本文主要是介绍双列集合 Map常见的API Map遍历方式 HashMap LinkedHashMap treeMap,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 双列集合
- 双列集合的特点
- 双列集合体系结构
- Map常见的API
- Map遍历方式
- Map的遍历方式一(键找值)
- 遍历方式二键值对
- 遍历方式三lambda表达式
- HashMap
- 练习1
- 练习二
- LinkedHashMap
- TreeMap
- TreeMap练习1
- 二
- 三
双列集合
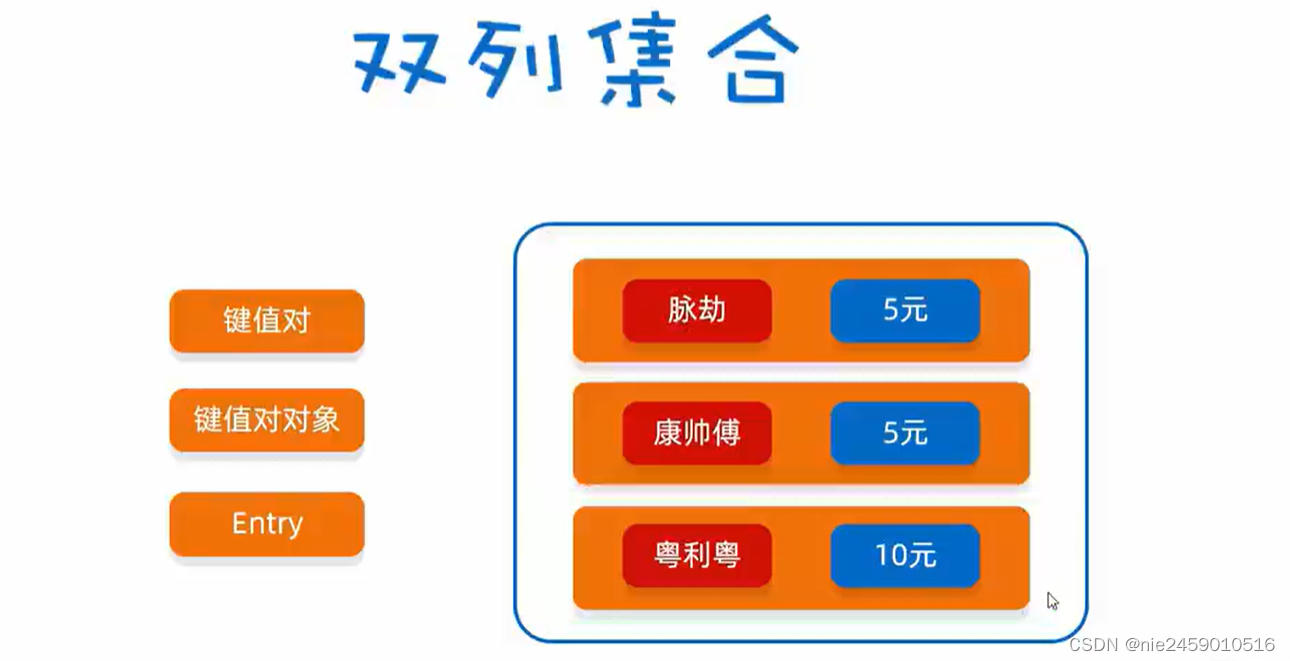
双列集合可以记录两个元素.一个称为键一个称为值.合称为键值对,又叫键值对对象,又叫Entry
双列集合的特点

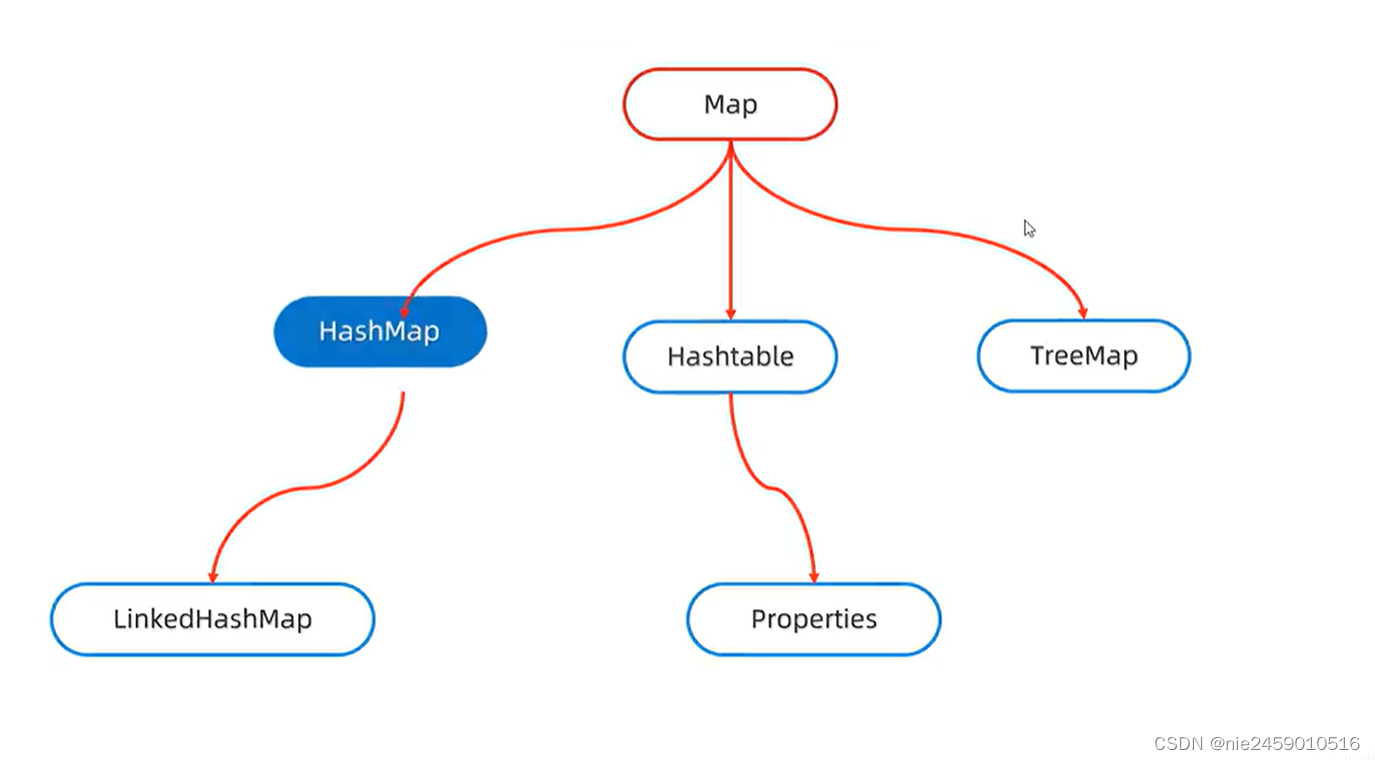
双列集合体系结构
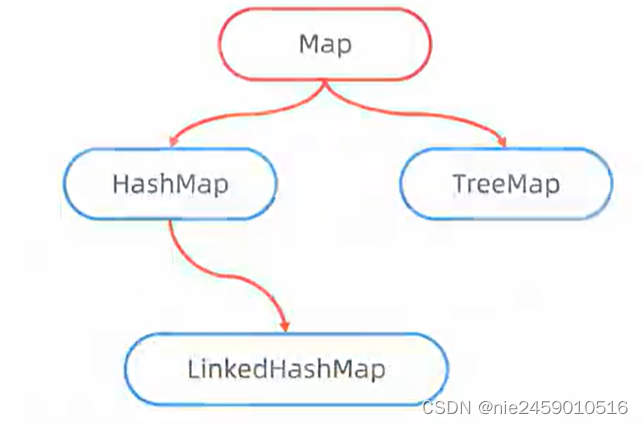
有体系结构知Map是最顶层
Map常见的API
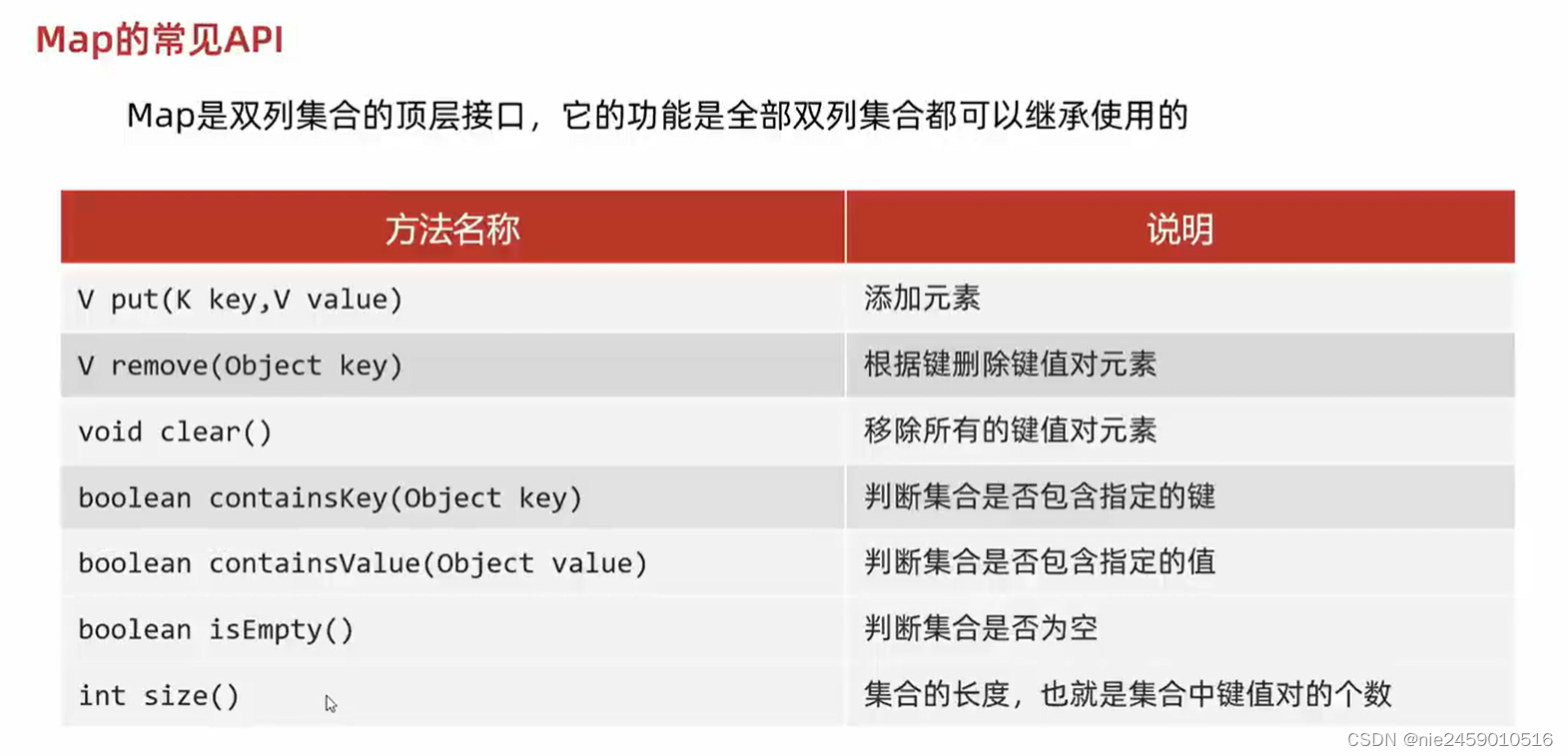
public static void main(String[] args) {//创建map集合Map<String,String>m=new HashMap<>();//添加元素m.put("小诗时","小丹丹");m.put("小帆帆","小丽丽");m.put("张三","小未未");// String s = m.put("小帆帆", "李四");//System.out.println(s);//添加了相同的键//{张三=小未未, 小诗时=小丹丹, 小帆帆=李四}//这里只打印了小帆帆 李四 因为put的底层是在建制存在时 后加的会把原来的覆盖//并且第二个键值对象会返回第一个被覆盖的对象 这里是小丽丽//如果没有被覆盖的键值会返回null//remove根据键值删除对应元素//m.remove("小诗时");//System.out.println(m);//{张三=小未未, 小帆帆=小丽丽}//m.clear();//{}清除所有// m.containsKey判断集合是否包含指定的键boolean b = m.containsKey("小诗时");System.out.println(b);//true//{张三=小未未, 小诗时=小丹丹, 小帆帆=小丽丽}boolean b1 = m.containsValue("小未未");System.out.println(b1);//true//判断集合是否为空boolean b2 = m.isEmpty();System.out.println(b2);//false//判断有几个键值对int size = m.size();System.out.println(size);//3//打印集合System.out.println(m);}
Map遍历方式
Map的遍历方式一(键找值)
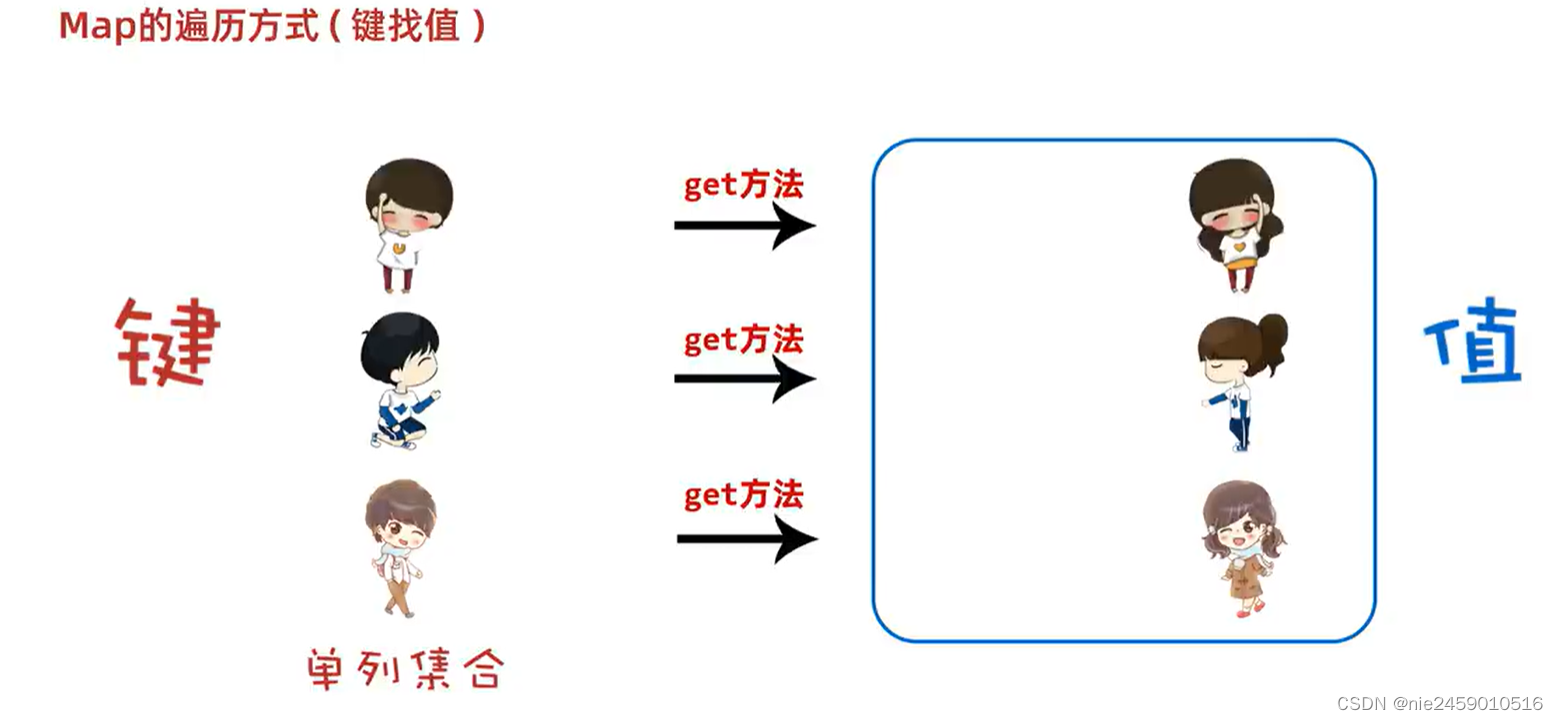
解析:把键和值分开,键放在一个单例集合里遍历然后通过get方法获取值值
public static void main(String[] args) {//Map集合的一种遍历Map<String,String>m=new HashMap<>();m.put("小诗时","小丹丹");m.put("小帆帆","小丽丽");m.put("张三","小未未");//通过键找值Set<String> keys = m.keySet();//这个方法可以理解为将key放到了一个Set集合里// System.out.println(key);//[张三, 小诗时, 小帆帆]//这个就是装着键的单列集合//遍历单列集合,得到每一个键for (String key : keys) {//通过刚刚的map集合传入键,通过键找到值String value = m.get(key);System.out.println(key+"="+value);}//小未未//小丹丹//小丽丽System.out.println("___________________");//迭代器遍历Iterator<String> it = keys.iterator();while(it.hasNext()){String s = it.next();String value2 = m.get(s);System.out.println(value2);}System.out.println("______________");//lambda遍历keys.forEach(new Consumer<String>() {@Overridepublic void accept(String s) {String s3 = m.get(s);System.out.println(s3);}});}
遍历方式二键值对
原理:利用map集合调用方法entrySet()这个方法相当于获取每个键值对对象并存储在一个Set集合里
public static void main(String[] args) {Map<String,String> m=new HashMap<>();m.put("小诗时","小丹丹");m.put("小帆帆","小丽丽");m.put("张三","小未未");Set<Map.Entry<String, String>> entries = m.entrySet();//entries相当于所有键值对对象for (Map.Entry<String, String> entry : entries) {//循环获取每个键值对对象String key = entry.getKey();String value = entry.getValue();System.out.println(key+"="+value);}
//张三=小未未
//小诗时=小丹丹
//小帆帆=小丽丽System.out.println("______________________");//迭代器遍历Iterator<Map.Entry<String, String>> it = entries.iterator();while(it.hasNext()){Map.Entry<String, String> next = it.next();//迭代器获取了每个键值对对象String key1 = next.getKey();String value1 = next.getValue();System.out.println(key1+"="+value1);}System.out.println("______________");//lambda遍历entries.forEach(new Consumer<Map.Entry<String, String>>() {@Overridepublic void accept(Map.Entry<String, String> stringStringEntry) {String key2 = stringStringEntry.getKey();String value2 = stringStringEntry.getValue();System.out.println(key2+"="+value2);}});}
遍历方式三lambda表达式
他的底层是一个增强for就是利用第二种方式调用

public static void main(String[] args) {Map<String,String> m=new HashMap<>();m.put("小诗时","小丹丹");m.put("小帆帆","小丽丽");m.put("张三","小未未");m.forEach(new BiConsumer<String, String>() {@Overridepublic void accept(String key, String value) {System.out.println(key+"="+value);}});//lambdam.forEach((key, value)-> System.out.println(key+"="+value));}
HashMap
他是Map的实现类所以它可以用Map的方法

在底层创建按一个HashMap对象的时候他还是会创建一个默认长度为16加载因子为0.75的数组利用put方法就会创建数据了
put方法底层首先创建一个entry对象,他里面添加的就是键和值,然后利用键 计算键的哈希值,只要键的哈希值即可,然后再计算出再数组中应存入的索引,如果该位置为null直接添加,如果该位置不是null并且已经存入了元素,它会调用equals方法比教键的属性值,如果键比较相同会覆盖原有的,如果比较不一样直接添加元素挂在老元素下形成一条链表.链表长度超过8并且数组长度>=64自动转成红黑树

练习1
需求创建一个集合对象 键是学生对象 值是籍贯
存储三个键值对元素 并遍历
要求同姓名年龄为同一个学生
public static void main(String[] args) {//创建学生对象Student s1=new Student("李磊",18);Student s2=new Student("张三",10);Student s3=new Student("李四",12);Student s4=new Student("李四",12);//Student{name = 李磊, age = 18}=山东//Student{name = 张三, age = 10}=河南//Student{name = 李四, age = 12}=江苏
//打印结果如上 因为重复的被覆盖了//创建集合HashMap<Student,String>hp=new HashMap<>();hp.put(s1,"山东");hp.put(s2,"河南");hp.put(s3,"郑州");hp.put(s4,"江苏");//匿名内部类遍历hp.forEach(new BiConsumer<Student, String>() {@Overridepublic void accept(Student student, String s) {System.out.println(student+"="+s);}});System.out.println("_______________");//键找值遍历Set<Student> keySet = hp.keySet();//获取了键的对象for (Student student : keySet) {//一次遍历获得每个键//通过传入键找到值String value = hp.get(student);System.out.println(student+"="+value);}System.out.println("_______________");//键值对遍历Set<Map.Entry<Student, String>> entries = hp.entrySet();//获取一个键值对for (Map.Entry<Student, String> entry : entries) {//获取每个一次遍历Student key = entry.getKey();String value = entry.getValue();System.out.println(key+"="+value);}}
核心:HashMap的键位置如果是存储自定义学生对象 需要重写hashCode和equals方法
练习二
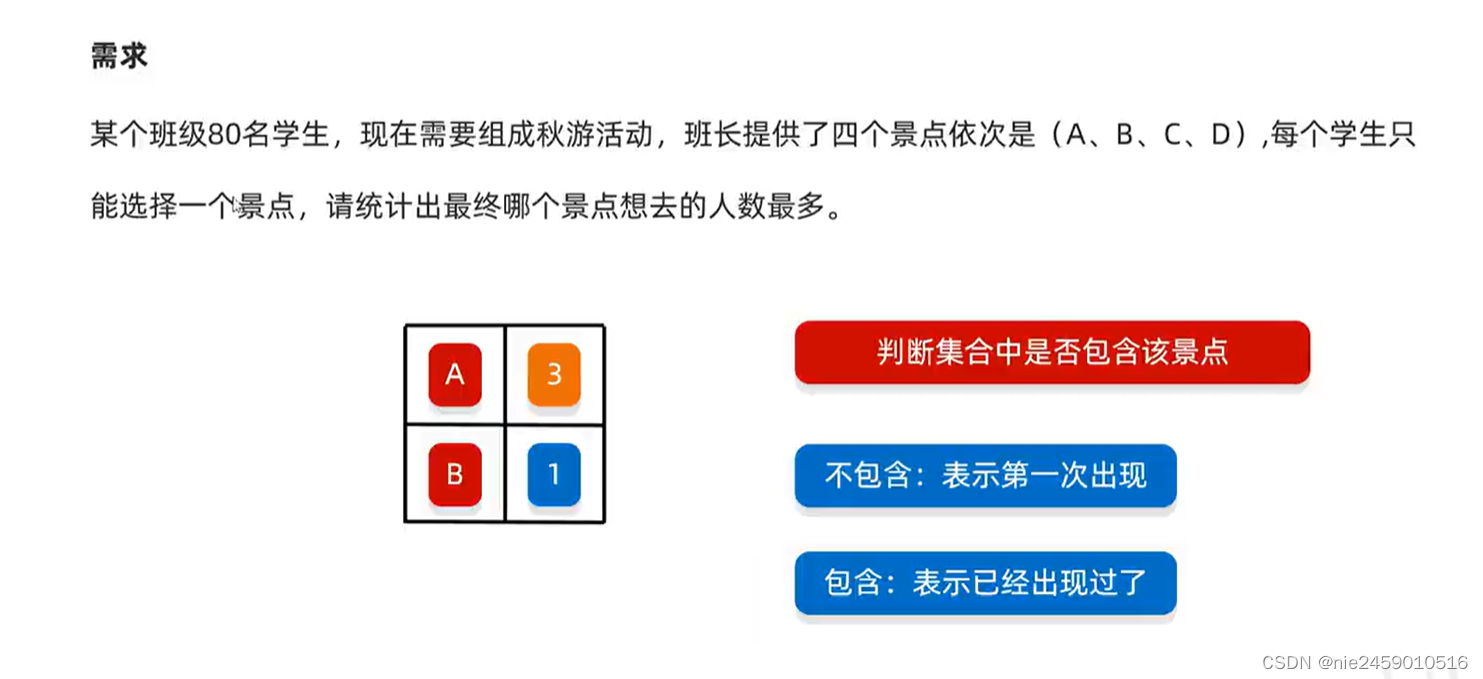
像这种要统计的集合比较多不确定有多少种的时候可以用map集合,这里的景点数量就是个不确定的数
思路 用键存储景点名称值存储景点位置
public static void main(String[] args) {//定义四个景点存储在一个数组内String arr[]={"A","B","C","D"};ArrayList<String>list=new ArrayList<>();//写一个集合模拟80人投票结果Random r=new Random();for (int i = 0; i < 80; i++) {int index = r.nextInt(arr.length);//获取随机索引//System.out.println(arr[index]);//吧随即索引添加列表中存储list.add(arr[index]);}//创建一个hashMap集合 键存储景点 值存储次数HashMap<String,Integer>hp=new HashMap<>();for (String name : list) {//遍历得到每次投票信息 景点名//判断当前景点再map集合是否存在if(hp.containsKey(name)){//存在//先获取当前经典的已有次数Integer value = hp.get(name);value++;//把信息信息传递给maphp.put(name,value);}else{//不存在hp.put(name,1);}}System.out.println(hp);//判断哪个景点想去的人最多int max=0;//解析景点投票可能出现有些经典很多人有些很少但也//会出现有些很多有些是0人//遍历得到每个键值对Set<Map.Entry<String, Integer>> entries = hp.entrySet();for (Map.Entry<String, Integer> entry : entries) {Integer value = entry.getValue();if(value>max){max=value;}}System.out.println(max);for (Map.Entry<String, Integer> entry : entries) {Integer value = entry.getValue();if(value==max){System.out.println(entry.getKey());}}}
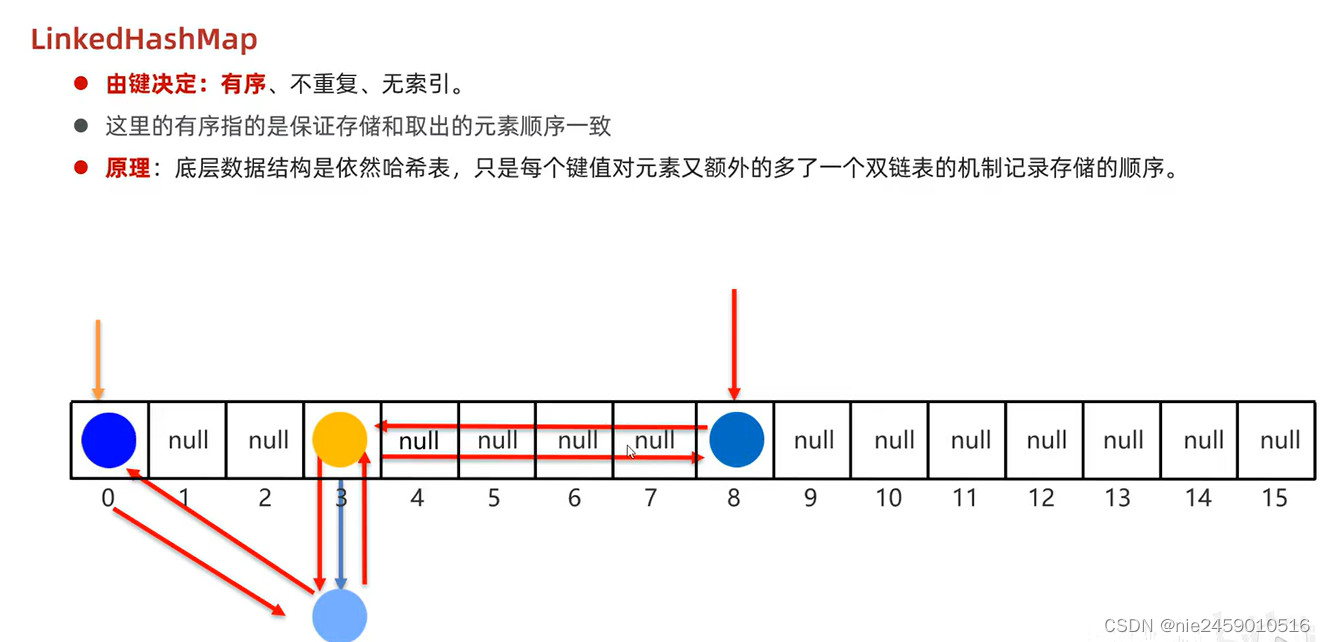
LinkedHashMap
public static void main(String[] args) {LinkedHashMap<String,Integer>lhm=new LinkedHashMap<>();lhm.put("a",123);lhm.put("a",234);lhm.put("b",154);lhm.put("c",123);//{a=234, b=154, c=123} 键不能重复 还会覆盖System.out.println(lhm);}
TreeMap

TreeMap练习1

TreeMap<Integer,String>tm=new TreeMap<>();//默认按照键的排序方式//而Integer排序方式是按照第一种排序方式默认升序tm.put(5,"可乐");tm.put(4,"雪碧");tm.put(3,"冰红茶");tm.put(2,"奶茶");tm.put(1,"香蕉");System.out.println(tm);
如果确实想实现按逆序排列只能采用比较器
TreeMap<Integer,String>tm=new TreeMap<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1;}});//默认按照键的排序方式//而Integer排序方式是默认升序tm.put(5,"可乐");tm.put(4,"雪碧");tm.put(3,"冰红茶");tm.put(2,"奶茶");tm.put(1,"香蕉");System.out.println(tm);//{5=可乐, 4=雪碧, 3=冰红茶, 2=奶茶, 1=香蕉}二
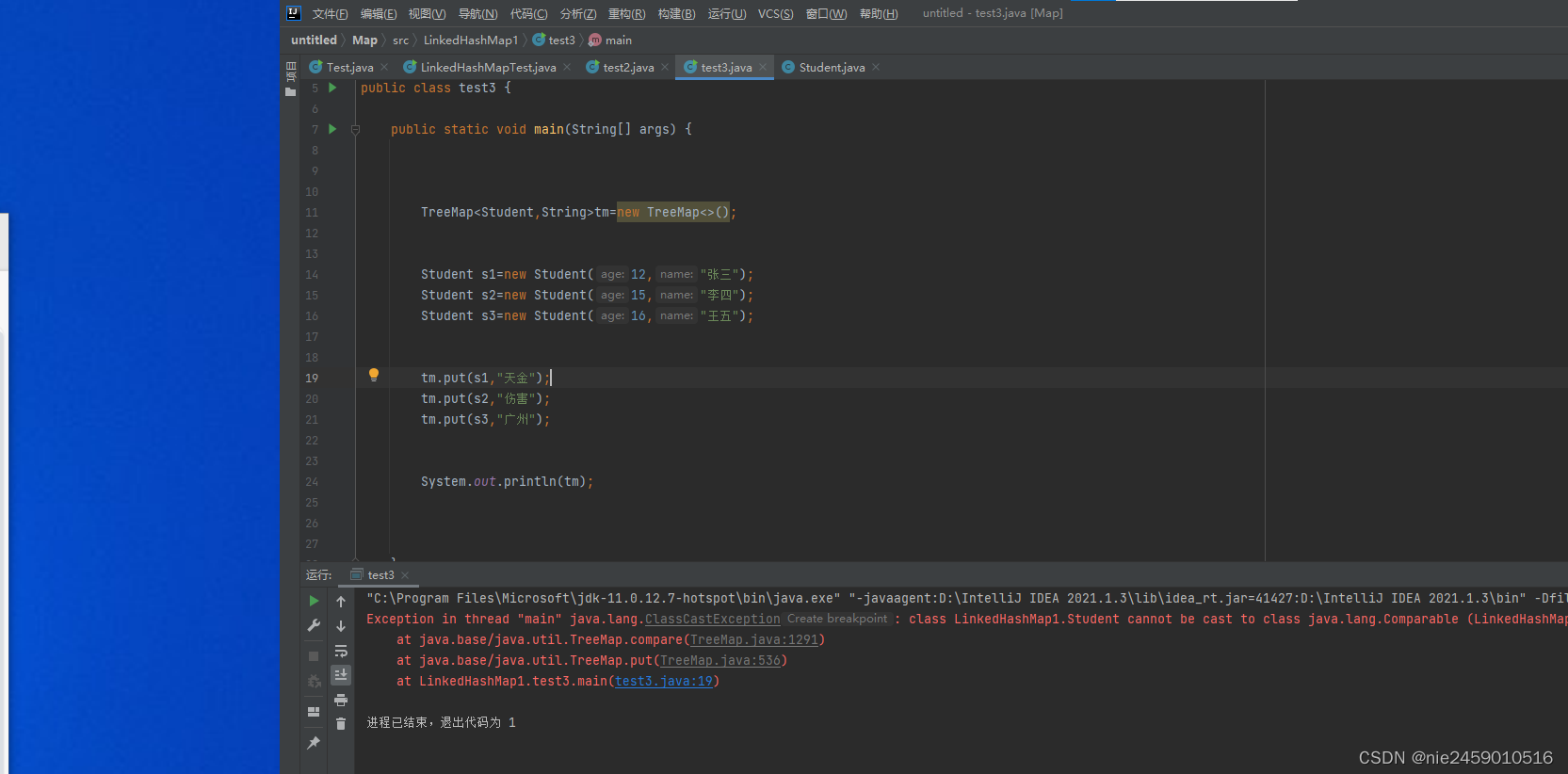
运行报错:是因为自定义对象排序需要指定排序规则
三
遇到这样的题应该如何选择集合
如果题目中没有要求对结果进行排序默认使用HashMap
如题目中要求对结果进行排序 请使用TreeMap
public static void main(String[] args) {//要求利用map集合统计aababcabcdabcde//键表示要统计的内容//值表示次数//:思路先拆分字符串//拿到字符串然后与集合联动 看看再集合中存在否 不存在的话put一个新的存在的话count++TreeMap<Character,Integer>tm=new TreeMap<>();String s="aababcabcdabcde";for (int i = 0; i < s.length(); i++) {char c=s.charAt(i);//取除每一个字符串//把字符串存入集合 如果在集合中已经存在count++次数//如果不存在直接putif(tm.containsKey(c)){//拿出value已有次数int count=tm.get(c);count++;//把自增后的结果添加集合tm.put(c,count);}else{tm.put(c,1);}}System.out.println(tm);//{a=5, b=4, c=3, d=2, e=1}//我们想要的格式为a(5)b(4)....//可以使用StringBuilder拼接StringBuilder sb=new StringBuilder();//打印集合tm.forEach(new BiConsumer<Character, Integer>() {@Overridepublic void accept(Character key, Integer value) {sb.append(key).append("(").append(value).append(")");}});System.out.println(sb);//a(5)b(4)c(3)d(2)e(1)}
这篇关于双列集合 Map常见的API Map遍历方式 HashMap LinkedHashMap treeMap的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







