本文主要是介绍使用Selenium模拟登录xx小说网后获取相关数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用selenium对模拟登录获取内部数据
要求:
对网站模拟登录后,获取内部书单数据
网站:
import base64
# 解码
website = base64.b64decode('aHR0cHM6Ly93d3cuMTdrLmNvbS8='.encode('utf-8'))
print(website)
前置知识点:
高级xpath:
在XPath语法中,可以使用以下方式表示最后一个标签和第一个标签:
- 最后一个标签:使用
last()函数来表示最后一个标签。例如,//tag[last()]表示选择文档中所有tag标签中的最后一个标签。 - 第一个标签:使用索引值
[1]来表示第一个标签。例如,//tag[1]表示选择文档中所有tag标签中的第一个标签。 - 倒数第一个标签:使用索引值
last()-1来表示倒数第一个标签。例如,//tag[last()-1]表示选择文档中所有tag标签中的倒数第一个标签。 - 根据位置选择标签:可以使用位置谓词来选择具体位置的标签。位置谓词使用方括号
[position()]来表示。例如,//tag[position()=3]表示选择文档中所有tag标签中的第三个标签。 - 第一个匹配的标签:使用
[1]来表示第一个匹配到的标签。例如,//tag[@attribute='value'][1]表示选择具有指定属性值的tag标签中的第一个匹配到的标签。 - 逻辑运算符:XPath支持逻辑运算符,如
and、or和not,可以用于组合多个条件来选择标签。例如,//tag[@attribute='value' and @attribute2='value2']表示选择具有指定属性值和属性2值的tag标签。 - 属性选择:可以使用
@符号来选择具有特定属性的标签。例如,//tag[@attribute='value']表示选择具有指定属性值的tag标签。
请注意,XPath中的索引从1开始计数,而不是从0开始计数。
切换页面:
当使用switch_to.frame()方法切换到iframe时,参数可以是以下几种形式之一:
- 通过索引:可以使用iframe在页面中的索引来切换到特定的iframe。索引从0开始,表示第一个iframe。例如,
switch_to.frame(0)表示切换到第一个iframe。
driver.switch_to.frame(0)
2.通过名称或ID:如果iframe具有名称或ID属性,可以通过名称或ID来切换到该iframe。可以将名称或ID作为字符串传递给switch_to.frame()方法。例如,switch_to.frame("myframe")表示切换到名称或ID为"myframe"的iframe。
driver.switch_to.frame("myframe")
3.通过WebElement:可以将表示iframe的WebElement对象作为参数传递给switch_to.frame()方法。如果已经定位到iframe的WebElement对象,可以直接使用该对象来切换到该iframe。
iframe_element = driver.find_element_by_id("iframe_id")
driver.switch_to.frame(iframe_element)
使用哪种参数形式取决于你在自动化测试中的具体情况。如果iframe有唯一的名称或ID,最好使用名称或ID来切换到iframe。如果存在多个iframe并且可以根据其在页面中的位置来区分,可以使用索引来切换到特定的iframe。如果已经通过其他方式定位到了iframe的WebElement对象,可以直接使用该对象来切换到iframe。
思路:

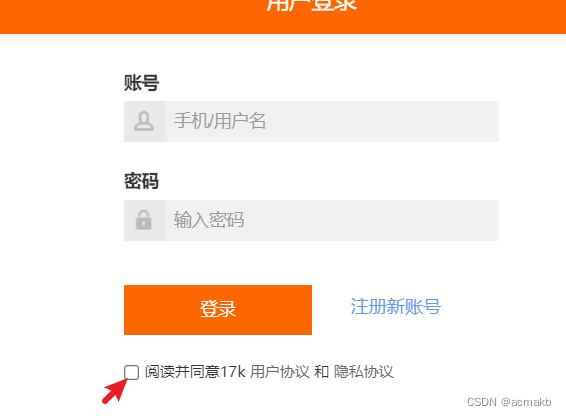
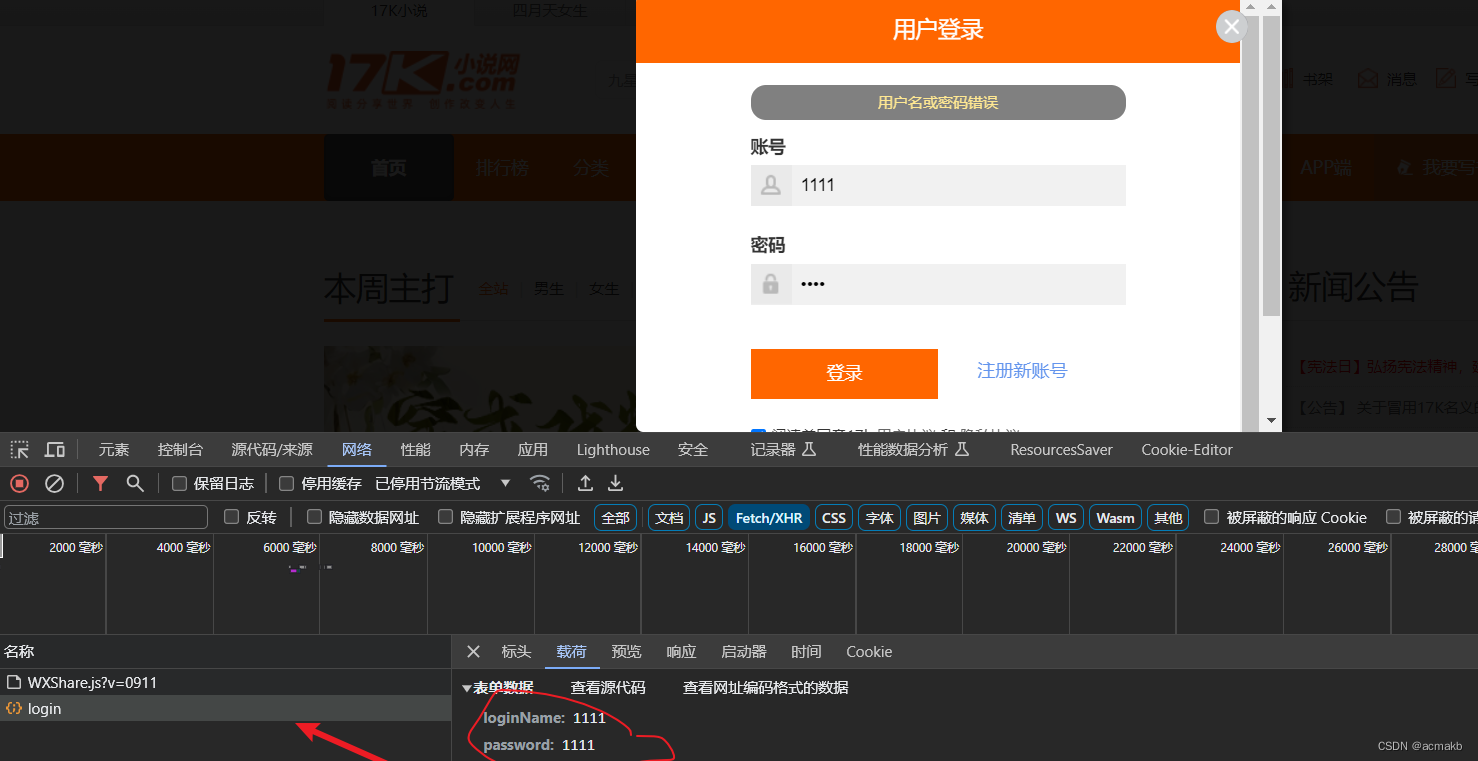
我们可以发现这个网页的登录页面是明文数据提交,没有涉及加密算法,但是需要我们点击一下按钮,等一些操作。
- 首先,需要点击登录按钮
- 找到账号框,输入账号
- 找到密码框,输入密码
- 点击同意协议
- 点击登录按钮

登录按钮的xpath:
//*[@id="header_login_user"]/a[1]

注意需要切换页面,切换到iframe里面
/html/body/div[21]/div/div[1]/iframe
iframe = web.find_element_by_xpath('/html/body/div[21]/div/div[1]/iframe')
web.switch_to.frame(iframe)
账号框:
/html/body/form/dl/dd[2]/input

很多同学,到这里有疑问,为什么你得右侧没有定位到标签,你的xpath是不是写错了?
这里讲一下,因为这个属于后来弹出的页面,xpath_helper只能应对非动态页面。如何应对呢,自己检查呗,xpath的语法就是标签嵌套关系而已。
密码框:
/html/body/form/dl/dd[3]/input

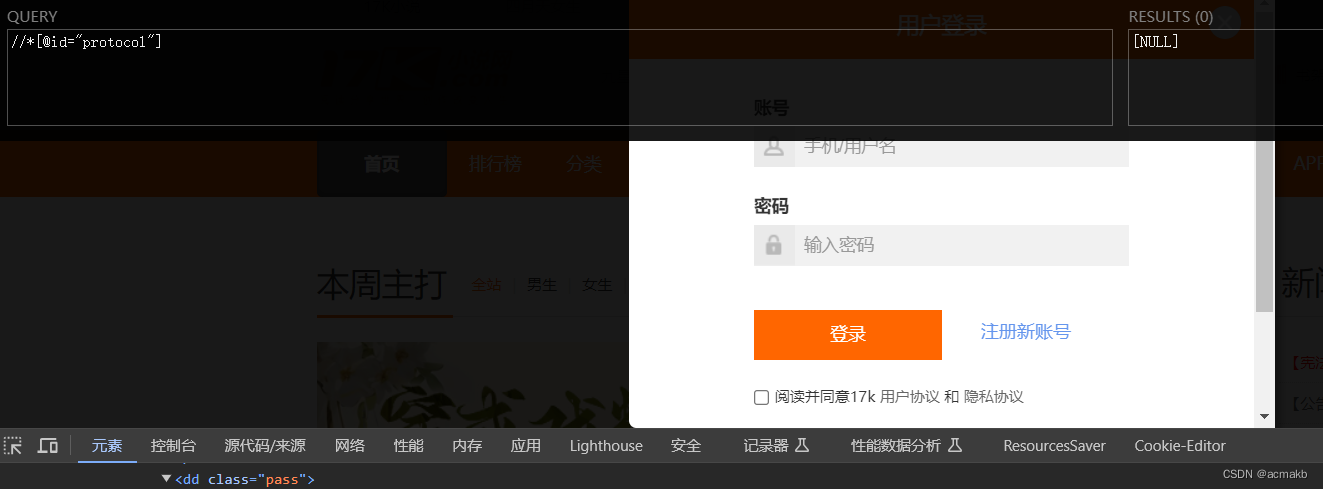
同意框:
//*[@id="protocol"]
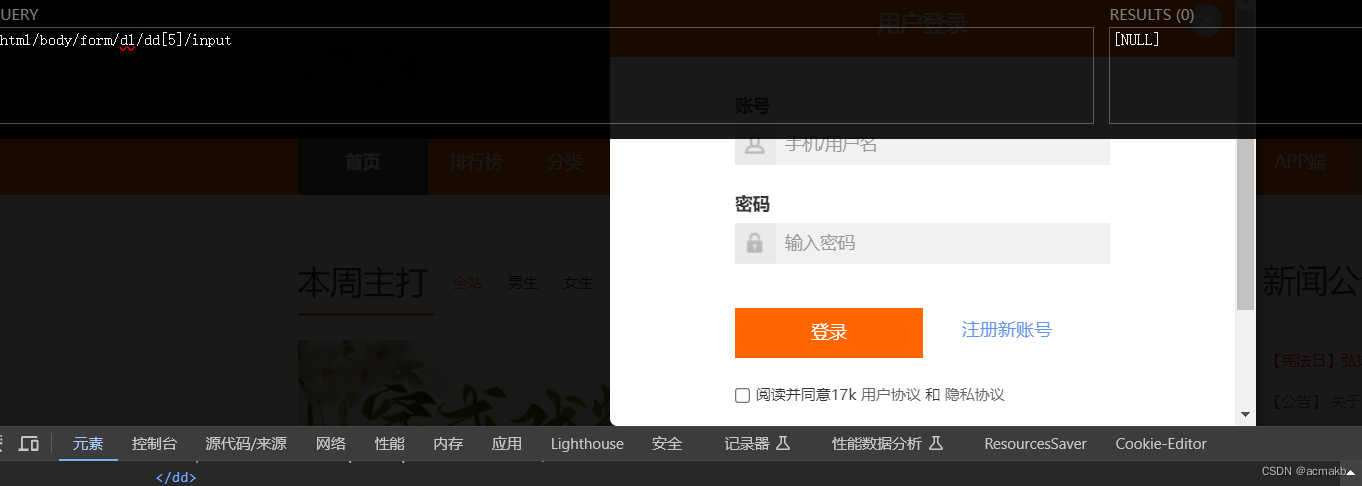
登录按钮:
/html/body/form/dl/dd[5]/input
from selenium.webdriver import Chrome
import time
import json
import requests
path = r'D:\Downloads\xx\chromedriver-win64\chromedriver.exe'
web = Chrome(executable_path=path)
web.get('https://www.17k.com/')
time.sleep(3)
# 登录
web.find_element_by_xpath('//*[@id="header_login_user"]/a[1]').click()# 切换iframe
# /html/body/div[20]/div/div[1]/iframe
iframe = web.find_element_by_xpath('/html/body/div[last()]/div/div[1]/iframe')
print(iframe)
web.switch_to.frame(iframe)
# 得到输入框 输入账号
web.find_element_by_xpath('/html/body/form/dl/dd[2]/input').send_keys("your name")
web.find_element_by_xpath('/html/body/form/dl/dd[3]/input').send_keys("your miam")
web.find_element_by_xpath('//*[@id="protocol"]').click()
web.find_element_by_xpath('/html/body/form/dl/dd[5]/input').click()time.sleep(3)
cookies = web.get_cookies()
同时,我们将cookies写到一个文件中:
# 存文件里
with open("cookies.txt", mode="w+", encoding='utf-8') as f:f.write(json.dumps(cookies)) # cookies是一个列表套字典 需要进行序列化转为字符串
封装cookie键值对形式:
dic = {}
for cook in cookies:dic[cook['name']] = cook['value']
发送请求得到书架信息,
url = "https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919"
headers = {'cookie': dic
}
resp = requests.get(url, cookies=dic)
print(resp.json())
print(resp.encoding)web.close()

成功!!!
完整代码:
from selenium.webdriver import Chrome
import time
import json
import requests
path = r'D:\Downloads\xx\chromedriver-win64\chromedriver.exe'
web = Chrome(executable_path=path)
web.get('https://www.17k.com/')
time.sleep(3)
# 登录
web.find_element_by_xpath('//*[@id="header_login_user"]/a[1]').click()# 切换iframe
# /html/body/div[20]/div/div[1]/iframe
iframe = web.find_element_by_xpath('/html/body/div[last()]/div/div[1]/iframe')
print(iframe)
web.switch_to.frame(iframe)
# 得到输入框 输入账号
web.find_element_by_xpath('/html/body/form/dl/dd[2]/input').send_keys("username")
web.find_element_by_xpath('/html/body/form/dl/dd[3]/input').send_keys("xxxxx")
web.find_element_by_xpath('//*[@id="protocol"]').click()
web.find_element_by_xpath('/html/body/form/dl/dd[5]/input').click()time.sleep(3)
cookies = web.get_cookies()
#
# 存文件里
with open("cookies.txt", mode="w+", encoding='utf-8') as f:f.write(json.dumps(cookies))# 组装cookie字典, 直接给requests用
dic = {}
for cook in cookies:dic[cook['name']] = cook['value']
# 衔接. 把cookie直接怼进去# cookie 必须是一个字典 需要进行反序列化操作
# 访问的书架(获取书架内容)
url = "https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919"
headers = {'cookie': dic
}
resp = requests.get(url, cookies=dic)
print(resp.json())
print(resp.encoding)web.close()温馨提示:
仅供学习参考,请勿用于数据获取
本案例仅旨在展示模拟技术的应用和原理,并提供学习参考。请注意,未经授权的数据获取可能涉及法律和道德问题。在进行任何数据获取活动之前,请确保遵守相关法律法规和网站的规定。
这篇关于使用Selenium模拟登录xx小说网后获取相关数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




