本文主要是介绍【模型可解释性系列一】树模型-拿到特征重要度-打印关键因素,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接下来一段时间内,会主要介绍下模型可解释性方向的一些常用方法。
模型可解释性:主要用来解释为什么这个样本的特征是这样的时候,模型结果是那样。面向老板汇报工作(尤其是不懂算法的老板)和业务方。
常用的树模型
xgboost、lightgbm这两个模型经常被使用,具体原理不讲了,可以巴拉一下之前的博客,为了面试曾经很认真的推导整理过资料,已经放在博客上,与有缘人共享。
主要使用内容:
一:特征重要度
训练好模型后:添加代码:print(model.feature_importances_)。会打印出特征重要度。
形如下图:
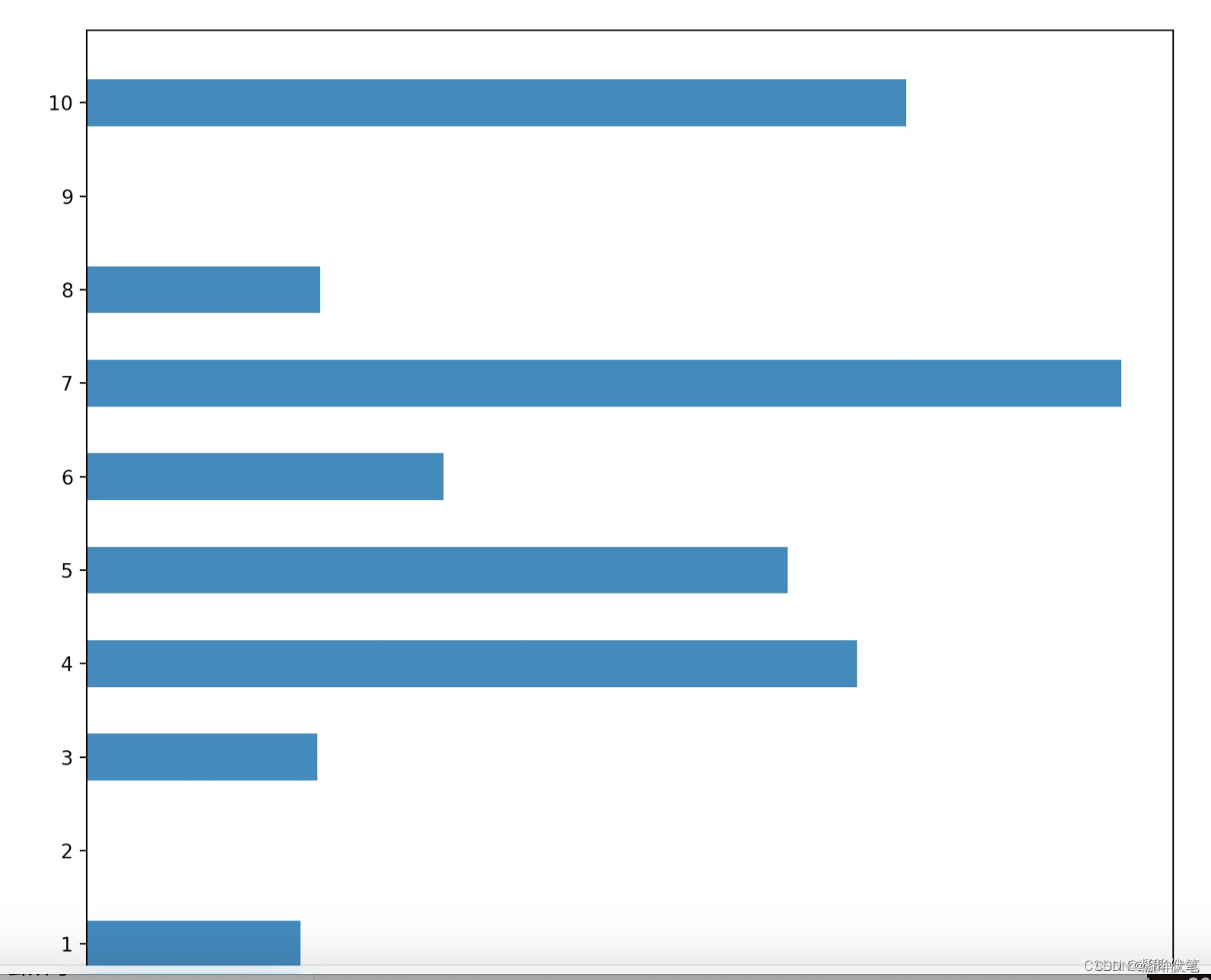
为了方便对比,大家可以对特征重要度排序,标注特征名。
二:树结构
形如下图:
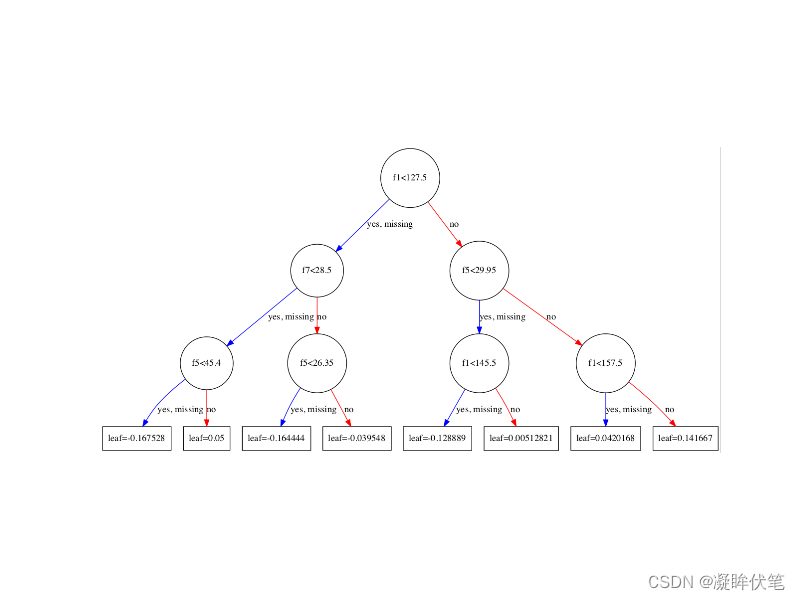
以上两种方式,比较形象的给老板解释了为啥某个特征值改变,会对模型的预测结果产生那么大的影响。大概是因为这个特征位于头部,轻而易举的影响到了最终模型的预测结果。
下一篇,会介绍另一个方法,旨在说明:某一个特征值的变大变小,对模型的影响是正向还是负向。敬请期待~
一个比较好的xgb特征重要度和特征选择的blog:XGBoost学习(六):输出特征重要性以及筛选特征_xgboost的特征重要性-CSDN博客
这篇关于【模型可解释性系列一】树模型-拿到特征重要度-打印关键因素的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









