本文主要是介绍第三节:提供者、消费者、Eureka,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 提供者 消费者(就是个说法、定义,以防别人叭叭时听不懂)
- 服务提供者:业务中被其他微服务调用的服务。(提供接口给其他服务调用)
- 服务消费者:业务中调用其他微服务的服务。(调用其他微服务提供的接口)
其实这个这两个名词在生活中处处可见
二、使用情景
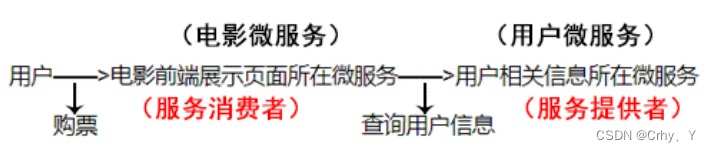
下图中相对于用户来说,那么电影微服务也就变成了服务提供者😀
三、Eureka分析
3.1 Eureka
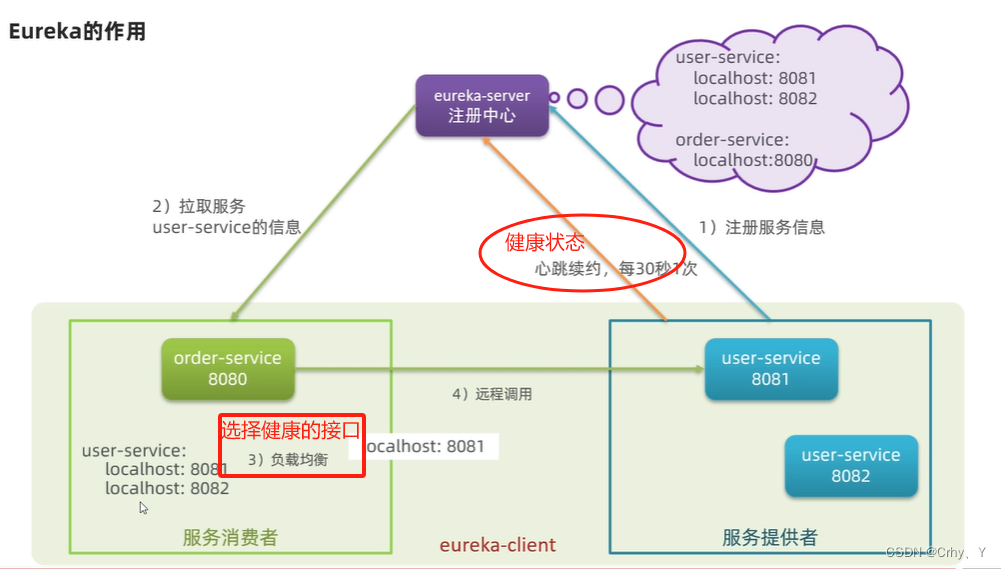
- 服务消费者如何获取服务提供者的地址信息?
- (1)服务提供者启动时会注册自己的信息
- (2)eureka负责保存,消费者根据服务名称去往eureka拉取自己所需的信息
- 如果有多个服务提供者,消费者如何选择?(集群部署时,如何用)
- (1)消费者会用到负载均衡算法,自己选择
- 消费者如何得知服务提供者的健康状态?(某个服务器上的 服务/接口 挂了如何判断,如何处理)
- (1)心跳检测,报告健康状态
- (2)eureka自动更新服务列表状态,剔除不正常提供者
- (3)消费者每次拉取时都会取到最新的信息
3.1.1 关系流程
这篇关于第三节:提供者、消费者、Eureka的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!