml
确认状态
ansible all -m shell -a 'ambari-agent status'
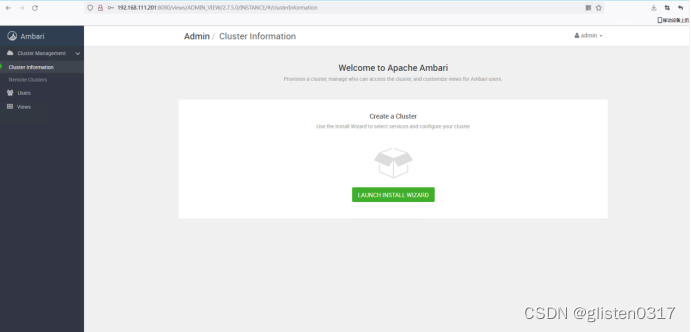
登录页面
Ambari-server页面链接:http://192.168.111.201:8080/#/login
初始密码:admin/admin
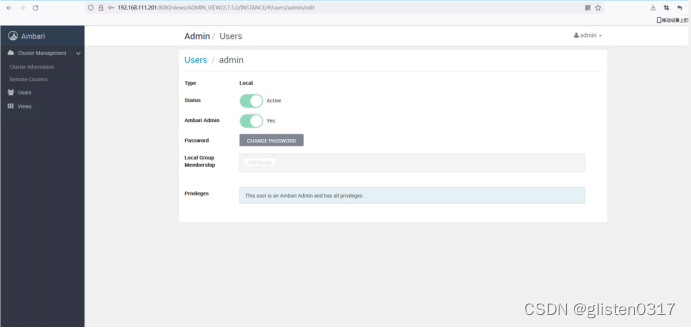
修改admin用户的缺省密码为lnyd@LNsy115
这篇关于Hadoop学习笔记(HDP)-Part.08 部署Ambari集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






