本文主要是介绍降本提效!阿里提出大模型集成新方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着对大型语言模型(LLM)研究的不断深入,越来越多的工作不再局限于模型本身的性能提升,而是更加关注如何在任务中实现更高效、可靠的性能。即使是通用型的离线 LLM,也在各种领域和任务中具有不同的专业知识,因此,将多个 LLM 集成在一起,能够实现更为一致的性能提升。然而,尽管大多数 LLM 集成方法可以提高性能,但主要都是对模型输出进行奖励排名,这导致了大量计算开销。
来自阿里的研究团队近期提出了一个集成 LLM 的降本增效新方法,具体来说,通过一种奖励引导的路径决策方法 ZOOTER,只需对在特定任务上表现最优越的模型进行推理,而非对所有模型都生成输出,如图 1 所示。为实现这一目标,引入了一个相对较小的路径决策组件,用于确定哪个模型在处理特定任务时具有最专业的知识。这样一来,整个集成的推理成本大幅降低,从而提高了计算效率。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
http://hujiaoai.cn
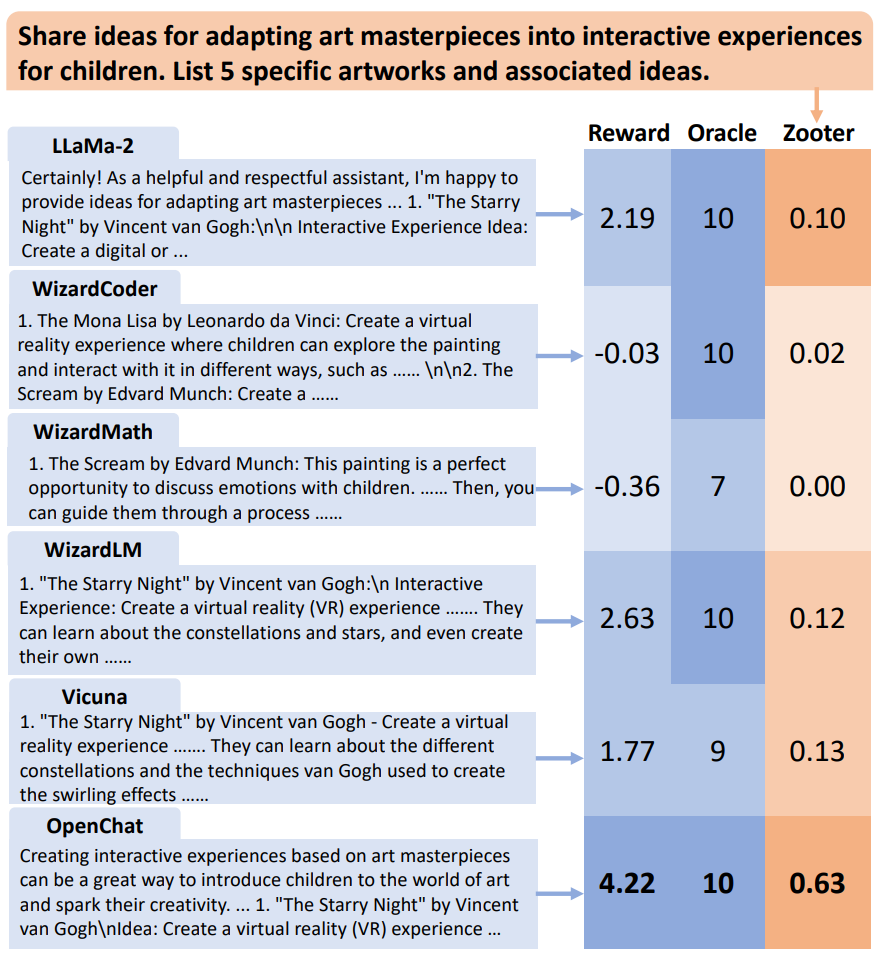
▲图1 LLM 集成的示例
论文题目:
Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models
论文链接:
https://arxiv.org/abs/2311.08692
背景知识
在先前的研究中,LLM 集成的一个挑战就是海量参数带来的计算效率问题,本文所提出的方法在模型推理之前,能够通过训练提问集上的奖励信号(即模型在特定任务或领域上的专业知识),对模型进行训练。这样,模型在推理阶段就能够直接利用先前获得的专业知识,从而避免在每次推理中都需要生成大量输出的非必要开销。
奖励模型排名
奖励模型源于强化学习中的奖励函数,可以依据当前的状态得到一个分数,来说明该状态产生多少价值。LLM 可以构建奖励模型来对问答对作出得分评价。在 LLM 微调中的奖励模型是对输入的提问和回答计算出一个分数。输入的回答与提问匹配度越高,则奖励模型输出的分数也就越高。
奖励模型排名(Reward Model Ranking, RMR)是一种用于 LLM 集成的方法,其目的是利用不同模型的输出,通过奖励模型的反馈来确定最适合特定任务的模型。在这里,奖励模型被用来对模型的生成结果进行评估和排名,以确定哪个模型在特定任务或领域中表现最好。通过找到一个奖励函数 来估计真实偏好 ,以便为每个提问找到最佳模型。
提问路由
提问路由的目标是找到一个路由函数 ,对于提问集 中的每个 ,该函数能够确定最适合处理该提问的模型 。如果不同的 LLM 在不同领域和任务中具有专业知识,路由函数将能够预测提问属于 LLM 专业知识的概率。与现有的 RMR 方法相比,提问路由函数缓解了计算效率问题。路由函数通过分析每个提问的属性,尝试为其分配最适合的特定领域或任务的模型,从而在整个集成过程中提高效率。
ZOOTER 方法
ZOOTER 通过学习奖励模型排名,从而解释每个模型的潜在专业知识。如图 2 所示,ZOOTER 首先对包含多种提问的训练集进行推断,以生成每个候选 LLM 的回复。接着,通过现有的奖励模型对这些回复进行单一数值的奖励,如图 2 中的蓝色虚线所示。为了进行平滑和去噪,奖励首先通过基于标签的先验进行增强。然后,标准化的奖励分布被用作在路由函数的知识蒸馏训练中的监督,如图 2 中的绿色虚线所示。在推断过程中,路由函数对输入提问进行分类,并将其分配到在该提问上具有最强专业知识潜力的 LLM。最终,由该 LLM 生成专业的回复。
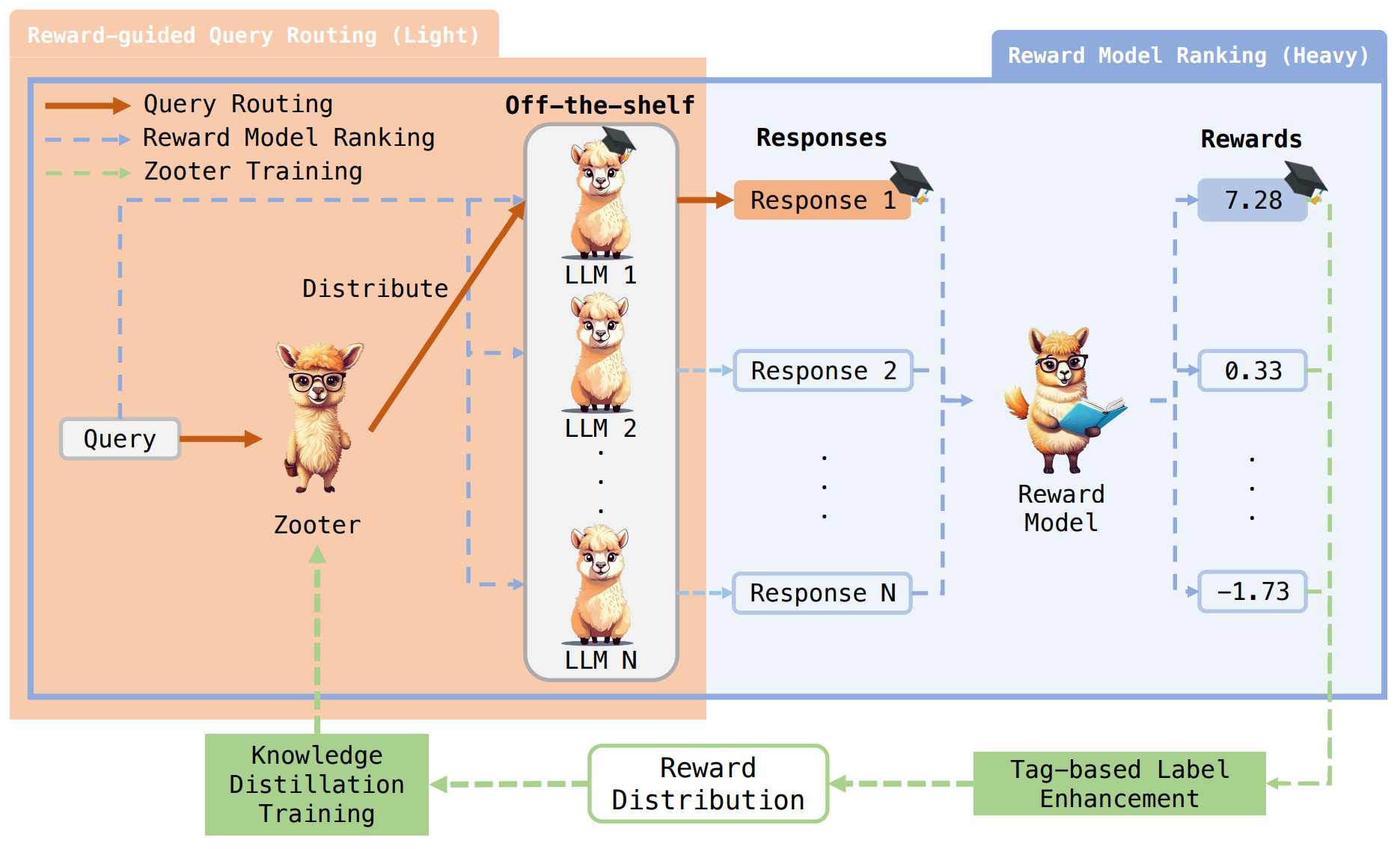
▲图2 ZOOTER 的概述
奖励蒸馏
为了估计每个模型的专业知识并训练路由函数,我们需要在一个多样化的训练集 上应用奖励偏好排名。首先在每个提问 上推断所有候选模型,然后通过一个现成的奖励模型为每个提问和模型分配奖励:
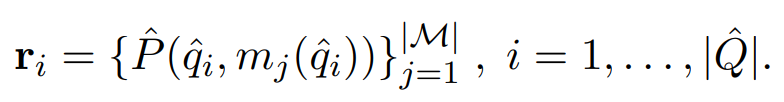
然后,通过知识蒸馏使用 KL 散度作为损失函数,在训练集上训练路由器函数 :
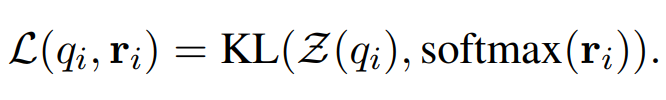
此蒸馏过程有助于 ZOOTER 学习每个模型的潜在专业知识。
基于标签(Tag)的标签(Label)增强
作者还指出,语言奖励模型提供的奖励具有不确定性,可能引入噪音。
在这里,标签是指对提问的一种附加信息或标注,可以帮助更精确地指导模型在特定任务或领域的表现。通过引入与提问相关的标签信息,尤其是在奖励不确定性的情况下,提高奖励模型的鲁棒性和性能。
具体来说,该方法使用本地标签器对每个提问进行标记来生成标签集。然后,将具有相同标签的提问上的奖励进行聚合,生成 “tag-wise 奖励”。最后,通过线性组合将 tag-wise 奖励与原始奖励结合,用于在路由函数的训练中,以更有效地挖掘潜在的模型专业知识。
实验
综合比较
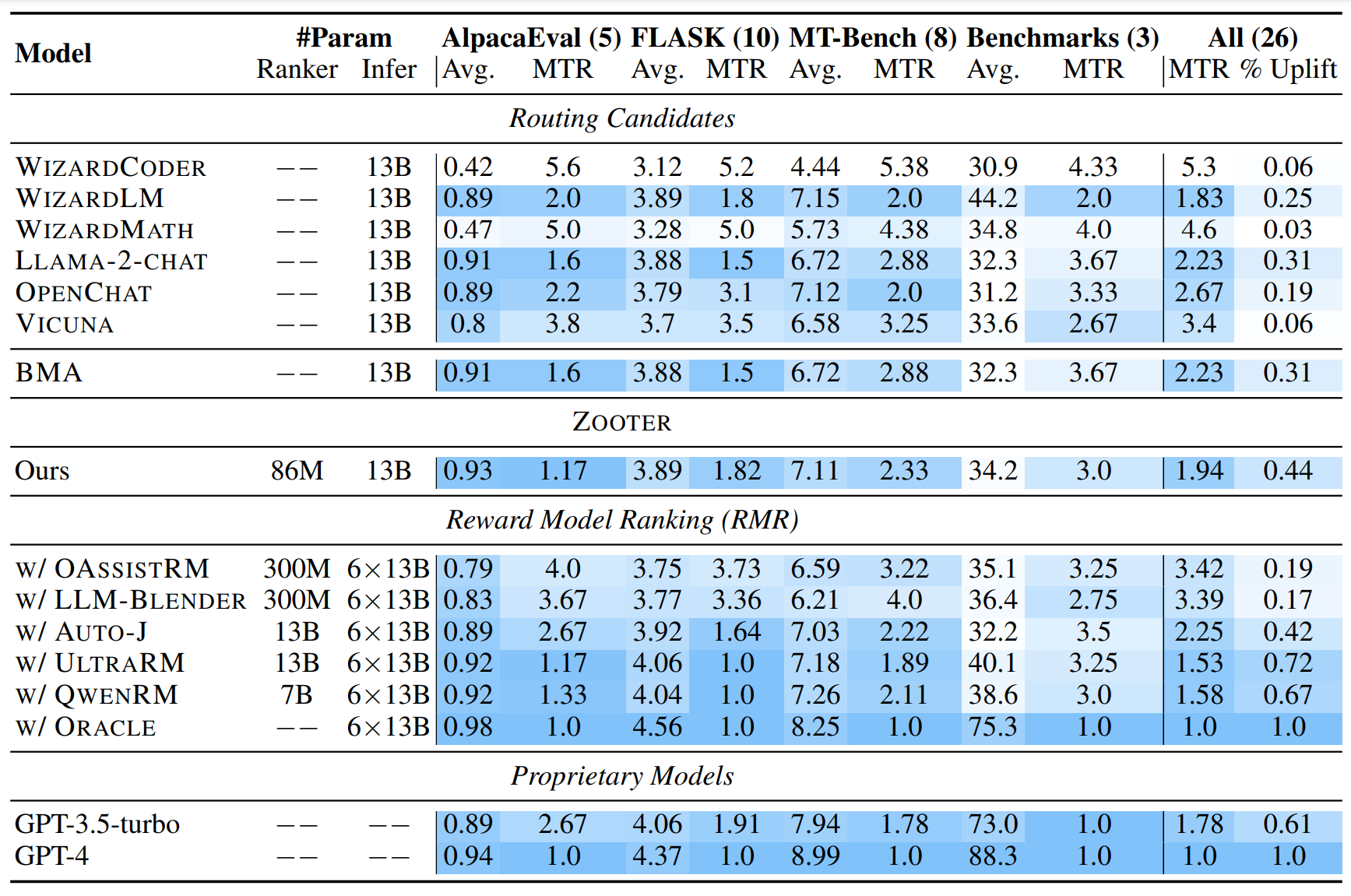
▲表1 ZOOTER 和奖励模型排名的主要结果
在表 1 中,作者展示了 ZOOTER 和奖励模型排名的主要实验结果,主要包括跨四组基准的六个候选路由的性能。ZOOTER 在平均水平上表现优越,超越了最佳单一模型,甚至在与奖励模型排名集成相比也取得了更好的性能,并且其计算开销明显较小。
LLM 存在互补的潜力:实验结果有力地支持了奖励模型之间存在互补潜力的观点,同时也验证了 ZOOTER 通过使用现成奖励模型进行路由函数训练,可实现更为有效的模型集成。然而,需要注意的是,RMR 方法在 MMLU、GSM8K 和 HumanEval 等基准上的失败,对于知识、数学和编程问题的精确判断仍然具有挑战性。
奖励模型不确定性如何影响 ZOOTER 的训练
作者注意到奖励模型可能存在不确定性,由于使用奖励模型分数作为标准来训练路由函数,这种不确定性会引入噪音。因此通过计算在 MT-Bench 中每个提问在 QwenRM 中所有候选 LLM 的奖励熵来展示了这种不确定性的存在,如图 3 所示,图中显示了奖励熵较低的样本倾向于具有较高的 MT-Bench 得分。作者将这一结果解释为较高的奖励熵表示奖励中的不确定性更大。由此引入了标签增强,以利用基于标签的先验来调整奖励熵。
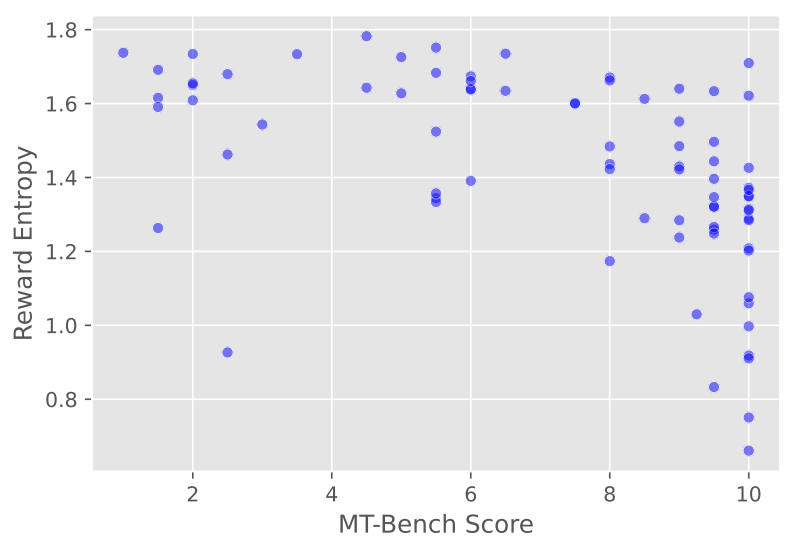
▲图3 奖励熵与 MT-bench 上奖励偏好排名得分之间的分析
在标签增强中有一个超参数 ,代表了样本级奖励和标签级奖励之间的权衡。如表 2 所示,我们发现当 等于 0.3 时,ZOOTER 性能最佳,这证明了样本级和标签级奖励的组合对奖励蒸馏是有益的。消融实验进一步显示了基于标签的标签增强的必要性。
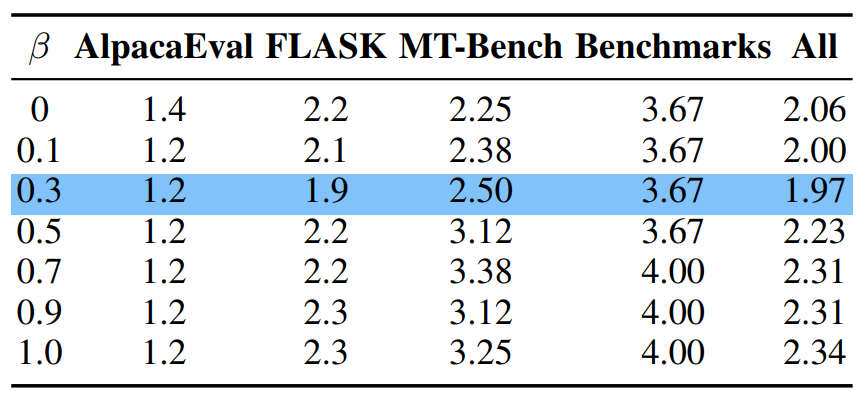
▲表2 在所有基准上使用不同 值的标签增强的平均任务率(MTR)
总结
本文通过实验证明了,所提出的 ZOOTER 方法在平均水平上超越了最佳单一模型,甚至可以胜过通过奖励模型排名集成的模型,并且有着明显较小的计算开销。在如今追求高效、节能的时代,本文的方法为我们开辟了一个新的探索方向,探讨如何更有效地集成 LLM,为解决高计算开销问题提供了一种创新性的解决方案。

这篇关于降本提效!阿里提出大模型集成新方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





