小说网专题

打卡学习Python爬虫第六天|处理cookie登录小说网
引言:一些网站不需要登录就能看到信息,但对于需要登录才能看见信息的网站,我们就需要借助cookie,使爬虫能够顺利登录网站,从而获取所需数据。 1、登录后查看页面源代码 并没有我们需要的数据 2、利用抓包工具 右键-->检查或者直接按F12,进入开发者页面,找到数据,拿到其url 3、编写程序 # 1、登录 --> 得到cookie# 2、访问 --> 带cookie访

python爬取飞卢小说网免费小说
python爬取飞卢小说网免费小说 一、爬取流程介绍二、完整代码 一、爬取流程介绍 首先看一下我们需要爬取的飞卢小说网的免费小说《全民:开局邀请光头强挑战只狼》网址,如下图所示: 点击第一章,按F12键打开浏览器开发者工具,再点击开发者工具左上角的小箭头,找到小说内容在网页中所在的位置,如下图所示: 可以看到,在具体的章节中,小说内容均在一个class="noveConten

多线程爬取书趣阁小说网小说
多线程爬取书趣阁小说网小说 一、爬取流程分析二、完整代码 一、爬取流程分析 如下图所示,以书趣阁小说网的其中一篇小说《斗破之无上之境》为例,目标是爬取该小说的所有章节内容,并把内容存储到一个txt文件中。 首先,打开浏览器的开发者工具,刷新页面进行抓包,抓到了如下数据包: 我们需要的数据是每个章节的名称和详情页url,可以发现数据均在第一个数据包中(40247/)。接下来,使

爱看小说网源码全站带数据打包ThinkPHP内核小说网站源码
☑️ 编号:ym328 ☑️ 品牌:无 ☑️ 语言:php ☑️ 大小:352MB ☑️ 类型:爱看小说网源码 ☑️ 支持:PC+wap 🎉 欢迎关注,私信,领取 🎉 ✨ 源码介绍 爱看小说网源码全站带数据打包,ThinkPHP内核小说网站源码。本次给大家带来的是价值500元的狂雨小说二开版,全站采集了2w多本,数据库有点大,300多M。 💡免责声明:根据二○一三年一月三十日《计算机软
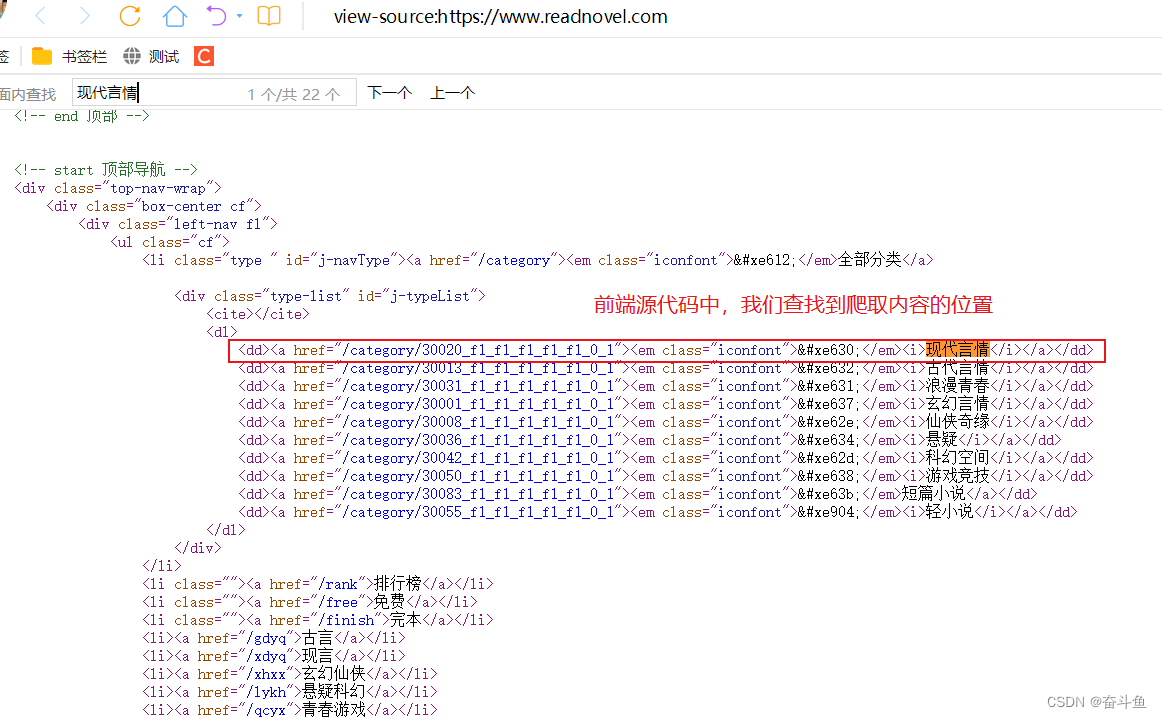
python:最简单爬虫之爬取小说网Hello wrold
以下用最简单的示例来演示爬取某小说网的类目名称。 新建一个retest.py,全文代码如下,读者可以复制后直接运行。代码中我尽量添加了一些注释便于理解。 需要说明的一点,该小说网站如果后续更新改版了,文中截取字符的正则表达式可能需要根据做一些变动,才能成功爬取到我们想要的名称。 一、小说网站首页 我们想爬取的是首页-》全部分类 菜单下的小说分类名称 二、retest.py代码 #
python:最简单爬虫之爬取小说网Hello wrold
以下用最简单的示例来演示爬取某小说网的类目名称。 新建一个retest.py,全文代码如下,读者可以复制后直接运行。代码中我尽量添加了一些注释便于理解。 需要说明的一点,该小说网站如果后续更新改版了,文中截取字符的正则表达式可能需要根据做一些变动,才能成功爬取到我们想要的名称。 一、小说网站首页 我们想爬取的是首页-》全部分类 菜单下的小说分类名称 二、retest.py代码 #

使用Selenium模拟登录xx小说网后获取相关数据
使用selenium对模拟登录获取内部数据 要求: 对网站模拟登录后,获取内部书单数据 网站: import base64# 解码website = base64.b64decode('aHR0cHM6Ly93d3cuMTdrLmNvbS8='.encode('utf-8'))print(website) 前置知识点: 高级xpath: 在XPath语法中,可以使用以下方
使用Selenium模拟登录xx小说网后获取相关数据
使用selenium对模拟登录获取内部数据 要求: 对网站模拟登录后,获取内部书单数据 网站: import base64# 解码website = base64.b64decode('aHR0cHM6Ly93d3cuMTdrLmNvbS8='.encode('utf-8'))print(website) 前置知识点: 高级xpath: 在XPath语法中,可以使用以下方